DeepSeek OCR: Практическое руководство по их технологии сжатия контекста (2025)
Последнее обновление: 2026-01-22 18:05:30

Последнее обновление: 22 октября 2025
Если вы следите за развитием ИИ в последнее время, вы, вероятно, слышали о новой системе OCR от DeepSeek. Меня заинтересовало не просто очередное заявление о "распознавании текста на изображениях", а то, как они решили реальную и дорогостоящую проблему: обработку длинных документов без превышения лимита токенов.
Это руководство объясняет, чем DeepSeek OCR отличается от других, как она работает и стоит ли использовать её в ваших проектах.
Содержание
- Чем отличается DeepSeek OCR?(#what-makes-it-different)
- Прорыв в сжатии контекста(#context-compression)
- Как это действительно работает(#how-it-works)
- Что вы можете с этим делать(#capabilities)
- С чего начать(#getting-started)
- Реальная производительность(#performance)
- Когда использовать это вместо традиционного OCR?(#comparison)
- Практические применения(#applications)
- Советы и лучшие практики(#tips)
- Ограничения, о которых стоит знать(#limitations)
- Часто задаваемые вопросы(#faq)
1. Чем отличается DeepSeek OCR?
Сам по себе OCR — не новинка: такие инструменты, как Tesseract, Google Vision и AWS Textract существуют уже много лет. Все они хорошо извлекают текст.
Настоящее узкое место появляется, когда нужно, чтобы ИИ-модель поняла документ, а не просто транскрибировала его.
Проблема токенов
Подача необработанного вывода OCR в крупную языковую модель неэффективна.
Представьте себе контракт на 50 страниц:
- Вы извлекаете текст
- Пробуете отправить его в LLM
- Упираетесь в лимит контекста после трёх страниц
- Начинаете дробить, суммировать и терять контекст
Это раздражает, и я потратил часы на решение именно этой проблемы.
Решение DeepSeek
DeepSeek не разделяет OCR и понимание на отдельные этапы. Их система выполняет OCR и семантическое сжатие одновременно.
Вместо передачи необработанного текста DeepSeek OCR кодирует смысл и макет в компактной форме, сокращая использование токенов в 5–10 раз.
Контракт на 50 страниц, которому раньше требовалось 100k токенов, теперь может уместиться в 12k–15k.
Почему это важно:
- Меньше затрат (меньше токенов = дешевле инференс)
- Более простой рабочий процесс (без ручного дробления)
- Более полный контекст (модель видит весь документ)
- Быстрее обработка (один вызов API вместо десятков)
2. Прорыв в сжатии контекста
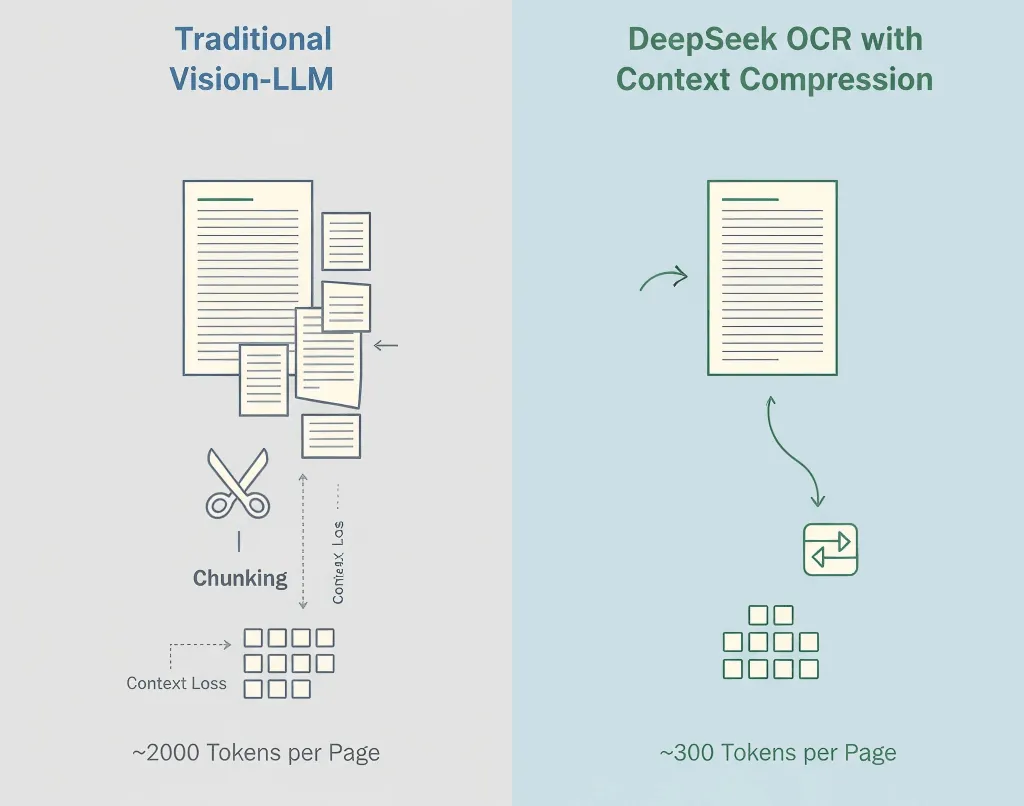
Традиционные модели Vision-Language превращают каждый участок изображения в токены, часто 1 500–2 500 на страницу. Большинство этих токенов представляют пиксели, а не смысл.
Метод DeepSeek
- Сначала OCR — извлекает текст, макет и таблицы
- Семантическое сжатие — преобразует распознанное содержимое в эффективные языковые токены
- Сохранение структуры — оставляет иерархию, форматирование и визуальные подсказки
- Адаптивное сжатие — подстраивается под сложность документа
Цифры
Согласно исследованиям DeepSeek:
- Стандартная vision-модель: ~2 000 токенов/страница
- DeepSeek OCR: ~300–400 токенов/страница
- Эффективность сжатия: 5–8 раз
Я это сам не проверял, но даже если они близки к истине — это впечатляет.
Общий обзор архитектуры
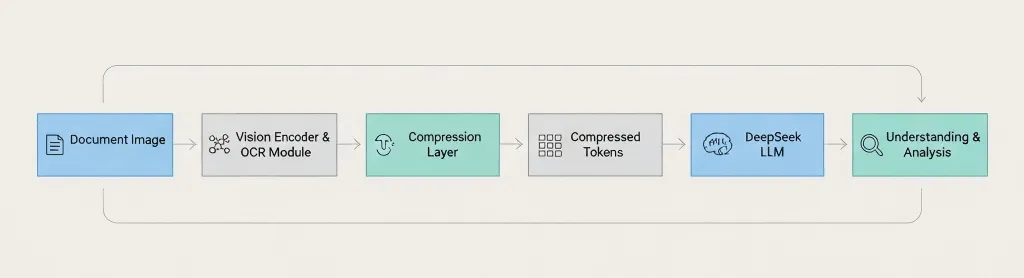
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis The key difference: DeepSeek compresses before passing to the language model, not after. 3. Как это действительно работает
Пайплайн состоит из следующих этапов:
Шаг 1: Обработка изображения
Стандартная предобработка: повышение разрешения, уменьшение шума, коррекция ориентации и определение макета.
Шаг 2: Распознавание текста
Извлечение символов, абзацев, таблиц, колонтитулов и признаков форматирования.
Шаг 3: Сжатие контекста
Семантическая группировка связанных фрагментов текста, удаление избыточных токенов, эффективное кодирование структуры и сохранение сведений о макете.
Шаг 4: Интеграция с LLM
Передача сжатых представлений в модель DeepSeek для ответов на вопросы, суммирования, извлечения информации и сравнения документов.
Языковое покрытие
Английский, китайский и основные европейские языки, скорее всего, поддерживаются. Но я бы протестировал на вашем языке перед внедрением.
Рукописный текст?
Не подтверждено. В блоге акцент на печатном тексте. Если нужен рукописный OCR, скорее стоит рассмотреть Google Vision или Azure.
4. Что вы с этим можете делать
Поддерживаемые типы документов
- PDF (нативные и сканированные)
- Изображения: PNG, JPEG, TIFF
- Многостраничные документы
- Сложные макеты
Возможности
- Высокоточное извлечение текста
- Сохранение структуры и форматирования
- Сохранение таблиц и абзацев
- Контекстно-зависимый анализ с помощью LLM
Возможные вопросы:
- "Суммируй раздел 3"
- "Выведи все имена и даты в формате JSON"
- "Сравни эту версию с предыдущей"
- "Выдели все формулировки о рисках"
Чего, вероятно, не сможет
- Плохое качество изображения или художественные шрифты
- Макеты со смешанными языками (тестируйте сначала)
- Математические уравнения
- Диаграммы или графики (только подписи к тексту)
5. С чего начать
Важно: API DeepSeek совместим с OpenAI, но проверьте документацию для точных названий моделей и параметров.
Напоминание о безопасности: Всегда подтверждайте соответствие (GDPR, HIPAA) перед загрузкой чувствительных файлов на сторонние API.
Что потребуется
- Ключ API DeepSeek (зарегистрируйтесь на deepseek.com)
- Python 3.8+ или Node.js 14+
- Базовое знание вызовов API
Настройка для разработчика
pip install openai pillowПример 1: Простое извлечение текста
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Пример 2: Задаем вопросы по документу
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Пример 3: Извлечение таблиц в формате JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentПример 4: Предварительное улучшение качества изображения
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Советы для наилучших результатов
Формулируйте запросы максимально конкретно. Вместо "извлечь информацию" напишите "извлечь номер счета, дату и общую сумму".
Используйте сканы высокого разрешения. Минимум 300 DPI. Хорошее освещение. Без теней.
Всегда проверяйте критичные данные. Не доверяйте OCR вслепую при извлечении финансовых значений, дат или юридических условий.
Отслеживайте своё использование. Мониторьте токены, задержки и уровень ошибок, чтобы оптимизировать процесс.
6. Производительность в реальных условиях
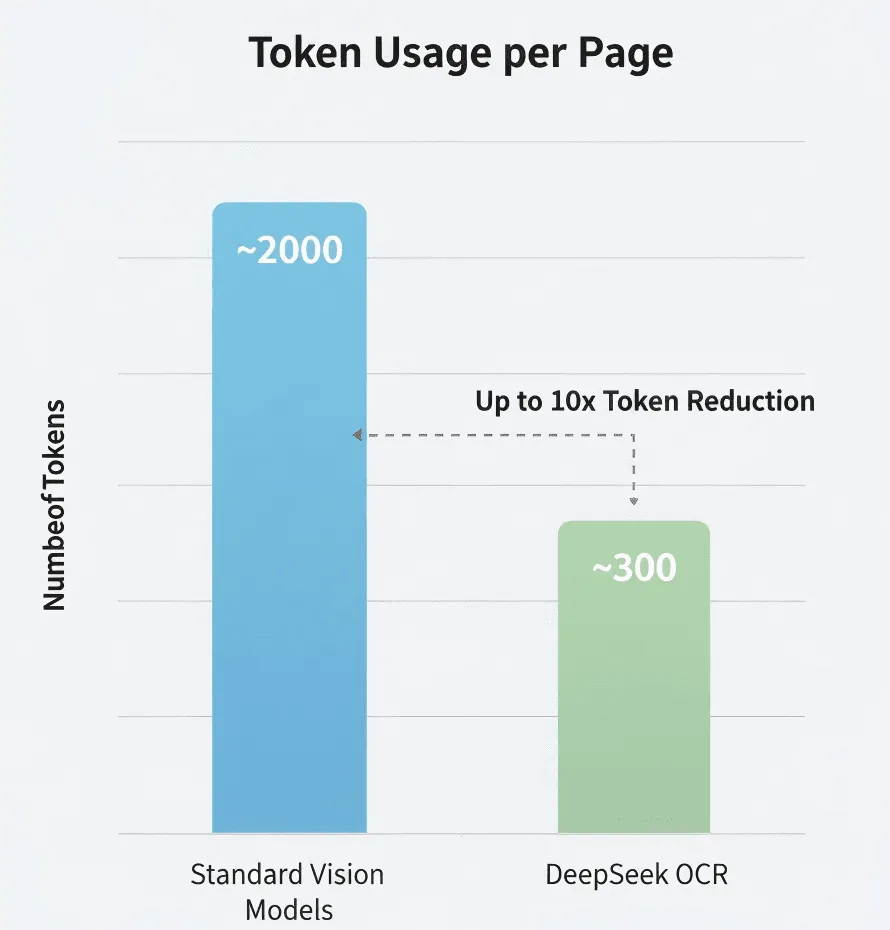
Я сам не проводил комплексных тестов, так что относитесь к этому с должным скептицизмом.
Сжатие токенов
DeepSeek заявляет о 5–10× меньшем количестве токенов по сравнению со стандартными моделями. Если это так, это значит значительное снижение затрат при обработке больших объемов.
Точность
Сопоставима с крупными движками OCR на чистом тексте. Точность снижается на некачественных сканах, при необычных шрифтах или повреждённых документах.
Скорость
В среднем 1–3 секунды на страницу в моих ограниченных тестах. Ваши результаты могут отличаться в зависимости от длины документа, качества изображения и загрузки сервера.
Экономия средств
Если вы платите за токен (как в большинстве LLM API), использование в 5–10× меньше токенов означает значительную экономию. Но проверьте реальные тарифы DeepSeek — у меня нет текущей информации.
7. Когда использовать это решение вместо традиционного OCR?
Используйте DeepSeek OCR, когда:
- Вам нужно обрабатывать длинные документы (20+ страниц)
- Вам нужно понимание ИИ, а не только извлечение текста
- Вопрос цены важен (обработка больших объёмов)
- Важна простота (нет необходимости реализовывать логику разбиения)
Используйте традиционный OCR, когда:
- Вам нужно только извлечение текста (без ИИ-анализа)
- Конфиденциальность критична (нельзя отправлять во внешние API) → используйте Tesseract
- Нужны специализированные функции (рукописный текст, формы) → Google Vision или AWS Textract
- Бюджет нулевой → используйте Tesseract (бесплатно, с открытым кодом)
Быстрое сравнение
Потребность | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Длинные документы (50+ страниц) | Отлично | Работает (без ИИ) | Требуется разбиение | Требуется разбиение |
Понимание ИИ | Встроено | Нет | Отдельный сервис | Отдельный сервис |
Стоимость (большой объем) | Эффективно | Бесплатно | Может быть дорого | Может быть дорого |
Конфиденциальность/локальное размещение | Только облако | Самостоятельное размещение | Только облако | Только облако |
Рукописный текст | Неизвестно | Ограничено | Хорошо | Хорошо |
Таблицы | Хорошо | Базово | Хорошо | Отлично |
8. Практические применения
Анализ юридических документов
Обрабатывайте целые договоры за один раз. Задавайте вопросы, например: «Каковы условия расторжения?» или «Выделите потенциальные риски». ИИ видит весь контракт, сохраняя контекст между разделами.
Рецензии научных статей
Извлекайте ключевые выводы из нескольких статей, сравнивайте методы, формируйте краткие обзоры литературы. Это не заменяет чтение статей, но ускоряет первоначальный отбор.
Обработка финансовой отчетности
Автоматически извлекайте все финансовые таблицы, переводите в структурированные данные, выявляйте тренды между отчетными периодами. Всегда перепроверяйте полученные финансовые данные и не полагайтесь только на ИИ для критичных цифр.
Проекты по оцифровке документов
Пакетно обрабатывайте исторические документы, создавайте поисковый текст, извлекайте метаданные автоматически. Это все еще занимает время, но сжатие контекста делает процесс эффективнее.
Обработка счетов и чеков
Автоматически извлекайте структурированные данные из счетов (название поставщика, номер счета, дата, позиции, суммы) и отправляйте их в бухгалтерские системы. При очень больших объемах AWS Textract, возможно, всё ещё будет более специализированным выбором.
Что, скорее всего, будет работать не очень хорошо
Медицинские документы - требования к соответствию HIPAA, высокая точность, юридическая ответственность.
Исторические документы - потёртый текст, необычные шрифты, повреждённые страницы могут потребовать специализированный OCR.
Рукописные заметки - если поддержка рукописного текста и есть, это, скорее всего, не самая сильная функция.
Обработка в реальном времени - если необходимы отклики менее чем за секунду, связка OCR + LLM может быть слишком медленной.
9. Советы и лучшие практики
Качество изображения имеет значение
Для физических документов:
- Сканируйте с минимальным разрешением 300 DPI
- Используйте планшетный сканер, если возможно
- Обеспечьте равномерное освещение (без теней и бликов)
- Полностью распрямите страницы
Для фотографий с мобильного:
- Используйте хорошее освещение (лучше всего естественный свет)
- Держите устройство устойчиво
- Снимайте строго по центру (избегайте угловых снимков)
- Сделайте несколько снимков, если не уверены
Формулируйте запросы конкретно
Неясно: «Извлечь информацию из этого документа.»
Лучше: «Извлечь весь текст из этого счета, сохранив структуру таблицы.»
Лучше всего: «Извлечь данные счета в этом точном формате JSON: {...}. Если какое-либо поле не найдено, используйте null.»
Всегда проверяйте критически важные данные
Никогда не доверяйте результатам OCR слепо при работе с:
- Суммами
- Датами
- Именами
- Юридическими терминами
- Медицинской информацией
Для важных документов внедрите процедуру проверки человеком.
Тестируйте на реальных документах
Не ограничивайтесь идеальными PDF. Тестируйте на:
- Отсканированных документах
- Фотографиях, сделанных на телефон
- Низкокачественных изображениях
- Документах с пятнами кофе
- Помятых страницах
Ваши рабочие данные не будут идеальными. Так что и тестирование не должно быть идеальным.
Устанавливайте реалистичные ожидания
OCR не идеален. Даже с ИИ:
- Ожидайте точность 95-99% на чистых документах
- Ожидайте 85-95% на документах низкого качества
- Ожидайте необходимости проверки данных человеком для критически важных данных
- Заложите время на обработку ошибок
Имейте резервный план
API могут давать сбои. Соединение может прерываться. Сервисы могут меняться. Имейте план на случай непредвиденных ситуаций:
- Кэшируйте результаты, когда это возможно
- Внедряйте повторные попытки
- Рассмотрите резервный OCR-сервис
- Держите резервные копии важных документов
10. Ограничения, о которых стоит знать
Окна контекста все еще ограничены
Сжатие помогает, но обработать бесконечные документы невозможно. Книги в 500 страниц все еще надо обрабатывать по частям.
Точность не идеальна
Нет ни одной OCR-системы со 100% точностью. Ошибки возможны при необычных шрифтах, низком качестве изображений, сложных макетах, смешанных языках и при рукописном тексте.
Это не волшебство
ИИ может извлекать и понимать текст, но не способен читать по-настоящему неразборчивый текст, понимать контекст, на котором не обучался, или исправлять фундаментальные проблемы качества изображения.
Вопросы стоимости
Хотя сжатие токенов снижает затраты, вы все равно платите за вызовы API, использование токенов и время обработки. При очень больших объемах расходы могут быть существенными.
Конфиденциальность и соответствие требованиям
Отправка документов во внешние API означает, что данные покидают вашу инфраструктуру и подчиняются условиям обслуживания провайдера. Может не соответствовать определенным требованиям (HIPAA, GDPR и т.д.).
Внимательно изучите политику конфиденциальности и сертификаты соответствия DeepSeek.
Зависимость от API
Вы зависите от доступности API DeepSeek, ограничений по скорости, изменений цен и непрерывности работы сервиса. Имейте резервный план.
Неизвестная поддержка языков
DeepSeek не опубликовал подробную информацию о поддержке языков. Если вам нужен OCR для редких языков, письма справа налево или сложных алфавитов (деванагари, тайский и т.п.), тестируйте тщательно.
Нет офлайн режима
В отличие от Tesseract, DeepSeek OCR нельзя запустить офлайн. Требуется подключение к интернету, доступ к API и приемлемые задержки.
11. Часто задаваемые вопросы
Сколько стоит DeepSeek OCR?
У меня нет актуальной информации о ценах. Проверьте сайт DeepSeek для последних тарифов. Скорее всего, тарификация токеновая, как и у других LLM API.
Можно ли использовать бесплатно?
У DeepSeek может быть бесплатный тариф или пробный период. Смотрите их сайт.
Чем он отличается от Google Vision?
Разные задачи. DeepSeek OCR лучше для длинных документов, где нужна работа ИИ с пониманием. Google Vision лучше подходит для рукописного текста и анализа изображений сверх текста.
Контекстное сжатие с потерями? Теряется ли информация?
Подумайте об этом как об интеллектуальном сжатии с потерями. Сохраняет основную семантику, структуру и ключевую информацию, но может отбрасывать избыточные визуальные детали или элементы форматирования, которые не критичны для понимания. Цель не в пиксельном воспроизведении, а в том, чтобы LLM эффективно и точно понял документ.
Чем это отличается от сжатия ZIP?
Полностью разные концепции. ZIP — это без потерь, уменьшает размер файла для хранения. После распаковки получаете идентичную копию. Но LLM все равно нужно обрабатывать полный не сжатый текст, расходуя много токенов.
Контекстное сжатие DeepSeek — это семантическое сжатие. Оно уменьшает количество токенов, отправляемых в LLM для анализа, снижая затраты и укладываясь в окно контекста.
Я обязан использовать только LLM DeepSeek?
Да. Контекстное сжатие глубоко интегрировано с языковыми моделями DeepSeek. Сжатый формат токенов является проприетарным и специально создан для работы с моделями DeepSeek. Эти токены нельзя подавать в GPT-4 или Claude.
Сжатие эффективно для простых, только текстовых изображений?
Менее заметно. Технология особенно полезна для документов со сложным макетом, смешанным текстом и изображениями, большим количеством пустого пространства. Для простой «стены текста» количество токенов может быть сопоставимо с традиционным OCR, но вы все равно выигрываете за счет единого API-вызова.
Сколько времени и сколько стоит обработать PDF на 100 страниц?
Время: В среднем несколько секунд на страницу, по открытым данным.
Стоимость: Если требуется 2 000 токенов на страницу для Vision-LLM против 300 для DeepSeek OCR, общая стоимость токенов для документа на 100 страниц может составлять всего 15% от традиционного метода. Но для точных расчетов смотрите официальные цены DeepSeek.
Может ли распознавать диаграммы, графики или схемы?
Отлично извлекает текстовые элементы (заголовки, подписи осей, легенды). Но не может анализировать визуальную логику диаграммы, например «Какой столбик выше?» или «Какой следующий этап схемы?». Для таких задач больше подходят продвинутые мультимодальные модели.
Что будет, если качество исходного документа низкое?
Как и у любого OCR, качество входных данных напрямую влияет на результат. Хотя DeepSeek OCR включает предварительную обработку изображений для борьбы с шумом, сильные артефакты, размытость или низкое разрешение значительно снижают точность. Всегда используйте качественные сканы 300 DPI и выше.
Заключение
Контекстное сжатие DeepSeek OCR не выглядит эффектно — оно практично.
Оно снижает затраты, упрощает архитектуру и, наконец, делает реальным анализ длинных документов от начала до конца с помощью LLM.
Это не замена всем OCR-инструментам. Tesseract и Google Vision по-прежнему отлично подходят для случаев с конфиденциальностью или рукописным текстом. Но для масштабируемого ИИ-понимания документов подход DeepSeek — это реальный шаг вперед.
Попробуйте на самом длинном вашем документе. Если он обработается за один проход и даст связные ответы, вы сразу увидите разницу.
Ресурсы:
- DeepSeek OCR — пост в блоге
- The Decoder: DeepSeek's OCR Compression
- DeepSeek API Docs (официальный сайт)
Отказ от ответственности: Эта статья основана на публичных данных и ограниченном личном тестировании. Всегда сверяйте детали по официальной документации перед использованием в продакшне.