DeepSeek OCR: コンテキスト圧縮技術の実践ガイド(2025)
最終更新日: 2026-01-22 18:05:30

最終更新日: 2025年10月22日
最近のAIの進展を追っている方なら、DeepSeekの新しいOCRシステムについて耳にしたことがあるでしょう。私が注目したのは、単なる「画像からテキストが読める」という話ではなく、長いドキュメントをトークン制限を超えずに処理するという、現実的かつコストのかかる制約にどう取り組んだかという点です。
このガイドでは、DeepSeek OCRの特徴、仕組み、そしてプロジェクトで使う価値があるのかを分かりやすく解説します。
目次
- DeepSeek OCRが他と違う点(#what-makes-it-different)
- コンテキスト圧縮技術のブレイクスルー(#context-compression)
- 実際の仕組み(#how-it-works)
- できること(#capabilities)
- 始め方(#getting-started)
- 実運用でのパフォーマンス(#performance)
- 従来のOCRとどう使い分けるべきか(#comparison)
- 実践的な応用例(#applications)
- コツとベストプラクティス(#tips)
- 知っておきたい制限事項(#limitations)
- よくある質問(#faq)
1. DeepSeek OCRが他と違う点
OCR自体は決して新しい技術ではありません。TesseractやGoogle Vision、AWS Textractなどのツールは何年も前から存在しています。それらはどれも十分にテキスト抽出ができます。
しかし、本当のボトルネックは、単にテキスト化するだけでなく、AIモデルがドキュメントを理解する必要がある場面で現れます。
トークン問題
生のOCR結果を大規模言語モデルへそのまま入力するのは非効率です。
例えば、50ページの契約書を考えてみてください:
- テキストを抽出する
- LLMに送ろうとする
- 3ページ目でコンテキスト制限に達する
- チャンク分割や要約を始め、コンテキストが失われる
本当にイライラしますし、私自身何度もこの問題で時間を浪費しました。
DeepSeekのソリューション
DeepSeekはOCRと理解工程を分けて考えません。彼らのシステムは、OCRと意味的圧縮を同時に実行します。
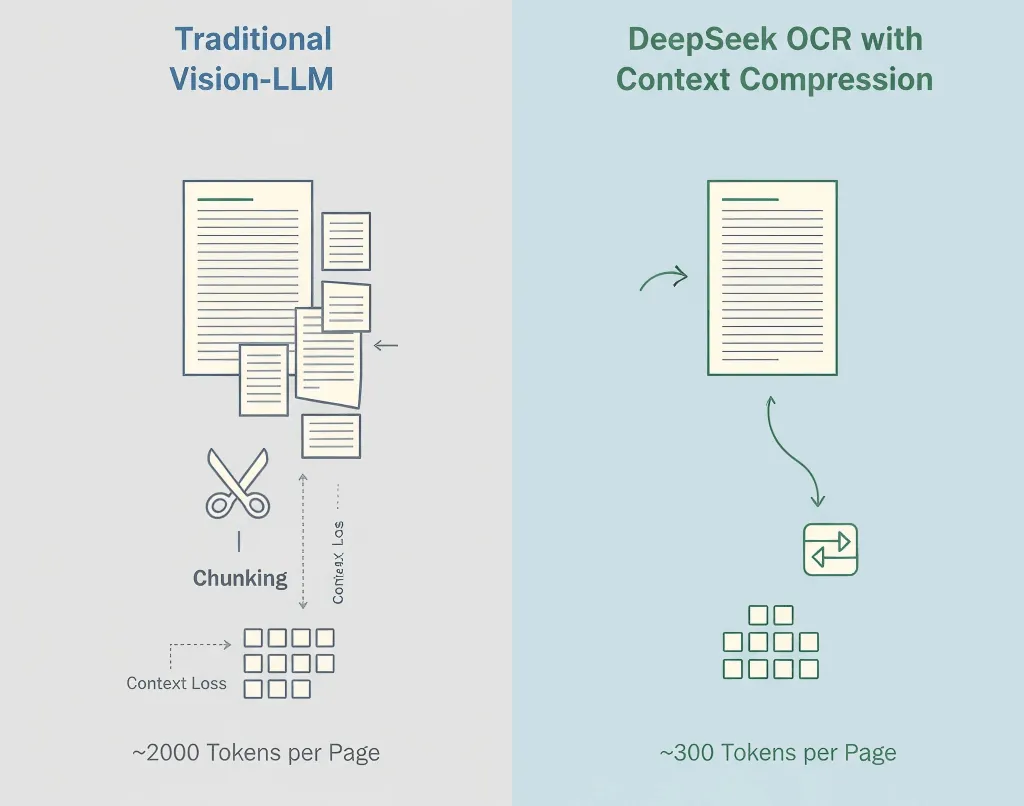
生テキストをそのまま出力するのではなく、DeepSeek OCRは意味とレイアウトをコンパクトな形で符号化し、トークン使用量を5〜10倍削減します。
これまで100,000トークン必要だった50ページの契約書が、今では12,000〜15,000トークンで収まります。
なぜ重要なのか:
- コスト削減(トークン数減=推論コスト安)
- ワークフローが簡単(手作業でのチャンク分割不要)
- より広いコンテキスト(一括で全ドキュメントを参照可能)
- 高速処理(多数のAPIコールが不要に)
2. コンテキスト圧縮技術のブレイクスルー
従来のビジョン・ランゲージモデルは、画像の各パッチを1,500~2,500トークン(1ページあたり)に変換します。その多くは「意味」ではなくピクセルを表しています。
DeepSeekの手法
- まずOCR—テキスト、レイアウト、テーブルを抽出
- 意味的圧縮—検出した内容を効率的な言語トークンへ変換
- 構造維持—階層・書式・視覚的手がかりを保持
- 適応圧縮—ドキュメントの複雑さに応じて圧縮率を調整
数値で見る
DeepSeekの調査によると:
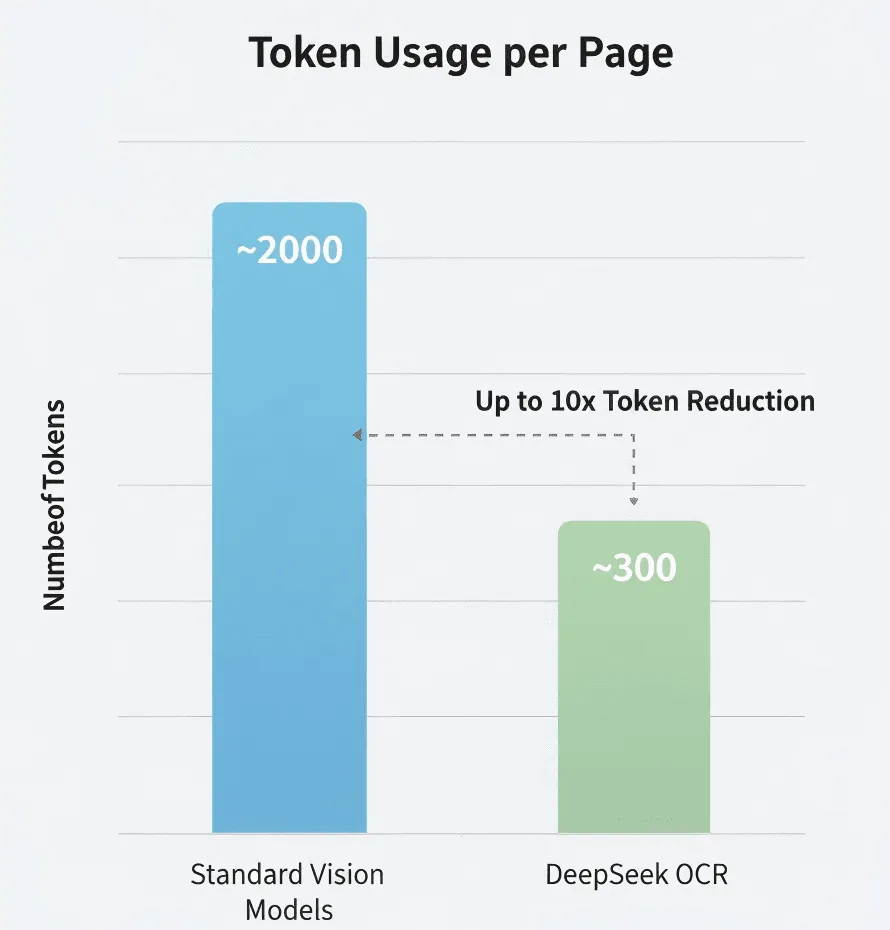
- 標準的なビジョンモデル:約2,000トークン/ページ
- DeepSeek OCR:約300〜400トークン/ページ
- 圧縮効率:5〜8倍
私自身が独立して検証したわけではありませんが、仮にこの近くの数値だとしても非常に大きな差です。
アーキテクチャ全体像
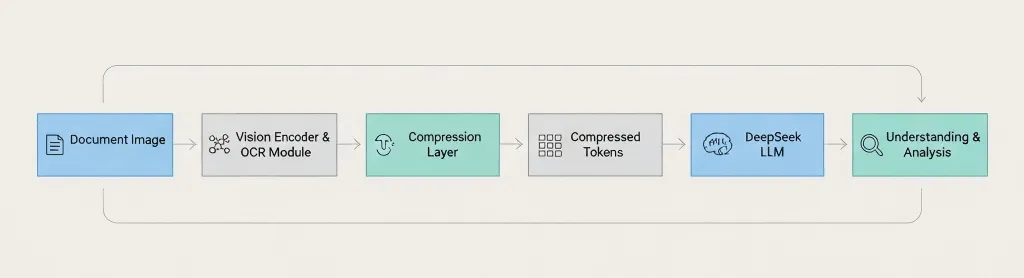
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis The key difference: DeepSeek compresses before passing to the language model, not after. 3. 実際の仕組み
パイプラインの流れは次の通りです:
ステップ1: 画像処理
標準的な前処理(解像度向上、ノイズ除去、傾き補正、レイアウト検出など)
ステップ2: 文字認識
文字、段落、テーブル、ヘッダー/フッターや書式情報を抽出
ステップ3: コンテキスト圧縮
関連するテキストを意味的にまとめ、冗長なトークンを削除し、効率的に構造をエンコードしながらレイアウト情報も保持します。
ステップ4: LLM統合
圧縮表現をDeepSeekモデルに投入し、QA、要約、情報抽出、ドキュメント比較などを実行します。
対応言語
英語、中国語、および主要な欧州言語に対応している可能性が高いですが、導入の前にご自身の利用言語でテストしてみてください。
手書き文字対応?
未確認です。ブログ記事では印刷文字にフォーカスしています。手書きOCRが必要な場合はGoogle VisionやAzureの方が安心かもしれません。
4. できること
対応ドキュメント形式
- PDF(ネイティブ & スキャン)
- 画像形式:PNG、JPEG、TIFF
- 複数ページのドキュメント
- 複雑なレイアウト
主な機能
- 高精度なテキスト抽出
- 構造と書式の保持
- テーブルや段落構造の再現
- LLMによるコンテキスト認識型分析
こんな問いかけが可能です:
- 「セクション3を要約して」
- 「全ての氏名と日付をJSONで一覧にして」
- 「このバージョンと前のバージョンを比較して」
- 「すべてのリスク記述をハイライトして」
おそらく不得意なこと
- 画像品質が悪い場合や装飾的フォント
- 複数言語混在レイアウト(まずはテストを推奨)
- 数式問題
- 図表やチャート(テキストラベルのみ認識)
5. 始め方
重要: DeepSeekのAPIはOpenAI互換ですが、モデル名やパラメータの詳細は公式ドキュメントを必ずご確認ください。
セキュリティ注意: 機密ドキュメントを外部APIにアップロードする前に、必ずGDPRやHIPAA準拠状況をご確認ください。
必要なもの
- DeepSeek APIキー(deepseek.comで登録)
- Python 3.8+ または Node.js 14+
- APIコールの基礎知識
開発環境セットアップ
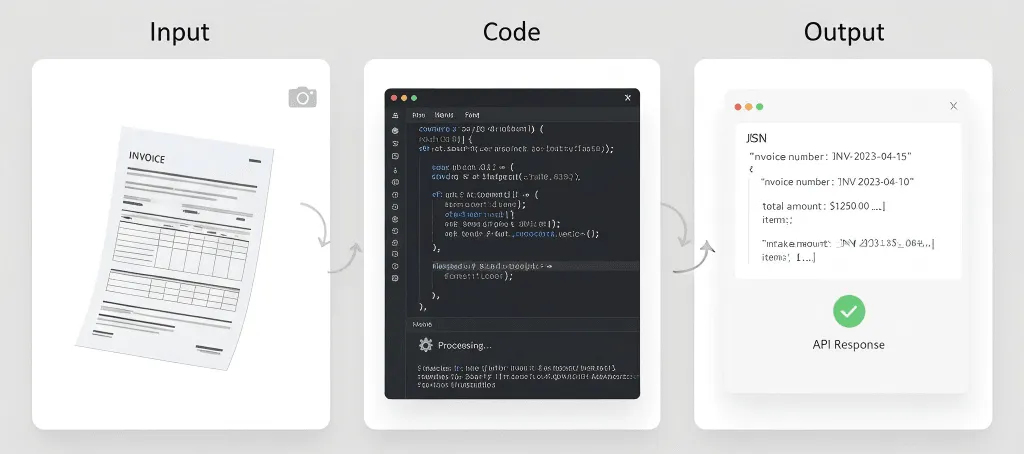
pip install openai pillow例1:シンプルなテキスト抽出
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)例2:ドキュメントに質問を投げる
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)例3:テーブルをJSONで抽出
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content例4:まず画像品質を向上させる
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)より良い結果のためのコツ
プロンプトは具体的に。 「情報を抽出」ではなく「請求書番号、日付、合計金額を抽出」と指定しましょう。
高解像度のスキャンを使いましょう。 300 DPI以上、明るい場所、影が入らないように。
重要なデータは必ず検証。 金額や日付、法的記載などはOCR結果をそのまま鵜呑みにせず必ず確認しましょう。
使用状況を追跡しましょう。 トークン数、レイテンシ、エラー率を監視して最適化しましょう。
6. 実際のパフォーマンス
私自身で包括的なベンチマークを実施したわけではないので、適度な懐疑心を持ってご覧ください。
トークン圧縮
DeepSeekは標準モデルより5–10倍トークン数が少ないと主張しています。もし本当であれば、大量処理におけるコスト削減は大きなものです。
精度
きれいなテキストに関しては主要なOCRエンジンと同等の精度です。低品質なスキャン、珍しいフォント、劣化した文書では精度が下がります。
速度
私が限定的にテストした範囲では、1ページあたり約1〜3秒程度です。文書サイズ、画像品質、サーバー負荷によって時間は変動します。
コスト効率
トークンごとに課金される(多くのLLM APIのような)場合、5–10倍トークンが少ないのは大きな節約になります。ただしDeepSeekの実際の料金を確認してください。現在のレート情報は持っていません。
7. これを使うべきタイミングと従来型OCRの使い分け
DeepSeek OCRを使うべき場合:
- 20ページ以上の長い文書を処理する場合
- 単なるテキスト抽出以上にAIによる理解が必要な場合
- コストが重要(大量処理)
- よりシンプルにしたい(分割処理ロジック不要)
従来型OCRを使うべき場合:
- テキスト抽出だけが必要(AIによる解析不要)
- プライバシー重視(外部APIに送信できない)→Tesseractを使用
- 手書きや帳票などの特殊な機能が必要→Google VisionやAWS Textractを使用
- 予算ゼロ→Tesseract(無料・オープンソース)を使用
簡単な比較
必要事項 | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
長文書(50ページ以上) | 優秀 | 動作(AIなし) | 分割が必要 | 分割が必要 |
AIによる理解 | 組み込み | なし | 別サービス | 別サービス |
コスト(大量処理) | 効率的 | 無料 | 高額になる場合あり | 高額になる場合あり |
プライバシー/オンプレミス | クラウドのみ | セルフホスト | クラウドのみ | クラウドのみ |
手書き文書 | 不明 | 限定的 | 良好 | 良好 |
表 | 良好 | 基本的 | 良好 | 優秀 |
8. 実用的な活用例
契約書解析
契約書を一括で処理。例えば「契約解除条項は?」や「潜在リスクを特定せよ」などの質問ができます。AIが全体を把握し、各セクションの文脈も維持されます。
論文レビュー
複数の論文から主要な知見を抽出し、手法を比較し、文献レビューの要約を生成。実際に論文を読むことの代わりにはなりませんが、初期スクリーニングの効率が上がります。
財務報告書の処理
すべての財務表を自動抽出して構造化データへ変換し、複数期間の傾向を特定します。抽出された財務データは必ず検証し、重要な数値についてAIだけを信用しないでください。
文書のデジタル化プロジェクト
歴史的文書をバッチ処理して検索可能なテキストやメタデータを自動生成。多少時間はかかりますが、文脈圧縮の恩恵で効率的です。
請求書・領収書の処理
請求書から(会社名、請求書番号、日付、明細、合計金額など)の構造化データを自動抽出し、会計システムに流し込めます。大量処理の場合はAWS Textractの方が特化していることもあります。
あまり得意でない例
医療記録 - HIPAA準拠や高い精度、責任問題などの懸念。
歴史文書 - 薄れて読めない文字、珍しい書体、破損ページには特化型OCRが必要な場合があります。
手書きメモ - 手書き対応がある場合でも最も得意な機能ではない可能性が高いです。
リアルタイム処理 - 1秒未満の応答速度が必要ならOCR+LLMでは遅すぎる場合があります。
9. ヒントとベストプラクティス
画像の品質は重要です
紙の書類の場合:
- 最低300 DPIでスキャンする
- 可能ならフラットベッドスキャナーを使う
- 均一な照明を確保する(影や反射を避ける)
- ページを完全に平らにする
モバイル写真の場合:
- 良い照明を使う(自然光が最適)
- デバイスをしっかり固定する
- 真っ直ぐに撮影する(斜めを避ける)
- 不安な場合は複数枚撮影する
プロンプトは具体的に
曖昧:「このドキュメントから情報を抽出してください。」
より良い例:「この請求書からすべてのテキストを抽出し、テーブル構造を保持してください。」
最適:「この正確なJSON形式で請求書データを抽出してください: {...}。どの項目も見つからない場合はnullを使用してください。」
重要なデータは必ず確認を
OCRの出力を鵜呑みにしないでください。特に:
- 金額
- 日付
- 名前
- 法律用語
- 医療情報
重要な書類は必ず人間によるチェックプロセスを設けてください。
実際の書類でテストする
完璧なPDFだけでテストしないでください。次のようなものでテストしましょう:
- スキャン書類
- スマートフォンで撮った写真
- 低品質な画像
- コーヒー染みのある書類
- しわのあるページ
本番データは完璧ではありません。テストも同様にしましょう。
現実的な期待値を持つ
OCRは完璧ではありません。AIを活用しても:
- きれいな書類では95~99%の正確性に期待
- 品質が悪い場合は85~95%に
- 重要なデータには人間の確認が必要になることを想定
- エラー対応の時間も見積もっておく
バックアッププランを用意する
APIが失敗することもあります。ネットワーク障害やサービスの変更もあり得ます。備えておきましょう:
- 可能な場合は結果をキャッシュする
- リトライロジックを実装する
- 予備のOCRサービスを検討する
- 重要書類はバックアップを取る
10. 知っておくべき制限事項
コンテキストウィンドウには限界がある
圧縮によって助けられますが、無限の文書を処理できるわけではありません。500ページの本はやはり分割処理が必要です。
正確性は完璧ではない
どのOCRシステムも100%正確ではありません。珍しいフォント、画像品質の低さ、複雑なレイアウト、多言語、手書き文字では誤りが生じ得ます。
魔法ではない
AIはテキストの抽出や理解はできますが、本当に判読不能な文字、学習していない文脈、根本的な画像品質の問題は解決できません。
コストについて
トークン圧縮でコストは削減されますが、APIコール、トークン使用量、処理時間にはコストが発生します。超大量処理ではコストが増えます。
プライバシーとコンプライアンス
外部APIへ書類を送信することで、データが自社インフラ外に出てプロバイダの利用規約に従うことになります。特定のコンプライアンス要件(HIPAA、GDPR等)を満たさない場合があります。
DeepSeekのプライバシーポリシーやコンプライアンス認証を必ずご確認ください。
API依存
DeepSeekのAPIの可用性、レートリミット、価格変更、サービス継続性に依存することになります。バックアッププランを用意しましょう。
言語サポートは不明
DeepSeekは包括的な言語対応の詳細を公開していません。珍しい言語、右から左への文字、複雑なスクリプト(デーヴァナーガリー、タイ語など)が必要な場合は十分なテストが必要です。
オフラインオプションがない
Tesseractとは異なり、DeepSeek OCRはオフラインで実行できません。インターネット接続、APIアクセス、許容レイテンシが必要です。
11. よくある質問
DeepSeek OCRはいくらですか?
最新の価格情報は持っていません。DeepSeekのウェブサイトで最新の料金を確認してください。他のLLM APIのようにトークンベースの可能性が高いです。
無料で使えますか?
DeepSeekには無料枠やトライアルがあるかもしれません。公式サイトでご確認ください。
Google Visionと比べてどうですか?
用途が異なります。DeepSeek OCRは長文やAIによる文書理解が必要なケースに向いています。Google Visionは手書きやテキスト以外の画像解析に強みがあります。
コンテキスト圧縮はロスがある?情報は失われる?
知的なロス圧縮だと考えてください。本質的な意味や構造、重要情報は保持しつつ、余分な視覚的ディテールや理解に必須でないフォーマットは捨てる場合があります。目標はピクセル単位の再現性ではなく、LLMが効率的かつ正確に文書を理解できるようにすることです。
ZIP圧縮とどう違うの?
全く違います。ZIPはロスレスなファイル圧縮で、保存容量を減らします。解凍すれば元どおりになりますが、LLMは非圧縮のまま全テキストを処理するため大量のトークンが必要です。
DeepSeekのコンテキスト圧縮は意味的な圧縮です。LLMに送るトークン数を減らし、AIの計算コストを削減し、ウィンドウ内に収まるようにします。
DeepSeek独自のLLMを使う必要がある?
はい。コンテキスト圧縮はDeepSeekの言語モデルと密接に統合されています。圧縮トークン形式は独自仕様でDeepSeekモデル専用に設計されています。他のGPT-4やClaudeには使えません。
シンプルでテキストだけの画像でも圧縮は有効?
効果は控えめです。複雑なレイアウトやテキストと画像が混在した文書、大きな空白がある場合に本領を発揮します。シンプルなテキストのみの場合、トークン数は従来のOCRと同程度となることもありますが、一体型APIコールの恩恵は享受できます。
100ページのPDF処理にかかる推定時間と費用は?
時間:公表データによると平均で1ページ数秒程度。
コスト:従来型Vision-LLMが1ページ2,000トークンを消費するのに対し、DeepSeek OCRでは300トークンほど。本書類100ページだと従来の15%程度のコストになる場合も。正確な数値はDeepSeek公式の価格を確認してください。
チャート・グラフ・図は理解できる?
テキスト要素(タイトル、軸ラベル、凡例)抽出は得意です。ただし、「どの棒グラフが一番高いか」や「このフローチャートの次の工程は?」といった視覚的論理の解釈はできません。その場合は高度なマルチモーダルモデルが向いています。
書類の品質が低い場合はどうなりますか?
全てのOCR同様、入力品質が出力品質に直結します。DeepSeek OCRには画像の前処理機能があるものの、ひどいノイズやブレ、低解像度では精度が大きく落ちます。必ず300 DPI以上の高品質スキャンを使用してください。
まとめ
DeepSeek OCRのコンテキスト圧縮は派手さはありませんが、実用的です。
コストを削減し、システムの構成を簡素化し、長文書もLLMでエンドツーエンド解析が現実的になります。
すべてのOCRツールを置き換えるものではありません。TesseractやGoogle Visionはプライバシー重視や手書きには今でも有効です。しかしAIアシストによるスケーラブルな文書理解では、DeepSeekのアプローチは大きな一歩と言えるでしょう。
ぜひあなたの一番長い文書で試してみてください。一度で処理できて明確な回答が得られたら、その違いはすぐに実感できるはずです。
リソース:
- DeepSeek OCR ブログ記事
- The Decoder: DeepSeekのOCR圧縮
- DeepSeek API Docs(公式サイト)
免責事項: 本記事は公開情報および限定的な個人試験に基づいて執筆しています。必ず本番利用前に公式ドキュメントで詳細を確認してください。