DeepSeek OCR:其实用指南——上下文压缩技术解读(2025)
最后更新: 2026-01-22 18:05:30

最近更新:2025年10月22日
如果你最近关注了AI的发展,应该听说过DeepSeek推出的新OCR系统。吸引我注意力的不仅仅是“我们也能从图片中读取文字”这种常规说法,而是他们如何解决了一项真实且成本高昂的局限:在不超出token预算的情况下处理长文档。
本指南将拆解DeepSeek OCR的新颖之处、其运作方式,以及它是否值得被应用到你的项目中。
目录
- DeepSeek OCR有何不同?(#what-makes-it-different)
- 上下文压缩突破(#context-compression)
- 其实际工作原理(#how-it-works)
- 应用能力介绍(#capabilities)
- 快速上手指南(#getting-started)
- 实际性能表现(#performance)
- 何时应选它而非传统OCR?(#comparison)
- 典型应用场景(#applications)
- 技巧与最佳实践(#tips)
- 已知局限性(#limitations)
- 常见问题(#faq)
1. DeepSeek OCR有何不同?
OCR本身并不新,像Tesseract、Google Vision、AWS Textract等工具已存在多年。这些工具在文本提取上都做得不错。
真正的瓶颈出现在你需要AI模型去理解文档,而不仅仅是转录时。
Token难题
直接将原始OCR结果输入大语言模型是非常低效的。
想象一下一个50页的合同:
- 你提取出文本
- 尝试发送给LLM
- 三页后便触及上下文限制
- 你只能分块、总结,结果丢失上下文
这非常令人沮丧,我就为这个问题浪费了数小时。
DeepSeek的解决方案
DeepSeek并未将OCR和理解视为两个独立步骤。他们的系统把OCR和语义压缩合二为一。
DeepSeek OCR不是直接丢出原始文本,而是将语义与版面信息编码为精简形式,将token占用减少5–10倍。
一个曾经需要10万个token的50页合同,如今可能仅需1.2万–1.5万token。
这有什么意义:
- 成本更低(Token更少 = 推理费用下降)
- 流程更简单(无需手动分块)
- 上下文更完整(模型可见全篇文档)
- 处理更快(一次API调用即可,不需多次)
2. 上下文压缩突破
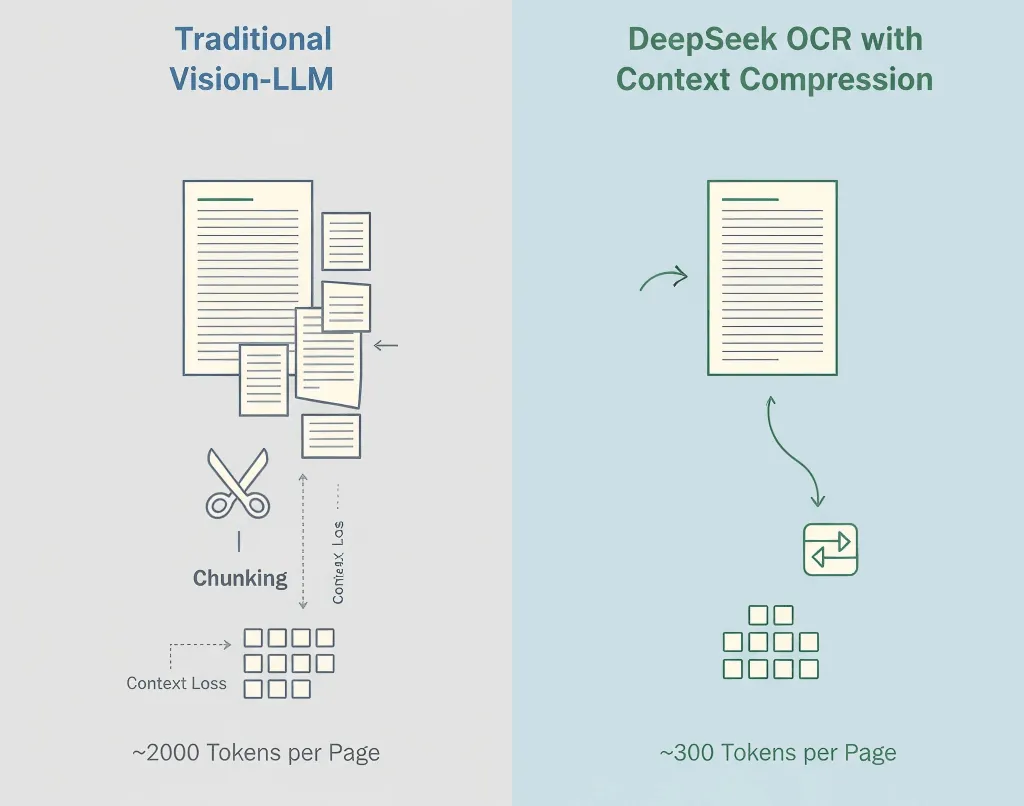
传统视觉-语言模型会把图片里的每个区域都映射为token,通常每页高达1,500–2,500个。绝大多数token其实只是像素,而非真实含义。
DeepSeek的方法
- 优先OCR——提取文本、布局和表格
- 语义压缩——把识别内容转为高效的语言token
- 结构保留——保持层级、格式以及视觉线索
- 自适应压缩——根据文档复杂度灵活调整
数据对比
据DeepSeek研究:
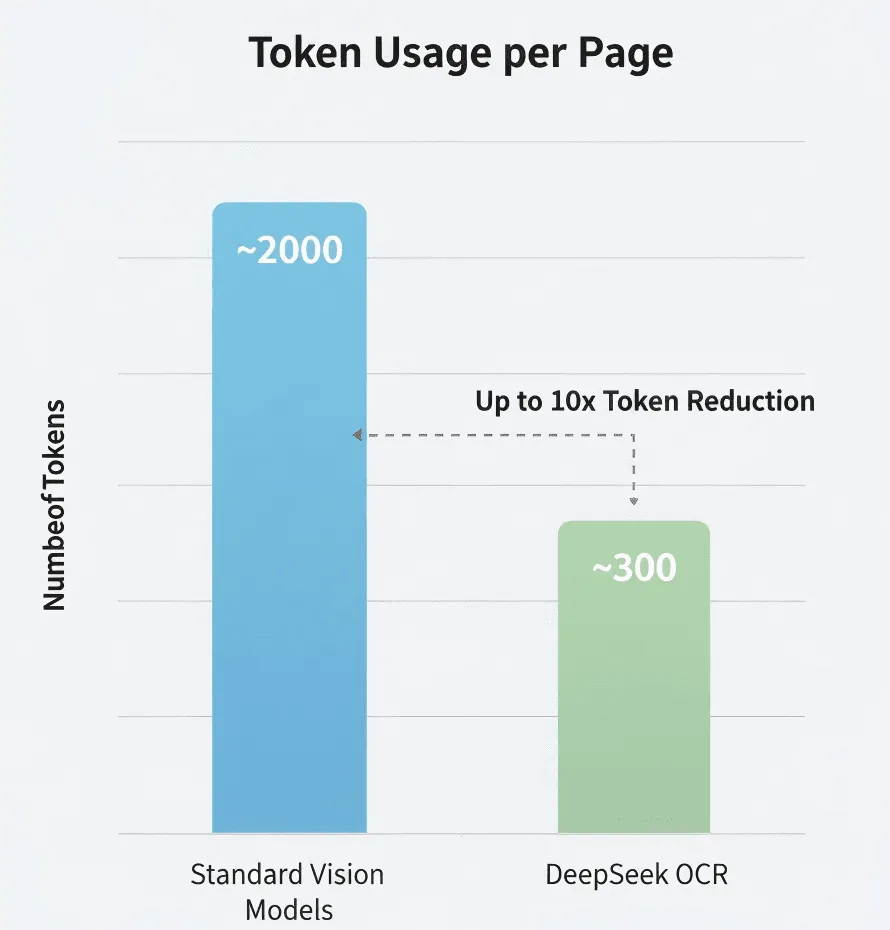
- 普通视觉模型:~2,000 token/页
- DeepSeek OCR:~300–400 token/页
- 压缩率:5–8倍
我没有独立验证这些数据,但如果大致准确,意义重大。
架构概览
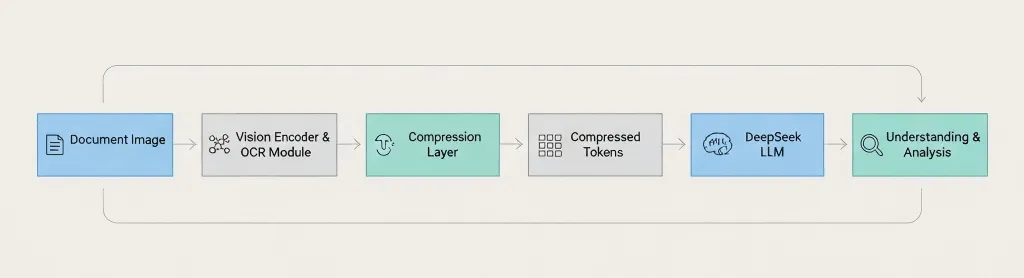
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis The key difference: DeepSeek compresses before passing to the language model, not after. 3. 其实际工作原理
处理流程大致如下:
步骤1:图片预处理
标准预处理包括分辨率增强、去噪、方向矫正、版面检测。
步骤2:文本识别
提取字符、段落、表格、页眉/页脚及格式线索。
步骤3:上下文压缩
语义分组相关文本,移除冗余token,高效编码结构,并保留版面信息。
步骤4:LLM集成
将压缩后的表示输入DeepSeek模型,用于问答、摘要、信息抽取和文档比对。
语言覆盖范围
应该支持英文、中文及主要欧洲语言。但建议实际测试你的目标语言后再投入使用。
手写体支持?
未有明确说明。官方博客主要关注印刷体。如果你需要手写OCR,Google Vision或Azure可能更可靠。
4. 应用能力介绍
支持的文档类型
- PDF(原生及扫描件)
- 图片:PNG、JPEG、TIFF
- 多页文档
- 复杂布局
功能亮点
- 高精度文本提取
- 结构和格式还原
- 表格及段落完整保留
- 基于LLM的上下文分析
可提出如下问题:
- “请总结第3节内容”
- “以JSON形式列出所有姓名和日期”
- “将这一版本与上一版对比”
- “标出所有风险声明”
可能不适合的情况
- 图片质量差或艺术字体
- 多语言混排(需事先测试)
- 数学公式
- 图表(仅支持文字标签)
5. 快速上手指南
重要提示: DeepSeek的API与OpenAI兼容,但要查看文档确认具体模型名称及参数。
安全提醒: 上传敏感文件至第三方API前,务必确保合规(如GDPR,HIPAA)。
你需要准备:
- DeepSeek API Key(可至deepseek.com注册获取)
- Python 3.8+或Node.js 14+
- API调用基础知识
开发环境配置
pip install openai pillow示例1:简单文本提取
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)示例2:文档问答
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)示例3:以JSON格式提取表格
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content示例4:先提升图片质量
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)效果提升小窍门
提示要具体。 比如用“提取发票号、日期、总金额”,而不是泛泛地说“提取信息”。
请使用高分辨率扫描件。 最好300 DPI及以上。注意光照均匀,无影。
关键数据务必校验。 切勿对采购金额、日期或法律条款等结果盲目信任OCR。
追踪你的使用情况。监控 tokens、延迟和错误率,以便你可以进行优化。
6. 真实世界的性能
我自己没有做过全面的基准测试,所以请保持适当的怀疑态度。
Token 压缩
DeepSeek 声称 token 数量比标准模型少 5–10 倍。如果准确的话,对于高频处理来说,这能大幅降低成本。
准确性
在清晰文本上可与主流 OCR 引擎媲美。遇到低质量扫描、特殊字体或退化文档时准确率会降低。
速度
我有限的测试中,大约每页 1–3 秒。实际速度会根据文档长度、图片质量和服务器负载有所不同。
成本效率
如果你按照 token 付费(像大多数 LLM API 一样),token 数量减少 5–10 倍意味着可以大大节省费用。但请查阅 DeepSeek 实际的价格信息——我没有当前的费率资料。
7. 什么时候应该用这个而不是传统 OCR?
在以下情况下使用 DeepSeek OCR:
- 你在处理长文档(20+ 页)
- 你需要 AI 理解,而不仅仅是文本提取
- 你有成本考量(高频处理)
- 你追求简单(无需分段逻辑)
在以下情况下使用传统 OCR:
- 你只需要文本提取(无需 AI 分析)
- 隐私极为关键(不能发送到外部 API)→ 请用 Tesseract
- 你需要特殊功能(手写、表单)→ 可选 Google Vision 或 AWS Textract
- 预算为零 → 使用 Tesseract(免费、开源)
快速对比
需求 | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
长文档(50+ 页) | 优秀 | 可用(无 AI) | 需分段 | 需分段 |
AI 理解 | 内置 | 无 | 需另购服务 | 需另购服务 |
成本(高频) | 高效 | 免费 | 可能昂贵 | 可能昂贵 |
隐私/本地部署 | 仅云端 | 自托管 | 仅云端 | 仅云端 |
手写识别 | 未知 | 有限 | 良好 | 良好 |
表格 | 良好 | 基础 | 良好 | 优秀 |
8. 实际应用
法律文档分析
一次性处理完整合同。可以提问如“终止条款有哪些?”或“识别潜在风险”。AI 可以通览全合同,保持全局上下文。
论文评审
从多篇论文中提取主要结论、比较方法、生成文献综述摘要。这不会取代你实际读论文,但能加快初步筛查速度。
财报处理
自动提取所有财务表格,转为结构化数据,识别报告期内的趋势。务必核查提取的财务数据,不要仅依赖 AI 给出的关键数字。
文档数字化项目
批量处理历史文献,生成可检索文本,自动提取元数据。虽然仍需时间,但上下文压缩令效率提升。
发票与小票处理
自动从发票中提取结构化数据(供应商名称、发票号、日期、项目明细、合计),并对接到财务系统。对于超大批量场景,AWS Textract 可能更专业一些。
可能不适用的场景
医疗记录 - 涉及 HIPAA 合规、准确性要求、高法律风险。
历史文献 - 字迹模糊、字体特殊、页面损坏时可能需要专业 OCR。
手写笔记 - 即使有手写支持,效果可能不是主要优势。
实时处理 - 如果需要亚秒级响应,OCR + LLM 可能过慢。
9. 使用技巧和最佳实践
图片质量很重要
对于纸质文件:
- 扫描时至少使用300 DPI
- 尽可能使用平板扫描仪
- 确保光线均匀(无阴影或眩光)
- 将页面完全压平
对于手机拍照:
- 使用良好光线(自然光效果最佳)
- 保持设备稳定
- 正面拍摄(避免倾斜)
- 如有不确定,多拍几张
在提示中要具体
含糊: "提取此文件中的信息。"
更好: "提取此发票中的所有文本,并保留表格结构。"
最佳: "以这个精确的JSON格式提取发票数据:{...}。如果找不到某个字段,请使用null。"
始终验证关键数据
永远不要盲目信任OCR输出用于:
- 金额
- 日期
- 姓名
- 法律术语
- 医疗信息
重要文件需有人复核流程。
用真实文件进行测试
不要只用完美的PDF测试。还要测试:
- 扫描件
- 手机拍摄的照片
- 低质量图片
- 有咖啡渍的文件
- 有皱褶的页面
你的生产数据不会完美,你的测试也不应如此。
设定合理预期
OCR并不完美,即使有AI:
- 干净文件期待有95-99%准确率
- 较差质量期待85-95%
- 关键数据预计需人工复查
- 为错误处理预留时间
准备备选方案
API可能失败,网络可能掉线,服务可能变更。请准备应急措施:
- 尽量缓存结果
- 实现重试逻辑
- 考虑备用OCR服务
- 将关键文档备份保存
10. 你应该了解的局限性
上下文窗口依然有限制
压缩有帮助,但你无法处理无限量文档。500页的书仍需分批处理。
准确率并非完美
没有任何OCR系统能做到100%准确。遇到特殊字体、图片质量差、复杂布局、混合语言、手写内容时,请预期会有错误。
它不是魔法
AI可以提取和理解文本,但无法读取真正无法辨认的内容,无法理解它未训练过的上下文,也无法修复根本性的图片质量问题。
成本因素
虽然Token压缩能降低费用,但你仍需支付API调用次数、Token使用量和处理时间。高并发量时,成本会累积。
隐私与合规
将文件发送到外部API意味着数据离开你的基础设施,受制于服务提供商的条款。可能无法满足某些合规要求(如HIPAA、GDPR等)。
请仔细阅读DeepSeek的隐私政策与合规认证。
API依赖
你将依赖DeepSeek的API可用性、频率限制、价格调整及服务连续性。要有备选预案。
语言支持未知
DeepSeek尚未公布完整的语言支持细节。如果你需要处理小众语言、从右到左书写的文字或复杂文字(如天城文、泰文等),请务必充分测试。
无离线选项
与Tesseract不同,你无法离线使用DeepSeek OCR。需要联网、API访问,并确保延迟可接受。
11. 常见问题
DeepSeek OCR多少钱?
我没有最新价格信息。请查看DeepSeek官网获取最新价格。很可能是按Token计费,和其他LLM API类似。
可以免费使用吗?
DeepSeek可能提供免费套餐或试用。请查阅官网。
它和Google Vision有什么区别?
适用场景不同。DeepSeek OCR更适合需要AI理解的长文档;Google Vision更擅长手写体和除文字外的图像分析。
上下文压缩是有损的吗?会丢失信息吗?
可以认为它是一种智能有损压缩。它保留核心语义、结构和重点信息,但可能丢弃冗余的视觉细节或非关键格式线索。目标不是像素级还原,而是让LLM更高效准确地理解文档。
它和ZIP压缩有何不同?
完全不同。ZIP是无损的文件压缩,可减少存储体积。解压后能得完全一致的副本。但LLM处理时仍然要处理完整、未压缩的文本,消耗大量Tokens。
DeepSeek的上下文压缩属于语义压缩。它减少传递至LLM进行分析的Tokens,从而降低AI算力消耗,适应上下文窗口。
必须用DeepSeek自己的LLM吗?
是的。上下文压缩与DeepSeek的语言模型深度集成。这种压缩Token格式是专有的,仅为DeepSeek模型特制。你不能直接将这些压缩Tokens用于GPT-4或Claude。
压缩对只含文字的简单图片还有效吗?
效果不那么明显。这项技术在结构复杂、文本与图片混杂以及有大量空白的文档上表现最佳。对于单纯的大段文本,Token数量可能与传统OCR类似,但仍能从精简、集成的API调用中获益。
处理100页PDF大致需要多少时间和费用?
时间:公开数据表明,平均每页几秒钟。
费用:如果传统Vision-LLM每页需要2,000个Token,而DeepSeek OCR仅需300,那么100页文件的总Token成本可能仅为传统方法的15%。但请查阅DeepSeek官方价格获取准确数据。
能理解图表、曲线、流程图吗?
文本元素(标题、坐标轴标签、图例)提取非常好。但无法像“哪根柱子最高?”、“流程图下一步是什么?”这样识别图表本身的视觉逻辑。更高级的多模态模型更适合这类任务。
若文档质量很差会怎样?
和所有OCR一样,输入质量直接决定输出质量。虽然DeepSeek OCR包含图像预处理,可应付部分噪声,但严重的伪影、模糊或分辨率过低都会显著降低准确率。请始终使用300DPI或更高质量的扫描件。
结语
DeepSeek OCR的上下文压缩不花哨,非常实用。
它降低成本、简化架构,终于让用LLM端到端分析长文档变得现实。
它不会取代所有OCR工具。Tesseract和Google Vision在隐私敏感或手写场景下仍有优势。但对于可扩展的AI辅助文件理解,DeepSeek的方法的确是前进了一大步。
可以用你最长的文件试试看。如果一次能处理并给出连贯的答案,你会立即感受到区别。
资源:
- DeepSeek OCR 博客文章
- The Decoder: DeepSeek的OCR压缩
- DeepSeek API文档(官方网站)
免责声明: 本文基于公开信息及有限个人测试,生产使用前请始终查阅官方文档确认细节。