DeepSeek OCR: 실전 가이드 - Context 압축 기술 (2025)
마지막 업데이트: 2026-01-22 18:05:30

최종 업데이트: 2025년 10월 22일
최근 AI 기술 동향을 지켜보고 있었다면 DeepSeek의 새로운 OCR 시스템에 대해 들어봤을 것입니다. 제 관심을 끈 건 단순히 "이미지에서 텍스트를 읽을 수 있다"는 수준이 아니라, 실제로 비용이 많이 드는 한계를 어떻게 해결했는지였습니다. 긴 문서 처리가 토큰 예산을 넘지 않게 하는 문제 말입니다.
이 가이드에서는 DeepSeek OCR의 차별점, 동작 원리, 실제 프로젝트에서 사용할 가치가 있는지까지 쉽게 설명합니다.
목차
- DeepSeek OCR의 차별점은 무엇인가?(#what-makes-it-different)
- Context 압축의 혁신(#context-compression)
- 실제 동작 방식(#how-it-works)
- 무엇을 할 수 있는가(#capabilities)
- 시작하는 방법(#getting-started)
- 실사용 퍼포먼스(#performance)
- 언제 이걸 써야 하나 vs. 기존 OCR?(#comparison)
- 실무 활용 사례(#applications)
- 팁과 베스트 프랙티스(#tips)
- 알아야 할 한계(#limitations)
- 자주 묻는 질문(#faq)
1. DeepSeek OCR의 차별점은 무엇인가?
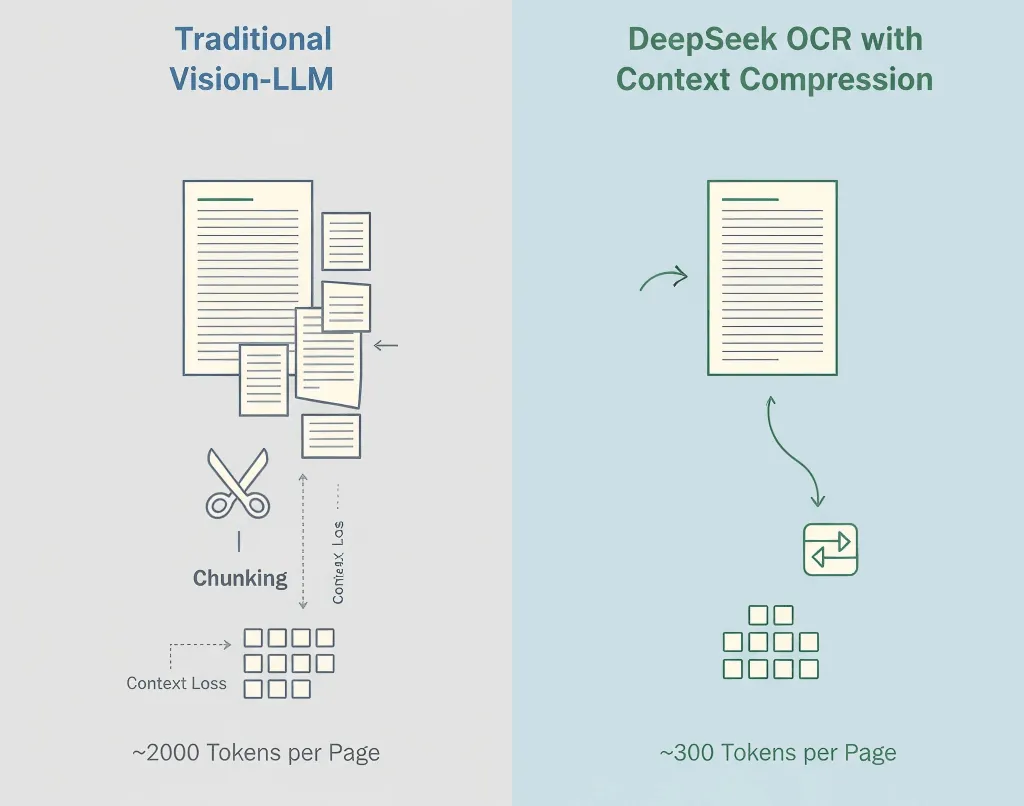
OCR 자체는 새로운 기술이 아닙니다. Tesseract, Google Vision, AWS Textract 같은 툴은 이미 수년간 있어왔고, 모두 텍스트 추출 기능은 훌륭합니다.
진짜 문제는 AI 모델이 문서를 이해해야 할 때 발생합니다. 단순 복사만으론 부족하죠.
토큰 문제
OCR 결과를 그대로 대형 언어 모델에 입력하면 비효율적입니다.
예를 들어 50페이지짜리 계약서를 생각해보세요:
- 텍스트를 뽑습니다
- LLM으로 보내려고 시도합니다
- 3페이지만 넣으면 context 한계에 부딪힙니다
- 결국 분할, 요약을 시작하고, 맥락도 놓치게 됩니다
정말 답답한 일이고, 저도 이 문제로 몇 시간을 낭비했었습니다.
DeepSeek의 해결책
DeepSeek는 OCR과 문서 이해를 별개로 처리하지 않습니다. 이 시스템은 OCR과 의미 압축을 동시에 진행합니다.
텍스트만 던지는 대신, DeepSeek OCR은 의미와 레이아웃을 함께 인코딩해서 토큰 사용량을 5~10배 절감합니다.
예전에는 10만 토큰이 필요했던 50페이지 계약서가 이제는 12k~15k 토큰으로 처리될 수 있습니다.
이게 중요한 이유:
- 비용 절감(토큰 적게 사용 = 추론 비용 절약)
- 작업 과정 단순화(수동 분할 불필요)
- 더 나은 맥락(모델이 문서 전체를 볼 수 있음)
- 더 빠른 처리(API 호출 한 번으로 끝)
2. Context 압축의 혁신
기존 비전-언어 모델은 이미지를 패치 단위로 모두 토큰화합니다. 1페이지당 보통 1,500~2,500 토큰이 나오는데, 이 중 대부분은 의미가 아닌 픽셀 정보일 뿐입니다.
DeepSeek의 방법
- 최초 OCR - 텍스트, 구조, 표 추출
- 의미 압축 - 인식된 내용을 효율적인 언어 토큰으로 변환
- 구조 보존 - 계층, 포맷, 시각적 단서도 유지
- 적응적 압축 - 문서 복잡도에 따라 최적화
숫자로 보는 차이
DeepSeek의 연구에 따르면:
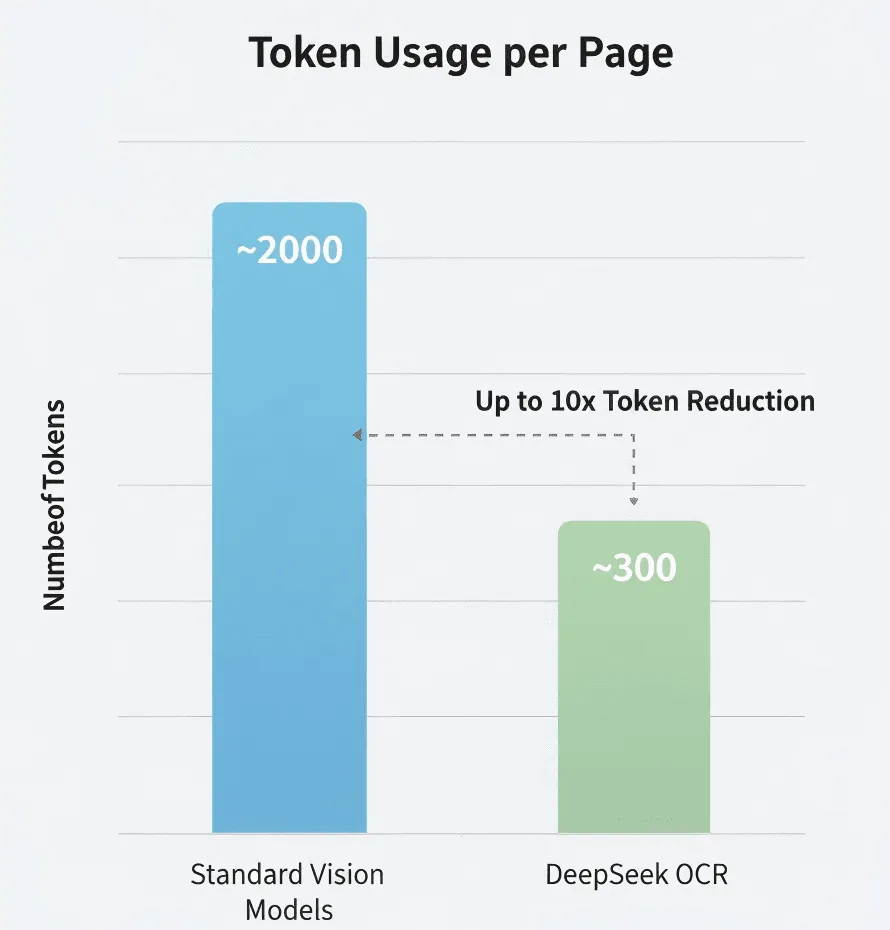
- 표준 비전 모델: ~2,000 토큰/페이지
- DeepSeek OCR: ~300~400 토큰/페이지
- 실제 압축률: 5~8배
독립적으로 검증하진 않았지만, 사실이라면 정말 큰 차이입니다.
아키텍처 개요
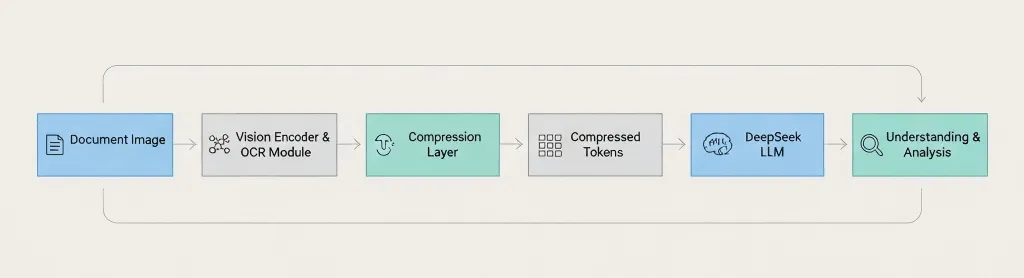
문서 이미지 → 비전 인코더 → OCR 모듈 → 압축 레이어 → 압축된 토큰 → DeepSeek LLM → 이해 및 분석 핵심 차이점: DeepSeek는 언어 모델에 넘기기 전에 압축을 진행합니다. 3. 실제 동작 방식
전체 파이프라인은 대략 이렇게 흐릅니다:
1단계: 이미지 처리
표준 전처리(해상도 향상, 노이즈 제거, 방향 보정, 레이아웃 인식)
2단계: 텍스트 인식
문자, 문단, 표, 머리말/꼬리말, 형식 단서 추출
3단계: Context 압축
관련 텍스트를 의미적으로 그룹화, 중복 토큰 제거, 구조를 효율적으로 인코딩, 레이아웃 정보도 보존
4단계: LLM 연동
압축 결과를 DeepSeek 모델에 입력해서 질의응답, 요약, 정보 추출, 문서 비교 등 다양한 작업을 수행합니다.
지원 언어 범위
영어, 중국어, 주요 유럽 언어는 지원 가능성이 높지만, 실제로는 원하는 언어를 미리 테스트해보는 것이 좋습니다.
필기체?
확정 정보는 없습니다. 공식 블로그 포스트는 인쇄 텍스트만 다룹니다. 필기 OCR이 필요하다면 Google Vision이나 Azure가 더 안전한 선택일 수 있습니다.
4. 무엇을 할 수 있는가
지원 문서 유형
- PDF(원본 및 스캔)
- 이미지: PNG, JPEG, TIFF
- 여러 페이지 문서
- 복잡한 레이아웃
주요 기능
- 높은 정확도의 텍스트 추출
- 구조와 형식 보존
- 표와 문단 정보 유지
- LLM기반 맥락 분석
이렇게 질의할 수 있습니다:
- "3번 섹션 요약해줘"
- "모든 이름과 날짜를 JSON으로 정리해줘"
- "이 버전을 이전 버전과 비교해줘"
- "모든 위험 문구를 강조해줘"
아마 불가능한 기능
- 화질 불량/데코 폰트 사용 이미지
- 혼합 언어 레이아웃(먼저 테스트 필요)
- 수식 인식
- 도표나 차트(텍스트 라벨만 추출)
5. 시작하기
중요: DeepSeek API는 OpenAI와 호환되지만, 정확한 모델 명과 파라미터는 공식 문서를 반드시 확인하세요.
보안 안내: GDPR, HIPAA 등 규제 준수 상태를 반드시 확인하고, 민감한 문서를 외부 API에 업로드하세요.
필요한 것
- DeepSeek API 키(deepseek.com 회원가입)
- Python 3.8+ 혹은 Node.js 14+ 버전
- API 호출 기본 지식
개발 환경 셋업
pip install openai pillow예시 1: 단순 텍스트 추출
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# 사용법text = extract_text("my_document.jpg")print(text)예시 2: 문서 질의응답
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# 여러 가지 질문answer = ask_doc("contract.jpg", "결제 조건이 어떻게 되어 있나요?")print(answer)예시 3: 표 데이터를 JSON으로 추출
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content예시 4: 이미지 품질 개선 후 OCR
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# OCR 전에 개선improved = enhance_image("blurry_scan.jpg")text = extract_text(improved)더 좋은 결과를 위한 팁
프롬프트를 구체적으로 작성하세요. "정보를 추출"보다는 "청구서 번호, 날짜, 총액을 추출"처럼 명확하게 요청하세요.
고해상도 스캔 이미지를 사용하세요. 300 DPI 이상, 좋은 조명, 그림자 없는 환경이 중요합니다.
중요 데이터는 꼭 검증하세요. 금액, 날짜, 계약 조건 등은 OCR만 믿지 말고 최종 검증하세요.
사용량을 추적하세요. 토큰, 지연 시간, 오류율을 모니터링하여 최적화할 수 있습니다.
6. 실제 성능
저는 직접 종합적인 벤치마크를 실행해보지 않았으니, 적절한 회의론을 가지고 참고하시기 바랍니다.
토큰 압축
DeepSeek은 표준 모델 대비 5–10배 적은 토큰을 사용한다고 주장합니다. 사실이라면 대량 처리 시 비용을 크게 줄일 수 있습니다.
정확도
깨끗한 텍스트에서는 주요 OCR 엔진에 필적합니다. 품질이 낮은 스캔, 특이한 글꼴, 손상된 문서에서는 정확도가 떨어집니다.
속도
제한적인 테스트에서는 페이지당 약 1–3초가 걸렸습니다. 실제 속도는 문서 길이, 이미지 품질, 서버 부하에 따라 달라질 수 있습니다.
비용 효율성
대부분의 LLM API처럼 토큰 단위로 비용을 지불한다면, 5–10배 적은 토큰을 사용하면 상당한 절감이 가능합니다. 다만 DeepSeek의 실제 요금 정책은 반드시 확인하세요. 현재 요율 정보는 없습니다.
7. 이 방식과 기존 OCR 중 언제 어떤 것을 써야 할까?
DeepSeek OCR을 사용할 때:
- 긴 문서(20페이지 이상)를 처리할 때
- 텍스트 추출뿐만 아니라 AI의 이해가 필요할 때
- 비용이 중요한 경우(대량 처리)
- 단순함을 원할 때(조각내기 로직 불필요)
전통적 OCR을 사용할 때:
- 텍스트 추출만 필요할 때(AI 분석 없음)
- 개인정보 보호가 중요한 경우(외부 API 사용 불가) → Tesseract 사용
- 특수 기능(필기체, 양식 인식 등)이 필요할 때 → Google Vision 또는 AWS Textract 사용
- 예산이 0원일 때 → Tesseract 사용(무료, 오픈 소스)
간단 비교
필요사항 | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
긴 문서(50페이지 이상) | 탁월함 | 작동함(AI 없음) | 조각내기 필요 | 조각내기 필요 |
AI 이해력 | 내장됨 | 없음 | 별도 서비스 | 별도 서비스 |
비용(대량) | 효율적 | 무료 | 비쌀 수 있음 | 비쌀 수 있음 |
개인정보/온프레미스 | 클라우드 전용 | 자가 호스팅 | 클라우드 전용 | 클라우드 전용 |
필기 인식 | 알 수 없음 | 제한적 | 우수함 | 우수함 |
표 인식 | 우수함 | 기본적 | 우수함 | 탁월함 |
8. 실제 활용 사례
법률 문서 분석
전체 계약서를 한 번에 처리할 수 있습니다. "해지 조항이 무엇인가요?" 또는 "잠재적 리스크를 식별하세요"와 같은 질문을 할 수 있습니다. AI는 계약 전체를 확인하며, 각 섹션 간 맥락을 유지합니다.
논문 리뷰
여러 논문에서 핵심 결과를 추출하고, 방법론을 비교하고, 문헌 요약을 자동 생성합니다. 실제 논문을 읽는 것을 대체하진 못하지만 초기 검토를 빠르게 할 수 있습니다.
재무 보고서 처리
모든 재무표를 자동으로 추출하고, 구조화된 데이터로 변환하고, 여러 회계 기간에 걸친 추세를 파악할 수 있습니다. 추출된 재무 데이터는 반드시 검증하고, 중요한 수치를 AI에만 의존하지 마세요.
문서 디지털화 프로젝트
역사적 문서를 일괄 처리해 검색 가능한 텍스트를 생성하거나 메타데이터를 자동 추출할 수 있습니다. 여전히 시간이 걸리지만, 맥락을 압축하여 더 효율적으로 작업할 수 있습니다.
송장 및 영수증 처리
송장에서(공급업체명, 송장번호, 날짜, 항목, 총액 등) 구조화된 데이터를 자동 추출하여 회계 시스템에 연동할 수 있습니다. 대용량의 경우 AWS Textract가 더 특화되어 있을 수 있습니다.
잘 안 맞는 분야
의료 기록 - HIPAA 준수, 높은 정확도 요구, 법적 책임 이슈가 있습니다.
역사적 문서 - 흐릿한 텍스트, 특이한 글꼴, 손상 페이지는 특수 OCR이 필요할 수 있습니다.
필기 메모 - 필기체 지원이 있다 해도 핵심 강점은 아닙니다.
실시간 처리 - 1초 미만의 응답 속도가 필요하다면 OCR + LLM은 너무 느릴 수 있습니다.
9. 팁 및 모범 사례
이미지 품질이 중요합니다
실물 문서의 경우:
- 최소 300 DPI로 스캔하세요
- 가능하면 평판 스캐너를 사용하세요
- 고른 조명 확보(그림자나 눈부심 없이)
- 페이지를 완전히 평평하게 하세요
모바일 사진의 경우:
- 좋은 조명을 사용하세요(자연광이 가장 좋음)
- 기기를 흔들리지 않게 잡으세요
- 정면에서 촬영하세요(각도 피하기)
- 확신이 없으면 여러 번 촬영하세요
프롬프트를 구체적으로 작성하세요
모호함: "이 문서에서 정보를 추출하세요."
더 나은 예: "이 인보이스의 모든 텍스트를 표 구조를 유지하며 추출하세요."
최고의 예: "인보이스 데이터를 다음 정확한 JSON 형식으로 추출하세요: {...}. 만약 찾을 수 없는 필드는 null을 사용하세요."
중요한 데이터는 항상 검증하세요
OCR 결과를 맹신하면 안 되는 경우:
- 금액
- 날짜
- 이름
- 법적 용어
- 의료 정보
중요한 문서는 반드시 사람이 검토하는 과정을 거치세요.
실제 문서로 테스트하세요
완벽한 PDF만으로 테스트하지 마세요. 다음과 같은 문서도 테스트하세요:
- 스캔한 문서
- 휴대폰으로 촬영한 사진
- 저화질 이미지
- 커피 얼룩이 있는 문서
- 구겨진 페이지
운영 환경의 데이터는 결코 완벽하지 않습니다. 테스트도 완벽할 필요 없습니다.
현실적인 기대치를 설정하세요
OCR은 완벽하지 않습니다. AI를 써도:
- 깨끗한 문서의 경우 정확도 95-99% 예상
- 저품질 문서의 경우 정확도 85-95% 예상
- 중요한 데이터는 반드시 사람의 검토가 필요할 수 있음
- 오류 처리를 위한 시간을 예산에 반영하세요
백업 플랜을 준비하세요
API가 중단될 수 있습니다. 네트워크가 끊길 수 있고, 서비스가 변경될 수 있습니다. 비상 대책을 마련하세요:
- 가능한 경우 결과를 캐시에 저장하세요
- 재시도 로직을 구현하세요
- 백업 OCR 서비스를 고려하세요
- 중요 문서는 항상 백업하세요
10. 알아야 할 제한점
컨텍스트 윈도우는 여전히 한계가 있습니다
압축 기능은 도움이 되지만, 무한히 많은 문서를 처리할 수 있는 것은 아닙니다. 500페이지짜리 책은 여전히 배치가 필요합니다.
정확도는 완벽하지 않습니다
어떤 OCR 시스템도 100% 정확하지 않습니다. 특이한 폰트, 저화질 이미지, 복잡한 레이아웃, 혼합 언어, 손글씨 등에서는 오류가 날 수 있습니다.
마법이 아닙니다
AI가 텍스트를 추출하고 이해할 수 있지만, 읽을 수 없을 정도로 불명확한 텍스트, 학습되지 않은 컨텍스트, 근본적인 이미지 품질 문제는 해결할 수 없습니다.
비용 고려사항
토큰 압축으로 비용은 감소하지만, 여전히 API 호출, 토큰 사용, 처리 시간에 비용이 듭니다. 매우 많은 양의 문서는 비용이 누적될 수 있습니다.
프라이버시 및 규정 준수
문서를 외부 API로 전송하면 데이터가 자체 인프라를 떠나 공급자의 서비스 약관에 따라 관리됩니다. 특정 규정(HIPAA, GDPR 등)을 준수하지 못할 수 있습니다.
DeepSeek의 개인정보 처리방침과 규정 준수 인증을 꼼꼼히 확인하세요.
API 의존성
DeepSeek의 API 가용성, 속도 제한, 가격 변경, 서비스 지속성에 의존하게 됩니다. 백업 플랜을 꼭 준비하세요.
언어 지원 미확정
DeepSeek는 포괄적인 언어 지원 정보를 공개하지 않았습니다. 덜 일반적인 언어, 오른쪽에서 왼쪽으로 쓰는 스크립트, 복잡한 스크립트(데바나가리, 태국어 등)가 필요하다면 꼭 직접 충분히 테스트하세요.
오프라인 옵션 없음
Tesseract와 달리 DeepSeek OCR은 오프라인으로 실행할 수 없습니다. 인터넷 연결, API 접근, 적절한 지연 시간이 필요합니다.
11. 자주 묻는 질문
DeepSeek OCR의 가격은 얼마인가요?
현재 가격은 알 수 없습니다. 최신 가격은 DeepSeek 공식 웹사이트에서 확인하세요. 기타 LLM API와 마찬가지로 토큰 기반일 가능성이 높습니다.
무료로 사용할 수 있나요?
DeepSeek는 무료 요금제 혹은 체험판을 제공할 수 있습니다. 웹사이트를 참고하세요.
Google Vision과 비교하면 어떻습니까?
사용 사례가 다릅니다. DeepSeek OCR은 긴 문서에 AI의 이해가 필요한 경우 더 적합하고, Google Vision은 손글씨와 텍스트 외의 이미지 분석에 더 뛰어납니다.
컨텍스트 압축이 손실을 발생시키나요? 정보가 사라지나요?
지능적인 손실 압축이라 생각하면 됩니다. 핵심 의미와 구조, 주요 정보를 보존하지만, 이해에 중요하지 않은 중복된 시각적 정보나 서식 요소는 생략될 수 있습니다. 목표는 픽셀 단위의 복원이 아니라 LLM이 문서를 효율적으로, 정확하게 이해하는 것입니다.
ZIP 압축과 무엇이 다른가요?
완전히 다릅니다. ZIP은 무손실 파일 압축으로 저장 공간을 줄입니다. 압축을 풀면 동일한 원본을 얻고, LLM은 모든 풀린 텍스트를 처리해야 해서 많은 토큰이 소모됩니다.
DeepSeek의 컨텍스트 압축은 의미 기반 압축입니다. LLM에 분석을 위해 전송되는 토큰을 줄여서 AI 처리 비용을 낮추고, 컨텍스트 윈도우에 더 잘 맞춥니다.
DeepSeek의 자체 LLM을 반드시 사용해야 하나요?
네. 컨텍스트 압축이 DeepSeek의 언어 모델과 깊게 통합되어 있습니다. 압축된 토큰 포맷은 독자적이며 DeepSeek 모델에 특화되어 있습니다. 이 압축 토큰을 GPT-4나 Claude에는 사용할 수 없습니다.
단순한 텍스트 이미지에도 압축이 효과적입니까?
효과가 덜 뚜렷할 수 있습니다. 기술의 강점은 복잡한 레이아웃, 텍스트와 이미지가 혼합된 문서, 여백이 많은 경우에 있습니다. 단순한 텍스트만 있는 문서는 기존 OCR과 토큰 수가 비슷할 수 있지만, 그래도 올인원 API 호출의 간소화된 이점을 얻을 수 있습니다.
100페이지짜리 PDF를 처리하는 예상 시간과 비용은?
시간: 공개된 정보를 기준으로 평균적으로 페이지당 몇 초.
비용: 기존 Vision-LLM이 페이지당 2,000토큰이라면 DeepSeek OCR은 300토큰만 필요해 100페이지 문서의 토큰 비용이 기존 방식의 15% 수준일 수 있습니다. 정확한 수치는 DeepSeek 공식 가격을 반드시 확인하세요.
차트, 그래프, 다이어그램도 이해할 수 있습니까?
텍스트 구성요소(제목, 축 라벨, 범례 등) 추출에는 뛰어납니다. 단, "어떤 막대가 가장 긴가?"나 "이 플로우차트의 다음 단계는?"처럼 시각적 논리 자체는 해석할 수 없습니다. 그런 작업은 더 발전된 멀티모달 모델이 적합합니다.
문서 품질이 나쁘면 어떻게 되나요?
모든 OCR과 마찬가지로 입력 품질이 결과 품질에 직접적으로 영향을 미칩니다. DeepSeek OCR은 이미지 전처리로 일부 노이즈를 완화하지만, 심한 잡음·흐림·저해상도는 정확도를 크게 떨어뜨립니다. 항상 300 DPI 이상의 고품질 스캔본을 사용하세요.
최종 소감
DeepSeek OCR의 컨텍스트 압축은 요란하지 않지만 실용적입니다.
비용을 절감하고, 아키텍처를 단순화하며, LLM으로 긴 문서를 처음부터 끝까지 현실적으로 분석할 수 있게 만듭니다.
모든 OCR 툴을 대체하지는 못합니다. Tesseract와 Google Vision은 프라이버시에 민감하거나 손글씨 처리에 여전히 강점이 있습니다. 하지만 확장성 있는 AI 기반 문서 이해에는 DeepSeek의 접근이 확실한 진전입니다.
가장 긴 문서로 시험해 보세요. 한 번에 처리되고, 일관된 답변을 얻는 즉시 차이를 체감할 수 있습니다.
참고 자료:
- DeepSeek OCR 블로그 포스트
- The Decoder: DeepSeek의 OCR 압축
- DeepSeek API Docs (공식 사이트)
면책고지: 이 글은 공개된 정보와 제한적 개인 테스트를 기반으로 작성되었습니다. 운영 환경에서 사용 전에는 반드시 공식 문서를 통해 세부 정보를 다시 확인하세요.