DeepSeek OCR: Una guía práctica sobre su tecnología de compresión de contexto (2025)
Última actualización: 2026-01-22 18:05:30

Última actualización: 22 de octubre de 2025
Si has estado siguiendo los avances en IA últimamente, probablemente hayas oído hablar del nuevo sistema OCR de DeepSeek. Lo que llamó mi atención no fue solo otro "podemos leer texto de imágenes", sino cómo abordaron una limitación real y costosa: procesar documentos extensos sin agotar tu presupuesto de tokens.
Esta guía desglosa en qué se diferencia DeepSeek OCR, cómo funciona y si merece la pena usarlo en tus proyectos.
Índice
- ¿En qué se diferencia DeepSeek OCR?(#what-makes-it-different)
- El avance en compresión de contexto(#context-compression)
- Cómo funciona realmente(#how-it-works)
- Qué puedes hacer con él(#capabilities)
- Primeros pasos(#getting-started)
- Rendimiento en el mundo real(#performance)
- ¿Cuándo deberías usar esto vs. OCR tradicional?(#comparison)
- Aplicaciones prácticas(#applications)
- Consejos y mejores prácticas(#tips)
- Limitaciones que debes conocer(#limitations)
- Preguntas frecuentes(#faq)
1. ¿En qué se diferencia DeepSeek OCR?
El reconocimiento óptico de caracteres no es nuevo: herramientas como Tesseract, Google Vision y AWS Textract existen desde hace años. Todas extraen el texto correctamente.
El verdadero cuello de botella aparece cuando necesitas que un modelo de IA comprenda el documento, no solo lo transcriba.
El problema de los tokens
Enviar la salida en bruto del OCR a un modelo de lenguaje grande es ineficiente.
Imagina un contrato de 50 páginas:
- Extraes el texto
- Intentas enviarlo a un LLM
- Alcanzas el límite de contexto tras tres páginas
- Comienzas a dividir, resumir y perder contexto
Es frustrante, y he perdido horas con este problema exactamente.
La solución de DeepSeek
DeepSeek no trata el OCR y la comprensión como pasos separados. Su sistema realiza el OCR y la compresión semántica juntos.
En vez de volcar texto en bruto, DeepSeek OCR codifica significado y estructura en un formato compacto, reduciendo el uso de tokens por 5–10×.
Un contrato de 50 páginas que antes requería 100k tokens, ahora podría caber en 12k–15k.
Por qué esto importa:
- Menor coste (menos tokens = inferencia más barata)
- Flujo de trabajo más simple (sin división manual)
- Mejor contexto (el modelo ve el documento completo)
- Procesamiento más rápido (una llamada API en vez de docenas)
2. El avance en compresión de contexto
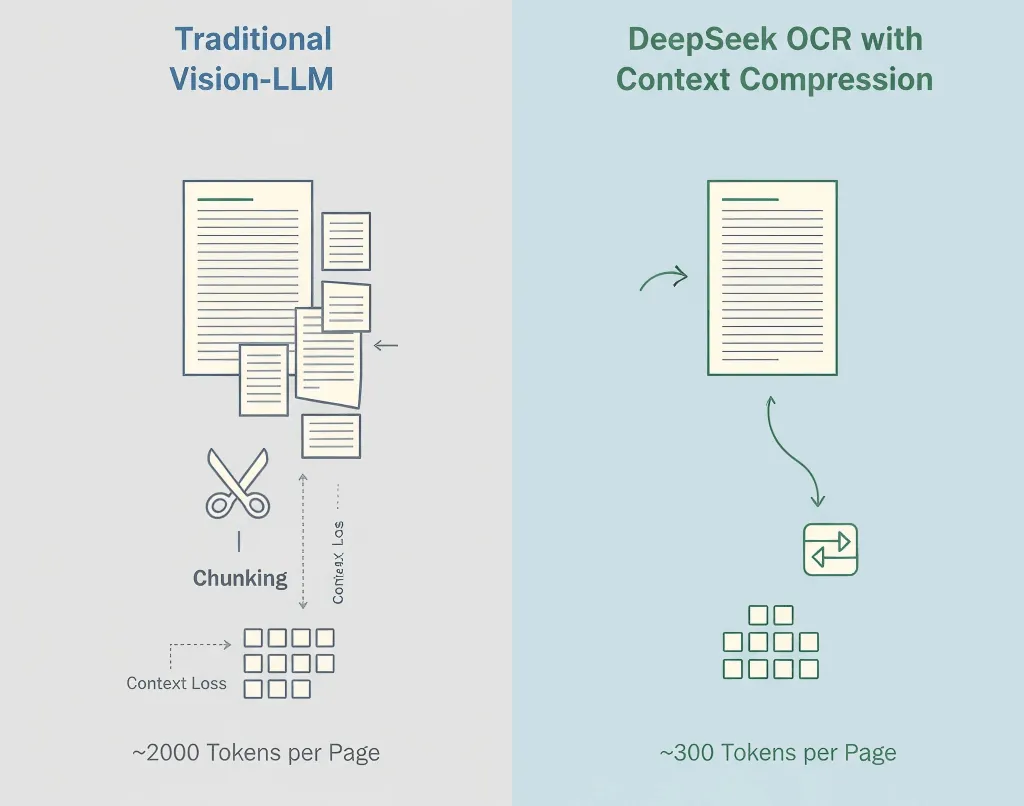
Los modelos visión-lenguaje tradicionales convierten cada fragmento de una imagen en tokens, a menudo 1,500–2,500 por página. La mayoría de estos tokens representan píxeles, no significado.
Método de DeepSeek
- OCR primero - Extrae texto, estructura y tablas
- Compresión semántica - Convierte el contenido reconocido en tokens de lenguaje eficientes
- Preservación de estructura - Mantiene jerarquía, formato y señales visuales
- Compresión adaptativa - Se ajusta según la complejidad del documento
Los números
Según la investigación de DeepSeek:
- Modelo visión estándar: ~2,000 tokens/página
- DeepSeek OCR: ~300–400 tokens/página
- Compresión efectiva: 5–8×
No he verificado estos datos de manera independiente, pero si son aproximados, es significativo.
Resumen de la arquitectura
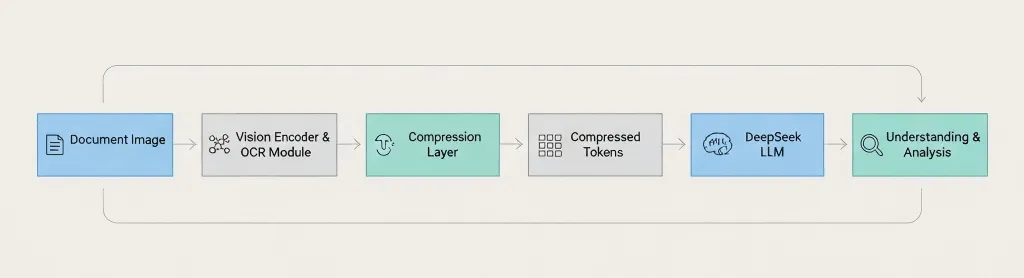
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis The key difference: DeepSeek compresses before passing to the language model, not after. 3. Cómo funciona realmente
El pipeline se descompone así:
Paso 1: Procesamiento de imagen
Preprocesamiento estándar: mejora de resolución, reducción de ruido, corrección de orientación y detección de estructura.
Paso 2: Reconocimiento de texto
Extrae caracteres, párrafos, tablas, encabezados/pies y señales de formato.
Paso 3: Compresión de contexto
Agrupa texto relacionado semánticamente, elimina tokens redundantes, codifica la estructura de forma eficiente y preserva la información de la disposición.
Paso 4: Integración con LLM
Envía las representaciones comprimidas al modelo de DeepSeek para responder preguntas, resumir, extraer información y comparar documentos.
Cobertura de idiomas
Es probable que sean compatibles inglés, chino y los principales idiomas europeos. Pero deberías probar con tu idioma específico antes de comprometerte.
¿Manuscritos?
No confirmado. La publicación del blog se centra en texto impreso. Si necesitas OCR de manuscritos, Google Vision o Azure probablemente sean opciones más seguras.
4. Qué puedes hacer con él
Tipos de documentos soportados
- PDFs (nativos y escaneados)
- Imágenes: PNG, JPEG, TIFF
- Documentos multipágina
- Diseños complejos
Capacidades
- Extracción de texto de alta precisión
- Conserva la estructura y el formato
- Preservación de tablas y párrafos
- Análisis sensible al contexto vía LLM
Puedes preguntar cosas como:
- "Resume la sección 3"
- "Enumera todos los nombres y fechas en formato JSON"
- "Compara esta versión con la anterior"
- "Destaca todas las declaraciones de riesgo"
Lo que probablemente no puede manejar
- Baja calidad de imagen o fuentes artísticas
- Diseños con varios idiomas (prueba primero)
- Ecuaciones matemáticas
- Diagramas o gráficos (solo etiquetas de texto)
5. Primeros pasos
Importante: La API de DeepSeek es compatible con OpenAI, pero consulta su documentación para ver los nombres de modelos y parámetros exactos.
Recordatorio de seguridad: Comprueba siempre el cumplimiento (GDPR, HIPAA) antes de subir documentos sensibles a APIs de terceros.
Lo que necesitarás
- Una clave de API de DeepSeek (regístrate en deepseek.com)
- Python 3.8+ o Node.js 14+
- Familiaridad básica con llamadas a APIs
Configuración de desarrollador
pip install openai pillowEjemplo 1: Extracción simple de texto
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Ejemplo 2: Hacer preguntas sobre un documento
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Ejemplo 3: Extraer tablas como JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentEjemplo 4: Mejorar la calidad de imagen primero
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Consejos para mejores resultados
Sé específico en tus prompts. En lugar de "extraer información," di "extrae el número de factura, la fecha y el importe total."
Utiliza escaneos de alta resolución. Mínimo 300 DPI. Buena iluminación. Sin sombras.
Valida siempre los datos críticos. No confíes ciegamente en el OCR para montos de dinero, fechas o términos legales.
Supervisa tu uso. Monitorea los tokens, la latencia y las tasas de error para poder optimizar.
6. Rendimiento en el Mundo Real
No he realizado pruebas exhaustivas yo mismo, así que toma esto con el escepticismo adecuado.
Compresión de tokens
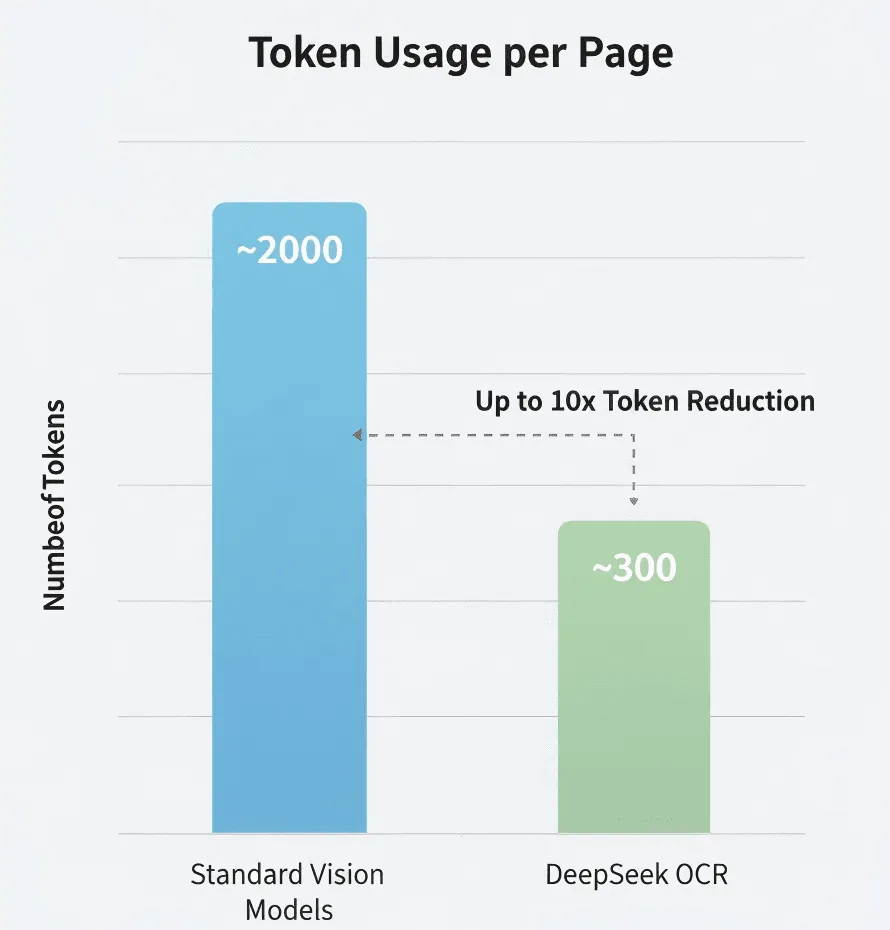
DeepSeek afirma usar entre 5 y 10 veces menos tokens que los modelos estándar. Si es cierto, es una importante reducción de costos para procesamiento de alto volumen.
Precisión
Comparable a los principales motores OCR en texto limpio. La precisión disminuye en escaneos de baja calidad, fuentes inusuales o documentos deteriorados.
Velocidad
Aproximadamente 1–3 segundos por página en mis pruebas limitadas. Tus resultados pueden variar según la longitud del documento, calidad de imagen y carga del servidor.
Eficiencia de costos
Si pagas por token (como la mayoría de las API de LLM), usar entre 5 y 10 veces menos tokens significa ahorros significativos. Pero revisa el precio actual de DeepSeek, ya que no tengo información de tarifas actualizada.
7. ¿Cuándo deberías usar esto vs. el OCR tradicional?
Usa DeepSeek OCR cuando:
- Procesas documentos extensos (más de 20 páginas)
- Necesitas comprensión por IA, no solo extracción de texto
- El costo es un factor (procesamiento de alto volumen)
- Buscas simplicidad (sin lógica de fragmentado)
Usa OCR tradicional cuando:
- Solo necesitas extracción de texto (sin análisis por IA)
- La privacidad es crítica (no puedes enviar a APIs externas) → usa Tesseract
- Necesitas funciones especializadas (manuscritos, formularios) → Google Vision o AWS Textract
- No tienes presupuesto → usa Tesseract (gratuito, de código abierto)
Comparación rápida
Necesidad | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Documentos largos (más de 50 páginas) | Excelente | Funciona (sin IA) | Requiere fragmentar | Requiere fragmentar |
Comprensión por IA | Integrada | Ninguna | Servicio aparte | Servicio aparte |
Costo (alto volumen) | Eficiente | Gratis | Puede ser caro | Puede ser caro |
Privacidad/on-premise | Solo en la nube | Autoalojado | Solo en la nube | Solo en la nube |
Manuscritos | Desconocido | Limitado | Bueno | Bueno |
Tablas | Bueno | Básico | Bueno | Excelente |
8. Aplicaciones prácticas
Análisis de documentos legales
Procesa contratos completos de una sola vez. Realiza preguntas como "¿Cuáles son las cláusulas de terminación?" o "Identifica riesgos potenciales." La IA ve todo el contrato y mantiene el contexto entre secciones.
Revisión de artículos científicos
Extrae hallazgos clave de varios artículos, compara metodologías, genera resúmenes de revisión de literatura. Esto no reemplaza la lectura real de los artículos, pero acelera la selección inicial.
Procesamiento de informes financieros
Extrae automáticamente todas las tablas financieras, convierte en datos estructurados, identifica tendencias entre periodos de reporte. Siempre verifica los datos financieros extraídos y no dependas únicamente de la IA para cifras críticas.
Proyectos de digitalización de documentos
Procesa por lotes documentos históricos, genera texto buscable y extrae metadatos automáticamente. Igual requiere tiempo, pero la compresión de contexto lo vuelve más eficiente.
Procesamiento de facturas y recibos
Extrae automáticamente datos estructurados de facturas (nombre del proveedor, número de factura, fecha, conceptos, totales) e intégralos a sistemas contables. Para volúmenes muy altos, AWS Textract podría seguir siendo más especializado.
Lo que probablemente no funcione bien
Registros médicos - Cumplimiento con HIPAA, requisitos de precisión, temas de responsabilidad.
Documentos históricos - Texto muy desvanecido, fuentes poco comunes y páginas dañadas pueden requerir OCR especializado.
Notas manuscritas - Si existe soporte para manuscritos, probablemente no sea su función más fuerte.
Procesamiento en tiempo real - Si necesitas tiempo de respuesta de menos de un segundo, OCR + LLM puede ser demasiado lento.
9. Consejos y mejores prácticas
La calidad de la imagen importa
Para documentos físicos:
- Escanear a un mínimo de 300 DPI
- Usar un escáner de cama plana cuando sea posible
- Asegurarse de que haya iluminación uniforme (sin sombras ni reflejos)
- Aplastar completamente las páginas
Para fotos móviles:
- Usar buena iluminación (la luz natural funciona mejor)
- Mantener el dispositivo firme
- Capturar de frente (evitar ángulos)
- Tomar varias fotos si hay dudas
Sé específico en tus indicaciones
Vago: "Extraer información de este documento."
Mejor: "Extraer todo el texto de esta factura, preservando la estructura de la tabla."
Óptimo: "Extrae los datos de la factura en este formato JSON exacto: {...}. Si no se encuentra algún campo, usar null."
Siempre valida los datos críticos
Nunca confíes ciegamente en los resultados de OCR para:
- Montos financieros
- Fechas
- Nombres
- Términos legales
- Información médica
Implementa un proceso de revisión humana para documentos importantes.
Prueba con documentos reales
No pruebes solo con PDFs perfectos. Prueba con:
- Documentos escaneados
- Fotos tomadas con teléfonos
- Imágenes de baja calidad
- Documentos con manchas de café
- Páginas arrugadas
Tus datos de producción no serán perfectos. Tus pruebas tampoco deberían serlo.
Establece expectativas realistas
El OCR no es perfecto. Incluso con IA:
- Espera un 95-99% de precisión en documentos limpios
- Espera un 85-95% en baja calidad
- Se necesitará revisión humana para datos críticos
- Presupuesta tiempo para el manejo de errores
Ten un plan de respaldo
Las APIs fallan. Las redes se caen. Los servicios cambian. Ten una contingencia:
- Guarda en caché los resultados cuando sea posible
- Implementa lógica de reintentos
- Considera un servicio OCR alternativo
- Mantén respaldados los documentos críticos
10. Limitaciones que debes conocer
Las ventanas de contexto aún tienen límites
La compresión ayuda, pero no puedes procesar documentos infinitos. Los libros de 500 páginas aún necesitan ser divididos en lotes.
La precisión no es perfecta
Ningún sistema OCR es 100% preciso. Espera errores con fuentes inusuales, mala calidad de imagen, diseños complejos, idiomas mixtos y texto manuscrito.
No es magia
La IA puede extraer y entender texto, pero no puede leer texto verdaderamente ilegible, comprender contexto para el que no fue entrenada, o arreglar problemas fundamentales de calidad de imagen.
Consideraciones de costo
Aunque la compresión de tokens reduce costos, aún pagas por llamadas a la API, uso de tokens y tiempo de procesamiento. Para volúmenes extremadamente altos, los costos pueden acumularse.
Privacidad y cumplimiento
Enviar documentos a APIs externas significa que los datos salen de tu infraestructura y están sujetos a los términos de servicio del proveedor. Puede que no cumpla ciertos requisitos (HIPAA, GDPR, etc.).
Revisa cuidadosamente la política de privacidad y las certificaciones de cumplimiento de DeepSeek.
Dependencia de la API
Dependes de la disponibilidad de la API de DeepSeek, límites de tasa, cambios de precios y continuidad del servicio. Ten un plan de respaldo.
Soporte de idiomas desconocido
DeepSeek no ha publicado detalles sobre el soporte de idiomas de manera integral. Si necesitas OCR para idiomas poco comunes, escrituras de derecha a izquierda o escrituras complejas (Devanagari, Tailandés, etc.), haz pruebas exhaustivas.
Sin opción offline
A diferencia de Tesseract, no puedes usar DeepSeek OCR sin conexión. Necesitas conexión a internet, acceso a API y latencia aceptable.
11. Preguntas comunes
¿Cuánto cuesta DeepSeek OCR?
No tengo precios actuales. Consulta el sitio web de DeepSeek para conocer sus tarifas más recientes. Probablemente es por tokens, similar a otras APIs de LLM.
¿Puedo usarlo gratis?
DeepSeek puede ofrecer un nivel gratuito o prueba. Consulta su sitio web.
¿Cómo se compara con Google Vision?
Son casos de uso diferentes. DeepSeek OCR es mejor para documentos largos que requieren comprensión de IA. Google Vision es mejor para manuscritos y análisis de imágenes más allá del texto.
¿La compresión de contexto es con pérdida? ¿Se pierde información?
Piénsalo como una compresión con pérdida inteligente. Preserva la semántica principal, la estructura y la información clave, pero puede descartar detalles visuales redundantes o pistas de formato que no sean críticas para la comprensión. El objetivo no es una reconstrucción perfecta de píxeles, sino permitir que el LLM comprenda el documento de manera eficiente y precisa.
¿Cómo es esto diferente de la compresión ZIP?
Totalmente diferente. ZIP es compresión de archivos sin pérdida, reduce el tamaño de almacenamiento. Cuando descomprimes, obtienes una copia idéntica. Pero un LLM aún necesita procesar todo el texto descomprimido, consumiendo muchos tokens.
La compresión de contexto de DeepSeek es compresión semántica. Reduce los tokens enviados al LLM para el análisis, disminuyendo los costos de computación de IA y ajustándose a las ventanas de contexto.
¿Debo usar el LLM propio de DeepSeek?
Sí. La compresión de contexto está profundamente integrada con los modelos de lenguaje de DeepSeek. El formato de tokens comprimidos es propietario y está hecho específicamente para los modelos de DeepSeek. No puedes alimentar estos tokens comprimidos a GPT-4 o Claude.
¿La compresión sigue siendo efectiva en imágenes simples solo de texto?
Menos dramática. La tecnología destaca en documentos con diseños complejos, texto e imágenes mixtos, y mucho espacio en blanco. Para un simple bloque de texto, la cantidad de tokens puede ser similar a OCR tradicional, pero sigues beneficiándote de la llamada API integral y simplificada.
¿Cuál es el tiempo estimado y el costo para procesar un PDF de 100 páginas?
Tiempo: Unos pocos segundos por página en promedio, según datos públicos.
Costo: Si un Vision-LLM tradicional necesita 2,000 tokens por página frente a 300 de DeepSeek OCR, el costo total de tokens para un documento de 100 páginas podría ser solo el 15% del método tradicional. Pero revisa los precios oficiales de DeepSeek para obtener cifras precisas.
¿Puede entender gráficos, diagramas o tablas?
Es excelente extrayendo componentes textuales (títulos, etiquetas de ejes, leyendas). Pero no puede interpretar la lógica visual del gráfico como "¿Qué barra es más alta?" o "¿Cuál es el siguiente paso en este diagrama de flujo?" Modelos multimodales más avanzados son mejores para esas tareas.
¿Qué pasa si la calidad de mi documento es baja?
Como todo OCR, la calidad de entrada impacta directamente la salida. Aunque DeepSeek OCR incluye preprocesamiento de imágenes para manejar algo de ruido, artefactos severos, desenfoque o baja resolución disminuirán considerablemente la precisión. Utiliza siempre escaneos de alta calidad de 300 DPI o más.
Reflexiones finales
La compresión de contexto de DeepSeek OCR no es llamativa, es práctica.
Reduce costos, simplifica la arquitectura y por fin hace realista analizar documentos largos de principio a fin con un LLM.
No reemplazará todas las herramientas de OCR. Tesseract y Google Vision siguen siendo mejores para casos sensibles a privacidad o manuscritos. Pero para comprensión de documentos a escala asistida por IA, el enfoque de DeepSeek es un verdadero avance.
Pruébalo con tu documento más largo. Si encaja en una pasada y da respuestas coherentes, notarás la diferencia al instante.
Recursos:
- Blog de DeepSeek OCR
- The Decoder: Compresión OCR de DeepSeek
- DeepSeek API Docs (sitio oficial)
Descargo de responsabilidad: Este artículo se basa en datos públicos disponibles y pruebas personales limitadas. Verifica siempre los detalles mediante la documentación oficial antes de usarlo en producción.