DeepSeek OCR: Um Guia Prático da Tecnologia de Compressão de Contexto (2025)
Última atualização: 2026-01-22 18:05:30

Última atualização: 22 de outubro de 2025
Se você tem acompanhado os avanços em IA recentemente, provavelmente já ouviu falar do novo sistema OCR da DeepSeek. O que chamou minha atenção não foi apenas mais uma afirmação de "conseguimos ler textos de imagens", mas como eles abordaram uma limitação real e cara: processar documentos longos sem ultrapassar seu orçamento de tokens.
Este guia explica o que o DeepSeek OCR faz de diferente, como funciona e se vale a pena usar em seus projetos.
Índice
- O Que Torna o DeepSeek OCR Diferente?(#what-makes-it-different)
- O Avanço em Compressão de Contexto(#context-compression)
- Como Ele Realmente Funciona(#how-it-works)
- O Que Você Pode Fazer Com Ele(#capabilities)
- Como Começar(#getting-started)
- Desempenho no Mundo Real(#performance)
- Quando Usar Este Versus OCR Tradicional?(#comparison)
- Aplicações Práticas(#applications)
- Dicas e Boas Práticas(#tips)
- Limitações Que Você Deve Conhecer(#limitations)
- Perguntas Comuns(#faq)
1. O Que Torna o DeepSeek OCR Diferente?
OCR por si só não é novidade ferramentas como Tesseract, Google Vision e AWS Textract existem há anos. Todos extraem texto muito bem.
O verdadeiro gargalo aparece quando você precisa que um modelo de IA entenda o documento, não apenas o transcreva.
O Problema dos Tokens
Enviar o resultado bruto de OCR para um modelo de linguagem amplo é ineficiente.
Imagine um contrato de 50 páginas:
- Você extrai o texto
- Tenta enviar para um LLM
- Você atinge o limite de contexto após três páginas
- Você começa a dividir, resumir e perder contexto
É frustrante, e já perdi horas exatamente com esse problema.
A Solução da DeepSeek
DeepSeek não trata OCR e compreensão como etapas separadas. O sistema deles realiza OCR e compressão semântica juntos.
Ao invés de despejar texto bruto, o DeepSeek OCR codifica significado e layout de forma compacta reduzindo o uso de tokens em 5–10×.
Um contrato de 50 páginas que antes exigia 100k tokens agora pode caber em 12k–15k.
Por que isso importa:
- Custo menor (menos tokens = inferência mais barata)
- Fluxo de trabalho mais simples (sem divisão manual)
- Melhor contexto (o modelo vê o documento inteiro)
- Processamento mais rápido (uma chamada de API ao invés de dezenas)
2. O Avanço em Compressão de Contexto
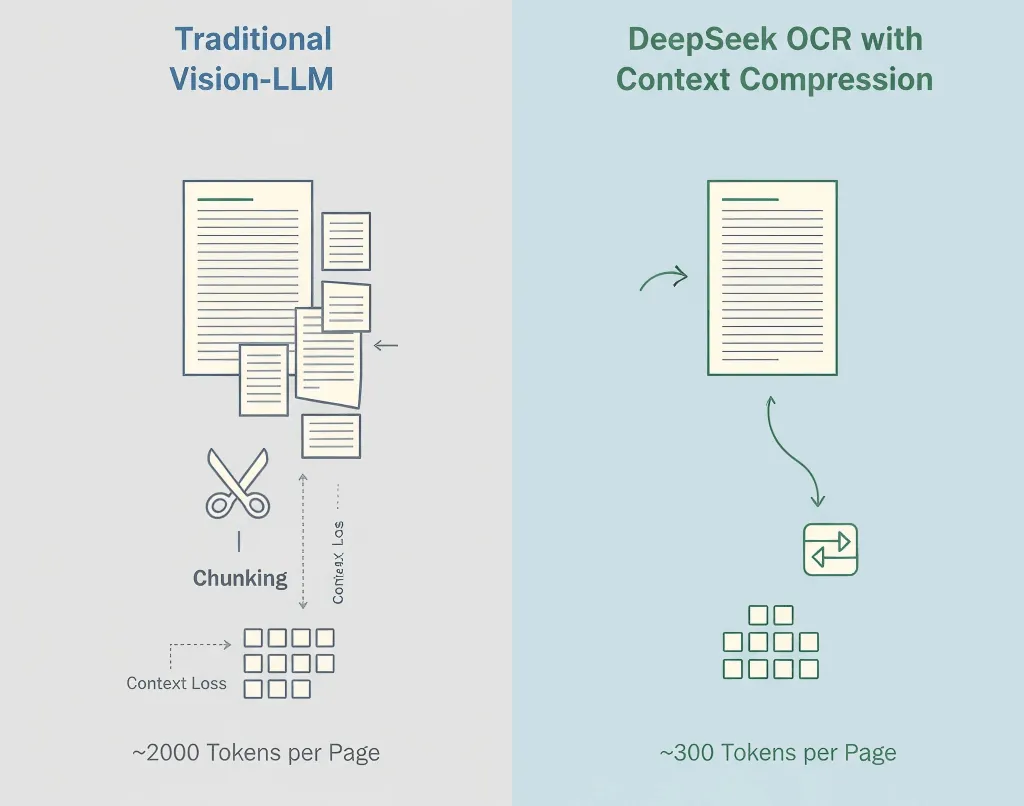
Modelos tradicionais de visão e linguagem transformam cada pedaço da imagem em tokens, muitas vezes 1.500–2.500 por página. A maioria desses tokens representa pixels, não significado.
Método da DeepSeek
- OCR Primeiro - Extrai texto, layout e tabelas
- Compressão Semântica - Converte o conteúdo reconhecido em tokens de linguagem eficientes
- Preservação da Estrutura - Mantém hierarquia, formatação e pistas visuais
- Compressão Adaptativa - Ajusta de acordo com a complexidade do documento
Os Números
Segundo pesquisa da DeepSeek:
- Modelo de visão padrão: ~2.000 tokens/página
- DeepSeek OCR: ~300–400 tokens/página
- Compressão efetiva: 5–8×
Não verifiquei isso de forma independente, mas se for próximo disso, é significativo.
Visão Geral da Arquitetura
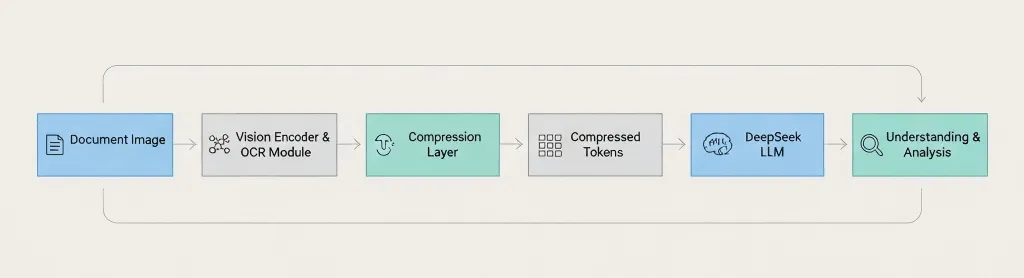
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis A principal diferença: DeepSeek comprime antes de passar para o modelo de linguagem, não depois. 3. Como Ele Realmente Funciona
O pipeline é dividido assim:
Passo 1: Processamento de Imagem
Pré-processamento padrão aprimoramento de resolução, redução de ruído, correção de orientação e detecção de layout.
Passo 2: Reconhecimento de Texto
Extrai caracteres, parágrafos, tabelas, cabeçalhos/rodapés e pistas de formatação.
Passo 3: Compressão de Contexto
Agrupa textos relacionados semanticamente, remove tokens redundantes, codifica a estrutura de forma eficiente e preserva o layout.
Passo 4: Integração com LLM
Envia as representações comprimidas ao modelo da DeepSeek para responder perguntas, resumir, extrair informações e comparar documentos.
Cobertura de Idiomas
Inglês, chinês e principais idiomas europeus provavelmente são suportados. Mas teste com seu idioma específico antes de decidir.
Manuscrito?
Não confirmado. O post do blog foca em texto impresso. Se você precisa de OCR para escrita manual, o Google Vision ou Azure provavelmente são apostas mais seguras.
4. O Que Você Pode Fazer Com Ele
Tipos de Documentos Suportados
- PDFs (nativos & escaneados)
- Imagens: PNG, JPEG, TIFF
- Documentos multipágina
- Layouts complexos
Capacidades
- Extração de texto com alta precisão
- Preserva estrutura e formatação
- Preservação de tabelas e parágrafos
- Análise contextual via LLM
Você Pode Perguntar Coisas Como:
- "Resuma a seção 3"
- "Liste todos os nomes e datas em JSON"
- "Compare esta versão com a anterior"
- "Destaque todas as declarações de risco"
O Que Provavelmente Não Consegue Processar
- Baixa qualidade de imagem ou fontes artísticas
- Layouts de idiomas mistos (teste antes)
- Equações matemáticas
- Diagramas ou gráficos (somente rótulos de texto)
5. Como Começar
Importante: A API da DeepSeek é compatível com OpenAI, mas verifique a documentação para os nomes de modelo e parâmetros exatos.
Lembrete de segurança: Sempre verifique conformidade (GDPR, HIPAA) antes de enviar documentos sensíveis para APIs de terceiros.
O Que Você Vai Precisar
- Uma chave de API DeepSeek (cadastre-se em deepseek.com)
- Python 3.8+ ou Node.js 14+
- Noções básicas de chamadas de API
Configuração do Desenvolvedor
pip install openai pillowExemplo 1: Extração Simples de Texto
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Exemplo 2: Faça Perguntas Sobre um Documento
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Exemplo 3: Extraia Tabelas em JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentExemplo 4: Melhore a Qualidade da Imagem Primeiro
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Dicas para Melhores Resultados
Seja específico em seus prompts. Ao invés de "extrair informações", diga "extraia número da nota fiscal, data e valor total."
Use digitalizações em alta resolução. Mínimo de 300 DPI. Boa iluminação. Sem sombras.
Sempre valide dados críticos. Não confie cegamente no OCR para valores financeiros, datas ou termos legais.
Acompanhe seu uso. Monitore tokens, latência e taxas de erro para poder otimizar.
6. Desempenho no Mundo Real
Eu mesmo não realizei benchmarks abrangentes, então receba essas informações com o devido ceticismo.
Compressão de Tokens
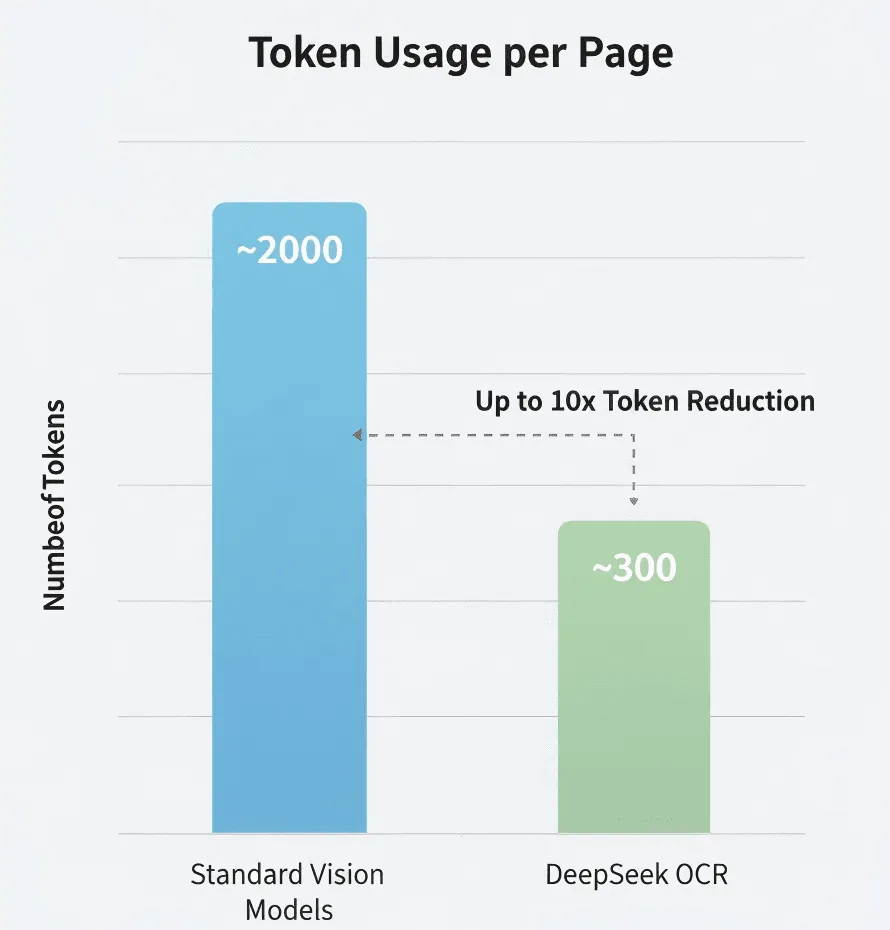
A DeepSeek afirma usar 5–10× menos tokens do que modelos padrão. Se isso for preciso, é uma grande redução de custos para processamento em grande escala.
Precisão
Comparável aos principais mecanismos de OCR em textos limpos. A precisão diminui em digitalizações de baixa qualidade, fontes incomuns ou documentos degradados.
Velocidade
Aproximadamente 1–3 segundos por página nos meus testes limitados. O seu resultado pode variar dependendo do tamanho do documento, qualidade da imagem e carga do servidor.
Eficiência de Custos
Se você paga por token (como na maioria das APIs de LLM), usar 5–10× menos tokens significa grande economia. Mas confira os preços atuais da DeepSeek, pois não possuo informações de tarifas atualizadas.
7. Quando Usar Este vs. OCR Tradicional?
Use DeepSeek OCR Quando:
- Você está processando documentos longos (20+ páginas)
- Você precisa de compreensão por IA, não apenas extração de texto
- Custo é uma preocupação (processamento em grande volume)
- Você quer simplicidade (sem lógica de divisão em partes)
Use OCR Tradicional Quando:
- Você só precisa da extração de texto (sem análise de IA)
- Privacidade é fundamental (não pode enviar para APIs externas) → use Tesseract
- Você precisa de recursos especializados (escrita manual, formulários) → Google Vision ou AWS Textract
- O orçamento é zero → use Tesseract (gratuito, open source)
Comparação Rápida
Necessidade | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Documentos longos (50+ páginas) | Excelente | Funciona (sem IA) | Precisa dividir | Precisa dividir |
Compreensão por IA | Integrado | Nenhuma | Serviço separado | Serviço separado |
Custo (alto volume) | Eficiente | Gratuito | Pode ser caro | Pode ser caro |
Privacidade/instalação local | Apenas na nuvem | Auto-hospedado | Apenas na nuvem | Apenas na nuvem |
Escrita manual | Desconhecido | Limitado | Bom | Bom |
Tabelas | Bom | Básico | Bom | Excelente |
8. Aplicações Práticas
Análise de Documentos Jurídicos
Processe contratos inteiros de uma vez só. Faça perguntas como "Quais são as cláusulas de rescisão?" ou "Identifique riscos potenciais." A IA enxerga o contrato inteiro, mantendo o contexto entre as seções.
Revisão de Artigos Científicos
Extraia descobertas-chave de vários artigos, compare metodologias, gere resumos de revisão da literatura. Isso não substitui a leitura dos artigos, mas agiliza a triagem inicial.
Processamento de Relatórios Financeiros
Extraia todas as tabelas financeiras automaticamente, converta em dados estruturados, identifique tendências entre os períodos de relatório. Sempre verifique os dados financeiros extraídos e não dependa só da IA para números críticos.
Projetos de Digitalização de Documentos
Processe em lote documentos históricos, gere textos pesquisáveis, extraia metadados automaticamente. Ainda leva tempo, mas a compactação de contexto torna tudo mais eficiente.
Processamento de Notas Fiscais e Recibos
Extraia automaticamente dados estruturados de notas fiscais (nome do fornecedor, número da nota, data, itens, totais) e mande para sistemas de contabilidade. Para volumes muito altos, o AWS Textract pode ser ainda mais especializado.
O Que Provavelmente Não Vai Funcionar Bem
Prontuários médicos - Questões de conformidade com HIPAA, exigências de precisão, responsabilidade.
Documentos históricos - Texto apagado, fontes incomuns, páginas danificadas podem exigir OCR especializado.
Anotações manuscritas - Mesmo se houver suporte para manuscrito, provavelmente não é o ponto mais forte.
Processamento em tempo real - Se você precisa de respostas em fração de segundo, OCR + LLM pode ser lento demais.
9. Dicas e Melhores Práticas
A Qualidade da Imagem Importa
Para documentos físicos:
- Digitalize com no mínimo 300 DPI
- Use um scanner de mesa sempre que possível
- Garanta iluminação uniforme (sem sombras ou reflexos)
- Deixe as páginas totalmente planas
Para fotos de celular:
- Use boa iluminação (luz natural é melhor)
- Segure o aparelho firme
- Fotografe diretamente (evite ângulos)
- Tire várias fotos se estiver em dúvida
Seja Específico nos Seus Prompts
Vago: "Extraia informações deste documento."
Melhor: "Extraia todo o texto desta fatura, preservando a estrutura da tabela."
Melhor ainda: "Extraia os dados da fatura neste formato exato de JSON: {...}. Se algum campo não for encontrado, use null."
Sempre Valide Dados Críticos
Nunca confie cegamente na saída do OCR para:
- Valores financeiros
- Datas
- Nomes
- Termos legais
- Informações médicas
Tenha um processo de revisão humana para documentos importantes.
Teste com Documentos Reais
Não teste apenas com PDFs perfeitos. Teste com:
- Documentos digitalizados
- Fotos tiradas com celulares
- Imagens de baixa qualidade
- Documentos com manchas de café
- Páginas amassadas
Seus dados de produção não serão perfeitos. Seus testes também não devem ser.
Defina Expectativas Realistas
O OCR não é perfeito. Mesmo com IA:
- Espere de 95-99% de precisão em documentos limpos
- Espere de 85-95% em qualidade ruim
- Espere precisar de revisão humana para dados críticos
- Reserve tempo para tratamento de erros
Tenha um Plano de Contingência
APIs falham. Redes caem. Serviços mudam. Tenha um plano alternativo:
- Armazene resultados em cache quando possível
- Implemente lógica de re-tentativa
- Considere um serviço OCR alternativo
- Mantenha documentos críticos em backup
10. Limitações Que Você Deve Saber
Janelas de Contexto Ainda Têm Limites
A compressão ajuda, mas você não pode processar documentos infinitos. Livros de 500 páginas ainda precisam ser divididos em lotes.
A Precisão Não é Perfeita
Nenhum sistema de OCR é 100% preciso. Espere erros com fontes incomuns, baixa qualidade de imagem, layouts complexos, idiomas mistos e texto manuscrito.
Não é Mágica
A IA consegue extrair e entender texto, mas não pode ler texto genuinamente ilegível, entender contextos para os quais não foi treinada ou corrigir problemas fundamentais de qualidade de imagem.
Considerações de Custo
Embora a compressão de tokens reduza custos, você ainda paga por chamadas à API, uso de tokens e tempo de processamento. Para volumes extremamente altos, os custos podem somar bastante.
Privacidade e Conformidade
Enviar documentos para APIs externas significa que os dados saem da sua infraestrutura e ficam sujeitos aos termos de serviço do fornecedor. Pode não atender certos requisitos de conformidade (HIPAA, GDPR, etc.).
Revise cuidadosamente a política de privacidade da DeepSeek e suas certificações de conformidade.
Dependência de API
Você depende da disponibilidade da API da DeepSeek, limites de taxa, mudanças de preço e continuidade do serviço. Tenha um plano de contingência.
Suporte a Idiomas Desconhecido
A DeepSeek não publicou detalhes abrangentes sobre suporte a idiomas. Se você precisa de OCR para idiomas menos comuns, escrituras da direita para a esquerda ou scripts complexos (Devanagari, Tailandês, etc.), teste cuidadosamente.
Sem Opção Offline
Diferente do Tesseract, você não pode rodar o DeepSeek OCR offline. É necessário conexão com a internet, acesso à API e latência aceitável.
11. Perguntas Comuns
Quanto custa o DeepSeek OCR?
Não tenho o preço atual. Consulte o site da DeepSeek para ver as tarifas mais recentes. Provavelmente é baseado em tokens, similar a outras APIs LLM.
Posso usar gratuitamente?
A DeepSeek pode oferecer um plano gratuito ou teste. Confira no site deles.
Como se compara ao Google Vision?
São casos de uso diferentes. DeepSeek OCR é melhor para documentos longos que exigem compreensão por IA. Google Vision é melhor para análise de manuscritos e imagens além do texto.
A compressão de contexto é com perda? Perde informações?
Pense nisso como uma compressão inteligente com perda. Ela preserva o significado central, estrutura e informações-chave, mas pode descartar detalhes visuais redundantes ou indicações de formatação que não são essenciais para a compreensão. O objetivo não é reconstrução perfeita de pixels, mas permitir que o LLM entenda o documento de forma eficiente e precisa.
Como isso é diferente da compressão ZIP?
Totalmente diferente. ZIP é uma compressão de arquivos sem perda que reduz o tamanho de armazenamento. Ao descompactar, você tem uma cópia idêntica. Mas um LLM ainda precisa processar todo o texto descompactado, usando muitos tokens.
A compressão de contexto da DeepSeek é uma compressão semântica. Ela reduz os tokens enviados ao LLM para análise, diminuindo os custos de computação da IA e permitindo que caiba dentro das janelas de contexto.
Preciso usar o LLM da própria DeepSeek?
Sim. A compressão de contexto é profundamente integrada aos modelos de linguagem da DeepSeek. O formato de token compactado é proprietário e desenvolvido especificamente para os modelos DeepSeek. Não é possível utilizar esses tokens compactados no GPT-4 ou Claude.
A compressão ainda é eficaz em imagens simples, só com texto?
Menos dramático. A tecnologia se destaca em documentos com layouts complexos, mistura de texto e imagens e muito espaço em branco. Para um bloco simples de texto, a contagem de tokens pode ser semelhante ao OCR tradicional, mas ainda é vantajoso pelo chamado em API mais simples e completo.
Qual o tempo e custo estimado para processar um PDF de 100 páginas?
Tempo: Alguns segundos por página, em média, com base em dados públicos.
Custo: Se um sistema tradicional Vision-LLM precisa de 2.000 tokens por página e o DeepSeek OCR usa 300, o custo total de tokens para um documento de 100 páginas pode ser apenas 15% do método tradicional. Mas confira o preço oficial da DeepSeek para valores exatos.
Ele entende gráficos, tabelas ou diagramas?
É excelente na extração de componentes textuais (títulos, rótulos de eixos, legendas). Mas não consegue interpretar logicamente o gráfico, como "Qual barra é a mais alta?" ou "Qual o próximo passo neste fluxograma?" Modelos multimodais mais avançados são melhores para essas tarefas.
O que acontece se meu documento estiver com qualidade ruim?
Como todo OCR, a qualidade da entrada impacta diretamente a saída. Apesar do DeepSeek OCR incluir pré-processamento de imagem para lidar com certo ruído, artefatos severos, desfoque ou baixa resolução diminuirão significativamente a precisão. Sempre utilize digitalizações de alta qualidade, 300 DPI ou mais.
Considerações Finais
A compressão de contexto do DeepSeek OCR não é chamativa — é prática.
Reduz custos, simplifica a arquitetura e finalmente torna realista analisar documentos longos de ponta a ponta com um LLM.
Não vai substituir toda ferramenta de OCR. Tesseract e Google Vision ainda são melhores em casos com privacidade sensível ou manuscritos. Mas para compreensão de documentos com apoio de IA em escala, a abordagem da DeepSeek é um avanço real.
Teste com seu documento mais longo. Se couber em uma única passagem e der respostas coerentes, você verá a diferença na hora.
Recursos:
- Post no blog DeepSeek OCR
- The Decoder: DeepSeek's OCR Compression
- DeepSeek API Docs (site oficial)
Aviso legal: Este artigo é baseado em dados publicamente disponíveis e testes pessoais limitados. Sempre confirme os detalhes na documentação oficial antes de usar em produção.