DeepSeek OCR: Ein Praxisleitfaden zu ihrer Kontextkomprimierungstechnologie (2025)
Zuletzt aktualisiert: 2026-01-22 18:05:30

Letzte Aktualisierung: 22. Oktober 2025
Wenn Sie die jüngsten Entwicklungen im Bereich KI verfolgt haben, haben Sie vermutlich von DeepSeeks neuem OCR-System gehört. Was meine Aufmerksamkeit erregte, war nicht nur ein weiteres „Wir können Text aus Bildern lesen“, sondern wie sie ein echtes und teures Problem angingen: das Verarbeiten langer Dokumente, ohne dabei Ihr Token-Budget zu sprengen.
Dieser Leitfaden erklärt, was DeepSeek OCR anders macht, wie es funktioniert und ob es sich für Ihre Projekte lohnt.
Inhaltsverzeichnis
- Was macht DeepSeek OCR anders?(#what-makes-it-different)
- Der Durchbruch bei der Kontextkomprimierung(#context-compression)
- Wie es tatsächlich funktioniert(#how-it-works)
- Was Sie damit machen können(#capabilities)
- Erste Schritte(#getting-started)
- Leistung in der Praxis(#performance)
- Wann Sie das nutzen sollten im Vergleich zu herkömmlicher OCR?(#comparison)
- Praktische Anwendungen(#applications)
- Tipps und Best Practices(#tips)
- Einschränkungen, die Sie kennen sollten(#limitations)
- Häufige Fragen(#faq)
1. Was macht DeepSeek OCR anders?
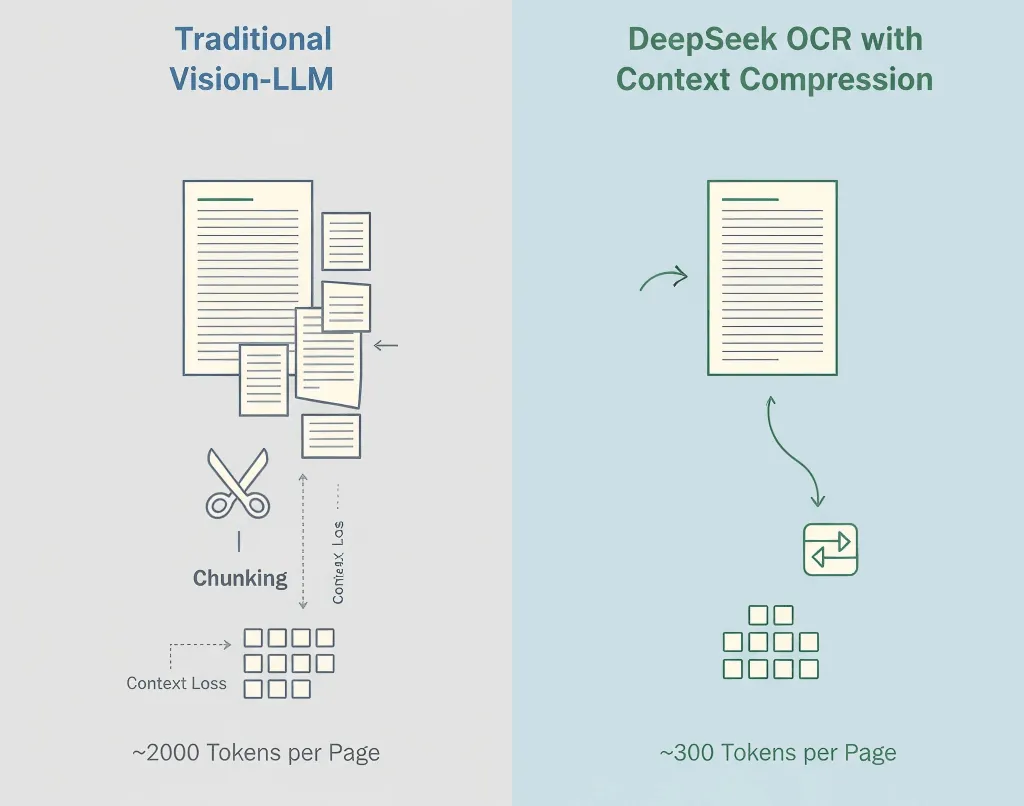
OCR selbst ist nichts Neues Tools wie Tesseract, Google Vision und AWS Textract gibt es schon seit Jahren. Sie alle extrahieren Text problemlos.
Der eigentliche Flaschenhals zeigt sich, wenn Sie möchten, dass ein KI-Modell das Dokument versteht – und es nicht nur transkribiert.
Das Token-Problem
Das Einspeisen von rohen OCR-Ergebnissen in ein großes Sprachmodell ist ineffizient.
Stellen Sie sich einen 50-seitigen Vertrag vor:
- Sie extrahieren den Text
- Versuchen, ihn an ein LLM zu senden
- Sie stoßen nach drei Seiten auf das Kontextlimit
- Sie beginnen, zu stückeln, zusammenzufassen und verlieren Kontext
Das ist frustrierend, und ich habe dafür schon Stunden verschwendet.
DeepSeeks Lösung
DeepSeek behandelt OCR und Verständnis nicht als getrennte Schritte. Ihr System erledigt OCR und semantische Komprimierung gemeinsam.
Anstatt rohen Text auszugeben, kodiert DeepSeek OCR Bedeutung und Layout in kompakter Form und reduziert so den Tokenverbrauch um das 5–10-Fache.
Ein 50-seitiger Vertrag, der früher 100.000 Tokens benötigte, passt nun vielleicht in 12.000–15.000.
Warum das wichtig ist:
- Geringere Kosten (weniger Tokens = günstigere Inferenz)
- Einfacherer Workflow (keine manuelle Aufteilung)
- Besserer Kontext (das Modell sieht das gesamte Dokument)
- Schnellere Verarbeitung (ein API-Aufruf statt dutzender)
2. Der Durchbruch bei der Kontextkomprimierung
Traditionelle Vision-Language-Modelle machen aus jedem Bildabschnitt Tokens, oft 1.500–2.500 pro Seite. Die meisten dieser Tokens repräsentieren Pixel, nicht Bedeutung.
Die Methode von DeepSeek
- OCR zuerst – extrahiert Text, Layout und Tabellen
- Semantische Komprimierung – wandelt erkannte Inhalte in effiziente Sprach-Tokens um
- Strukturerhalt – bewahrt Hierarchie, Formatierung und visuelle Hinweise
- Adaptive Komprimierung – passt sich der Komplexität des Dokuments an
Die Zahlen
Laut DeepSeeks Forschung:
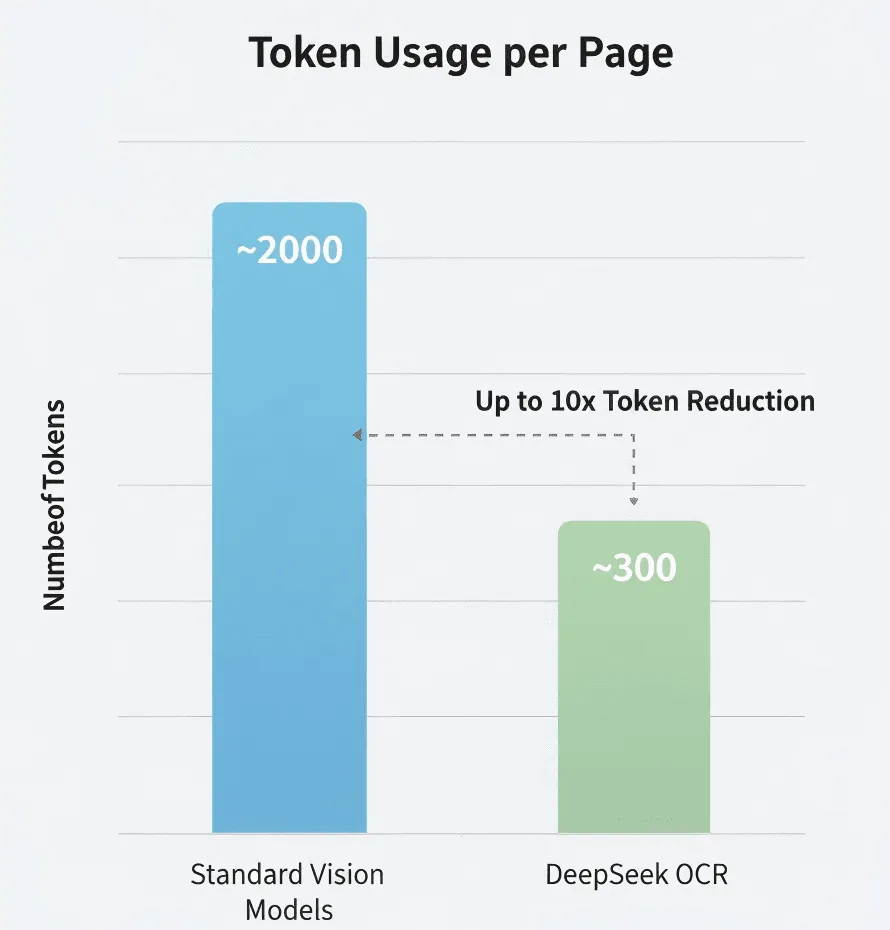
- Standard-Vision-Modell: ~2.000 Tokens/Seite
- DeepSeek OCR: ~300–400 Tokens/Seite
- Effektive Komprimierung: 5–8×
Ich habe das nicht unabhängig geprüft, aber selbst wenn die Werte nur annähernd stimmen, ist das beeindruckend.
Architektur-Überblick
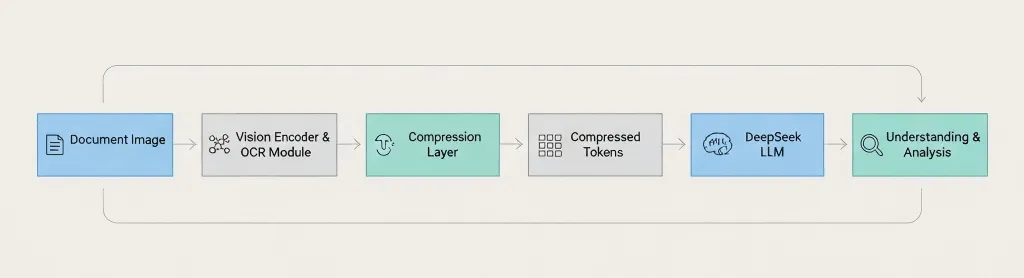
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis Der entscheidende Unterschied: DeepSeek komprimiert vor dem Übergang zum Sprachmodell, nicht danach. 3. Wie es tatsächlich funktioniert
Die Pipeline gliedert sich folgendermaßen:
Schritt 1: Bildverarbeitung
Standardmäßiges Preprocessing: Auflösungsverbesserung, Rauschreduktion, Ausrichtungskorrektur und Layout-Erkennung.
Schritt 2: Texterkennung
Extrahiert Zeichen, Absätze, Tabellen, Kopf-/Fußzeilen und Formatierungshinweise.
Schritt 3: Kontextkomprimierung
Gruppiert zusammengehörigen Text semantisch, entfernt redundante Tokens, kodiert Struktur effizient und bewahrt Layoutinformationen.
Schritt 4: LLM-Integration
Speist komprimierte Repräsentationen in das Modell von DeepSeek für Fragenbeantwortung, Zusammenfassungen, Informationsextraktion und Dokumentvergleiche.
Sprachunterstützung
Englisch, Chinesisch und die meisten europäischen Sprachen werden wahrscheinlich unterstützt. Aber testen Sie zuerst mit Ihrer Zielsprache.
Handschrift?
Nicht bestätigt. Der Blogbeitrag konzentriert sich auf gedruckten Text. Wenn Sie Handschrift-OCR benötigen, sind Google Vision oder Azure vermutlich sicherere Optionen.
4. Was Sie damit machen können
Unterstützte Dokumenttypen
- PDFs (nativ & gescannt)
- Bilder: PNG, JPEG, TIFF
- Mehrseitige Dokumente
- Komplexe Layouts
Fähigkeiten
- Hochpräzise Textextraktion
- Erhält Struktur und Formatierung
- Tabellen- und Absatz-Erhalt
- Kontextbasierte Analyse via LLM
Sie können Fragen stellen wie:
- „Fasse Abschnitt 3 zusammen“
- „Liste alle Namen und Daten als JSON auf“
- „Vergleiche diese Version mit der vorherigen“
- „Markiere alle Risikohinweise“
Wobei es vermutlich an Grenzen stößt
- Schlechte Bildqualität oder künstlerische Schriften
- Layouts mit gemischten Sprachen (vorher testen!)
- Mathematische Gleichungen
- Diagramme oder Grafiken (nur Textbeschriftungen)
5. Erste Schritte
Wichtig: Die API von DeepSeek ist OpenAI-kompatibel, aber prüfen Sie die Dokumentation für die genauen Modellnamen und Parameter.
Sicherheits-Hinweis: Überprüfen Sie immer die Einhaltung (GDPR, HIPAA), bevor Sie sensible Dokumente an Drittanbieter-APIs hochladen.
Was Sie benötigen
- Einen DeepSeek API-Key (Registrierung unter deepseek.com)
- Python 3.8+ oder Node.js 14+
- Grundkenntnisse in API-Aufrufen
Entwickler-Setup
pip install openai pillowBeispiel 1: Einfache Textextraktion
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Beispiel 2: Fragen zu einem Dokument stellen
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Beispiel 3: Tabellen als JSON extrahieren
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentBeispiel 4: Bildqualität vorher verbessern
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Tipps für bessere Ergebnisse
Seien Sie in Ihren Prompts präzise. Statt „Informationen extrahieren“ lieber „extrahiere Rechnungsnummer, Datum und Gesamtbetrag“ sagen.
Verwenden Sie hochauflösende Scans. Mindestens 300 DPI. Gutes Licht. Keine Schatten.
Validieren Sie immer kritische Daten. Vertrauen Sie auf OCR nicht blind bei Beträgen, Daten oder rechtlichen Angaben.
Verfolgen Sie Ihre Nutzung. Überwachen Sie Tokens, Latenz und Fehlerraten, damit Sie optimieren können.
6. Leistung in der Praxis
Ich habe selbst keine umfassenden Benchmarks durchgeführt, daher sollten Sie dies mit einer gesunden Skepsis betrachten.
Token-Komprimierung
DeepSeek behauptet, 5–10× weniger Tokens als Standardmodelle zu verwenden. Wenn das stimmt, ist das eine erhebliche Kostenersparnis bei der Verarbeitung großer Mengen.
Genauigkeit
Vergleichbar mit den führenden OCR-Engines bei sauberem Text. Die Genauigkeit nimmt ab bei schlechten Scans, ungewöhnlichen Schriftarten oder beschädigten Dokumenten.
Geschwindigkeit
Etwa 1–3 Sekunden pro Seite in meinen begrenzten Tests. Ihre Ergebnisse können je nach Dokumentlänge, Bildqualität und Serverauslastung variieren.
Kosteneffizienz
Wenn Sie pro Token zahlen (wie bei den meisten LLM-APIs), bedeutet die Nutzung von 5–10× weniger Tokens große Einsparungen. Überprüfen Sie aber die aktuellen DeepSeek-Preise – ich habe keine aktuellen Angaben.
7. Wann sollten Sie dies verwenden vs. traditionelle OCR?
DeepSeek OCR verwenden, wenn:
- Sie lange Dokumente (20+ Seiten) verarbeiten
- Sie KI-Verständnis benötigen, nicht nur Textextraktion
- Kosten ein entscheidender Faktor sind (Verarbeitung großer Mengen)
- Sie Einfachheit möchten (keine Chunking-Logik)
Traditionelle OCR verwenden, wenn:
- Sie nur Textextraktion brauchen (keine KI-Analyse)
- Datenschutz entscheidend ist (Sie können keine externen APIs nutzen) → nutzen Sie Tesseract
- Sie spezielle Funktionen benötigen (Handschrift, Formulare) → Google Vision oder AWS Textract
- Das Budget bei Null liegt → nutzen Sie Tesseract (kostenlos, Open Source)
Schneller Vergleich
Bedarf | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Lange Dokumente (50+ Seiten) | Exzellent | Funktioniert (keine KI) | Chunking erforderlich | Chunking erforderlich |
KI-Verständnis | Integriert | Keine | Separater Service | Separater Service |
Kosten (hohe Mengen) | Effizient | Kostenlos | Kann teuer sein | Kann teuer sein |
Datenschutz/On-Premise | Nur Cloud | Self-hosted | Nur Cloud | Nur Cloud |
Handschrift | Unbekannt | Begrenzt | Gut | Gut |
Tabellen | Gut | Einfach | Gut | Exzellent |
8. Praktische Anwendungen
Analyse juristischer Dokumente
Verarbeiten Sie ganze Verträge auf einmal. Stellen Sie Fragen wie „Was sind die Kündigungsklauseln?“ oder „Welche Risiken gibt es?“ Die KI sieht den gesamten Vertrag und behält den Kontext über alle Abschnitte hinweg.
Bewertung wissenschaftlicher Arbeiten
Extrahieren Sie zentrale Erkenntnisse aus mehreren Papers, vergleichen Sie Methoden, erstellen Sie Zusammenfassungen von Literaturübersichten. Das ersetzt nicht das eigentliche Lesen, beschleunigt aber das erste Screening.
Verarbeitung von Finanzberichten
Extrahieren Sie automatisch alle Finanztabellen, wandeln Sie diese in strukturierte Daten um, erkennen Sie Trends über verschiedene Berichtsperioden hinweg. Überprüfen Sie die extrahierten Finanzdaten immer und verlassen Sie sich nicht nur auf die KI bei kritischen Zahlen.
Digitalisierungsprojekte für Dokumente
Verarbeiten Sie historische Dokumente im Batch, erzeugen Sie durchsuchbaren Text und extrahieren Sie automatisch Metadaten. Es dauert trotzdem Zeit – aber die Kontextkomprimierung sorgt für mehr Effizienz.
Rechnungs- und Belegverarbeitung
Extrahieren Sie automatisch strukturierte Daten aus Rechnungen (Lieferant, Rechnungsnummer, Datum, Positionen, Summen) und übernehmen Sie diese in Buchhaltungssysteme. Bei sehr hohen Volumen könnte AWS Textract in diesem Bereich weiterhin spezialisierter sein.
Was wahrscheinlich nicht gut funktioniert
Medizinische Unterlagen – Bedenken bezüglich HIPAA-Konformität, Anforderungen an Genauigkeit, Haftungsfragen.
Historische Dokumente – Verblasster Text, ungewöhnliche Schriftarten, beschädigte Seiten benötigen möglicherweise spezialisierte OCR.
Handschriftliche Notizen – Falls Unterstützung für Handschrift existiert, ist diese vermutlich nicht die stärkste Funktion.
Echtzeitverarbeitung – Wenn Sie Antwortzeiten unter einer Sekunde benötigen, ist OCR + LLM wahrscheinlich zu langsam.
9. Tipps & Best Practices
Bildqualität ist entscheidend
Für physische Dokumente:
- Scannen Sie mit mindestens 300 DPI
- Verwenden Sie nach Möglichkeit einen Flachbettscanner
- Sorgen Sie für gleichmäßige Beleuchtung (keine Schatten oder Reflexionen)
- Seiten vollständig flach drücken
Für Handyfotos:
- Gute Beleuchtung verwenden (Tageslicht ist am besten)
- Gerät ruhig halten
- Gerade aufnehmen (Winkel vermeiden)
- Mehrere Aufnahmen machen, falls unsicher
Seien Sie spezifisch in Ihren Anweisungen
Vage: „Informationen aus diesem Dokument extrahieren.“
Besser: „Extrahiere den gesamten Text aus dieser Rechnung und erhalte die Tabellenstruktur.“
Am besten: „Extrahiere Rechnungsdaten in genau diesem JSON-Format: {...}. Falls ein Feld nicht gefunden wird, verwende null.“
Kritische Daten immer validieren
Verlassen Sie sich nie blind auf OCR-Ausgaben für:
- Finanzbeträge
- Datumsangaben
- Namen
- Juristische Begriffe
- Medizinische Informationen
Für wichtige Dokumente sollte ein Mensch den Prozess prüfen.
Mit echten Dokumenten testen
Testen Sie nicht nur mit perfekten PDFs. Testen Sie auch mit:
- Gescannte Dokumente
- Fotos, die mit Handys aufgenommen wurden
- Bilder mit geringer Qualität
- Dokumente mit Kaffeeflecken
- Geknickte Seiten
Ihre Produktionsdaten werden nicht perfekt sein. Ihre Tests sollten es auch nicht sein.
Reale Erwartungen setzen
OCR ist nicht perfekt. Auch nicht mit KI:
- Erwarten Sie 95–99 % Genauigkeit bei sauberen Dokumenten
- Rechnen Sie mit 85–95 % bei schlechter Qualität
- Für kritische Daten ist menschliche Prüfung erforderlich
- Planen Sie Zeit für Fehlerbehandlung ein
Haben Sie einen Notfallplan
APIs können ausfallen. Netzwerke brechen ab. Dienste ändern sich. Haben Sie eine Absicherung:
- Ergebnisse zwischenspeichern, wenn möglich
- Retry-Logik implementieren
- Eine Ausweich-OCR-Lösung in Betracht ziehen
- Kritische Dokumente sichern
10. Einschränkungen, die Sie kennen sollten
Kontextfenster sind weiterhin begrenzt
Die Komprimierung hilft, aber Sie können keine unendlichen Dokumente verarbeiten. 500-seitige Bücher müssen weiterhin aufgeteilt werden.
Genauigkeit ist nicht perfekt
Kein OCR-System ist zu 100 % genau. Fehler treten auf bei ungewöhnlichen Schriftarten, schlechter Bildqualität, komplexen Layouts, gemischten Sprachen und Handschrift.
Es ist keine Magie
Die KI kann Text extrahieren und verstehen, aber sie kann wirklich unlesbaren Text nicht lesen, keinen Kontext verstehen, für den sie nicht trainiert wurde, und keine grundlegenden Bildqualitätsprobleme beheben.
Kostenüberlegungen
Obwohl die Token-Komprimierung Kosten senkt, zahlen Sie weiterhin für API-Aufrufe, Token-Nutzung und Verarbeitungszeit. Bei extrem hohen Volumina können die Kosten erheblich steigen.
Datenschutz und Compliance
Das Senden von Dokumenten an externe APIs bedeutet, dass Daten Ihre Infrastruktur verlassen und den Nutzungsbedingungen des Anbieters unterliegen. Bestimmte Compliance-Anforderungen (HIPAA, DSGVO, etc.) könnten nicht erfüllt werden.
Prüfen Sie DeepSeeks Datenschutzrichtlinie und Compliance-Zertifizierungen sorgfältig.
Abhängigkeit von der API
Sie sind abhängig von der API-Verfügbarkeit, Rate Limits, Preisänderungen und Dienstkontinuität von DeepSeek. Halten Sie einen Backup-Plan bereit.
Sprachunterstützung unbekannt
DeepSeek hat keine umfassenden Details zur Sprachunterstützung veröffentlicht. Wenn Sie OCR für weniger gängige Sprachen, Rechts-nach-links-Schriften oder komplexe Schriftsysteme (Devanagari, Thai, etc.) benötigen, testen Sie gründlich.
Keine Offline-Möglichkeit
Im Gegensatz zu Tesseract kann DeepSeek OCR nicht offline ausgeführt werden. Sie benötigen eine Internetverbindung, API-Zugang und akzeptable Latenz.
11. Häufige Fragen
Wie viel kostet DeepSeek OCR?
Ich habe keine aktuellen Preise. Prüfen Sie die DeepSeek-Website für die neuesten Tarife. Es basiert wahrscheinlich auf Tokens, ähnlich wie andere LLM-APIs.
Kann ich es kostenlos nutzen?
DeepSeek bietet möglicherweise eine kostenlose Stufe oder einen Testzeitraum an. Prüfen Sie die Website.
Wie schneidet es im Vergleich zu Google Vision ab?
Unterschiedliche Anwendungsfälle. DeepSeek OCR ist besser für lange Dokumente, die KI-Verständnis erfordern. Google Vision ist besser für Handschrift und Bildanalyse jenseits von Text.
Ist die Kontextkomprimierung verlustbehaftet? Geht Information verloren?
Betrachten Sie es als intelligente, verlustbehaftete Komprimierung. Sie bewahrt Kernsemantik, Struktur und Schlüsselinformationen, kann aber redundante visuelle Details oder Formatierungshinweise verwerfen, die für das Verständnis nicht entscheidend sind. Das Ziel ist nicht eine pixelgenaue Rekonstruktion – sondern dem LLM zu ermöglichen, das Dokument effizient und präzise zu verstehen.
Wie unterscheidet sich das von ZIP-Komprimierung?
Völlig unterschiedlich. ZIP ist verlustfreie Dateikomprimierung – es reduziert die Speichergröße. Nach dem Entpacken erhalten Sie eine identische Kopie. Ein LLM muss aber dennoch den vollständigen unkomprimierten Text verarbeiten, was viele Tokens verbraucht.
DeepSeeks Kontextkomprimierung ist eine semantische Komprimierung. Sie reduziert die Tokens, die an das LLM zur Analyse gesendet werden, senkt KI-Kosten und passt in Kontextfenster.
Muss ich DeepSeeks eigenes LLM verwenden?
Ja. Die Kontextkomprimierung ist tief in DeepSeeks Sprachmodelle integriert. Das komprimierte Tokenformat ist proprietär und speziell für DeepSeek-Modelle entwickelt. Sie können diese komprimierten Tokens nicht an GPT-4 oder Claude übertragen.
Ist die Komprimierung bei einfachen, rein textbasierten Bildern weiterhin effektiv?
Weniger spektakulär. Die Technologie spielt ihre Stärken bei komplexen Layouts, gemischtem Text und Bildern sowie viel Weißraum aus. Bei einer einfachen Textwand liegt die Tokenanzahl ähnlich wie bei klassischem OCR, aber Sie profitieren dennoch vom optimierten All-in-One-API-Aufruf.
Was sind die geschätzten Zeit- und Kosten für die Verarbeitung eines 100-seitigen PDFs?
Zeit: Im Schnitt einige Sekunden pro Seite, basierend auf öffentlichen Daten.
Kosten: Wenn ein herkömmliches Vision-LLM 2.000 Tokens pro Seite benötigt und DeepSeek OCR nur 300, könnten die Gesamtkosten für ein 100-seitiges Dokument nur 15 % der herkömmlichen Methode betragen. Prüfen Sie DeepSeeks offizielle Preise für genaue Angaben.
Kann das Diagramme, Grafiken oder Schaubilder verstehen?
Es ist hervorragend darin, textuelle Komponenten (Titel, Achsenbeschriftungen, Legenden) zu extrahieren. Es kann jedoch nicht die visuelle Logik eines Diagramms interpretieren wie „Welcher Balken ist am höchsten?“ oder „Was ist der nächste Schritt in diesem Flussdiagramm?“ Für solche Aufgaben eignen sich fortschrittlichere multimodale Modelle besser.
Was passiert, wenn die Dokumentenqualität schlecht ist?
Wie bei jeder OCR wirkt sich die Eingabequalität direkt auf die Ausgabequalität aus. Während DeepSeek OCR Bildvorverarbeitung beinhaltet, um etwas Rauschen zu kompensieren, führen starke Artefakte, Unschärfe oder niedrige Auflösung zu deutlich schlechterer Genauigkeit. Nutzen Sie immer hochwertige Scans mit mindestens 300 DPI.
Abschließende Gedanken
DeepSeek OCRs Kontextkomprimierung ist nicht spektakulär, sondern praktisch.
Sie senkt Kosten, vereinfacht die Architektur und macht es endlich realistisch, lange Dokumente mit einem LLM von Anfang bis Ende zu analysieren.
Sie wird nicht jedes OCR-Tool ersetzen. Tesseract und Google Vision sind bei Datenschutz- oder Handschriftfällen weiterhin führend. Für skalierbares, KI-gestütztes Dokumentenverständnis ist DeepSeeks Ansatz jedoch ein großer Schritt nach vorn.
Probieren Sie es mit Ihrem längsten Dokument aus. Wenn es in einem Durchgang verarbeitet werden kann und kohärente Antworten liefert, merken Sie den Unterschied sofort.
Ressourcen:
- DeepSeek OCR Blogpost
- The Decoder: DeepSeeks OCR-Komprimierung
- DeepSeek API-Dokumentation (Offizielle Website)
Haftungsausschluss: Dieser Artikel basiert auf öffentlich zugänglichen Daten und begrenzten eigenen Tests. Überprüfen Sie wichtige Details stets in der offiziellen Dokumentation, bevor Sie in Produktion gehen.