DeepSeek OCR:實用指南與其上下文壓縮技術(2025)
最後更新: 2026-01-22 18:05:30

最後更新:2025年10月22日
如果你最近有關注人工智慧的發展,可能已聽說過 DeepSeek 推出的新 OCR 系統。引起我注意的不只是「我們能從影像讀出文字」這種老調重彈,而是他們如何解決了一個真實且昂貴的限制:處理長篇文件時不會輕易爆表你的 Token 配額。
本指南將解析 DeepSeek OCR 與眾不同之處、其運作原理,以及它是否值得應用在你的專案中。
目錄
- DeepSeek OCR 有何不同?(#what-makes-it-different)
- 上下文壓縮的重大突破(#context-compression)
- 實際運作方式(#how-it-works)
- 你能用它做什麼(#capabilities)
- 快速上手(#getting-started)
- 實際效能表現(#performance)
- 何時該選用這個而非傳統 OCR?(#comparison)
- 實用應用場景(#applications)
- 使用技巧與最佳實踐(#tips)
- 你應該知道的限制(#limitations)
- 常見問題(#faq)
1. DeepSeek OCR 有何不同?
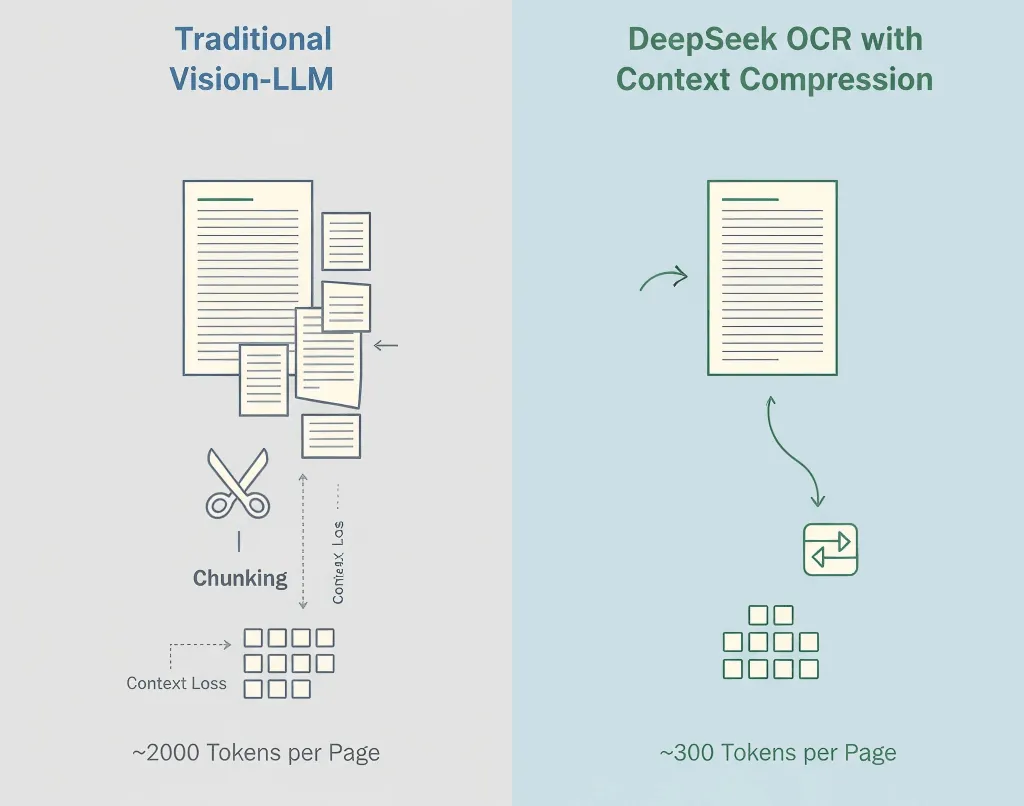
OCR 本身並不是什麼新鮮事,像 Tesseract、Google Vision 與 AWS Textract 這些工具已經存在多年。大家都能好好地把文字擷取出來。
真正的瓶頸發生在你需要讓 AI 模型理解文件內容,而不僅只是將其轉錄時。
Token 問題
直接把 OCR 原始輸出丟進大型語言模型其實很沒效率。
想像一份50頁的合約:
- 你先擷取文字
- 然後嘗試送到 LLM
- 結果讀到三頁就撞到 context 上限
- 你開始分塊、摘要,最後上下文遺失
這很令人沮喪,我自己也在這個問題上浪費了許多時間。
DeepSeek 的解法
DeepSeek 不把 OCR 和理解分成兩個步驟。他們的系統將 OCR 和語意壓縮一起完成。
DeepSeek OCR 並非直接傾倒原始文字,而是將內容的語意與版面結構編碼成高度壓縮的形式,Token 用量減少 5–10 倍。
一份過去需要 10 萬個 token 的 50 頁合約,如今可能僅需 12,000–15,000。
這帶來的意義:
- 成本更低(Token 更少=推論費用更省)
- 流程更簡單(不需手動切塊)
- 上下文更完整(模型能看到整份文件)
- 處理速度更快(只要調用一次 API)
2. 上下文壓縮的重大突破
傳統視覺語言模型會將一張影像的每個小區塊都轉換成 tokens,往往每頁就有 1,500–2,500 個 token,其中絕大多數僅代表像素,而不是語意內容。
DeepSeek 的方法
- 優先 OCR——提取文字、版面和表格
- 語意壓縮——將辨識內容轉為高效語言 tokens
- 結構保留——維持階層、格式與視覺提示
- 自適應壓縮——根據文件複雜度動態調整
數字比較
依據 DeepSeek 的研究:
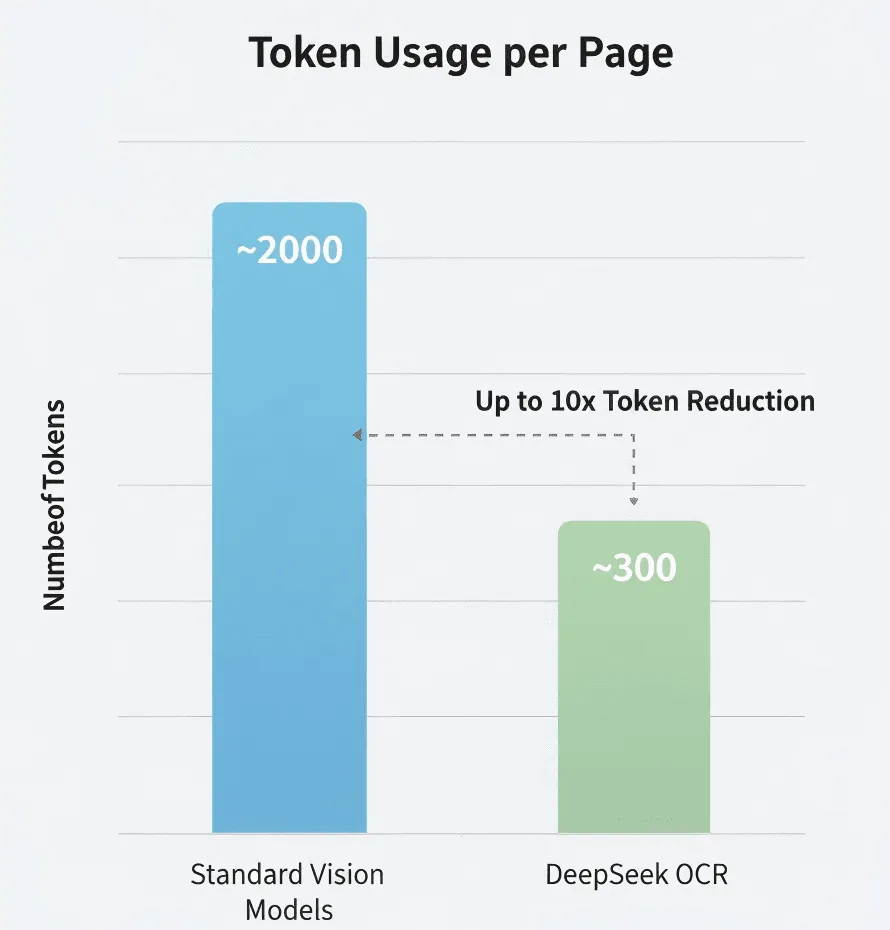
- 標準視覺模型:約 2,000 tokens/頁
- DeepSeek OCR:約 300–400 tokens/頁
- 有效壓縮率:5–8 倍
我自己還沒獨立驗證,不過如果數字接近,也已經很顯著了。
架構總覽
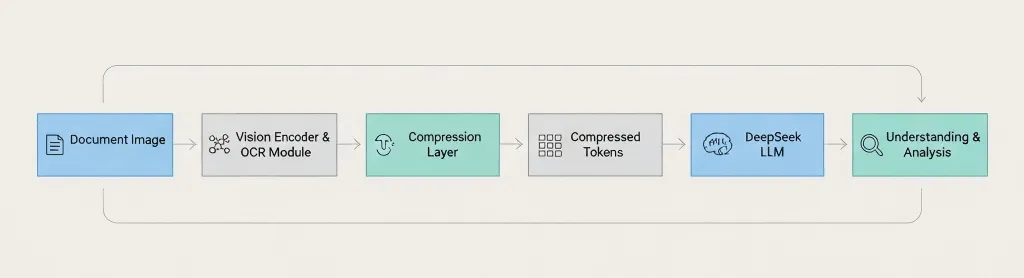
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis 關鍵差異:DeepSeek 是在傳給語言模型 之前 就先壓縮,而不是之後。3. 實際運作方式
整個流程如下:
步驟1:影像處理
標準前處理,包括解析度提升、雜訊抑制、旋轉校正、版面偵測。
步驟2:文字辨識
提取字元、段落、表格、頁首頁尾與格式提示。
步驟3:上下文壓縮
語意群組相關文字、去除冗餘 token、高效編碼結構,並保留版面資訊。
步驟4:LLM 整合
將壓縮後的內容餵給 DeepSeek 模型進行問答、摘要、資訊抽取或文件比對。
語言覆蓋範圍
英語、中文以及歐洲主要語言大概率都支持。但正式採用前建議用自己的目標語言測試。
手寫辨識?
未確認。官方部落格集中於印刷文字。如果需要手寫 OCR,Google Vision 或 Azure 可能更保險。
4. 你能用它做什麼
支援的文件類型
- PDF(原生及掃描版)
- 圖片:PNG、JPEG、TIFF
- 多頁文件
- 複雜版面
功能特色
- 高精度文字擷取
- 保留結構與格式
- 表格與段落呈現完整
- 透過 LLM 進行情境理解分析
你可以向它問:
- 「摘要第 3 節」
- 「列出所有人名與日期,用 JSON 格式」
- 「將這一版與前一版比較」
- 「標註所有風險聲明」
可能無法處理的情境
- 影像品質差或特殊美術字型
- 多語混排(需先測試)
- 數學公式
- 圖表或流程圖(僅辨識文字標籤)
5. 快速上手
重要: DeepSeek 的 API 與 OpenAI 兼容,但請查閱官方文件確認正確的模型名稱與參數。
安全提醒: 上傳敏感文件至第三方 API 前,務必確認合規性(GDPR、HIPAA)。
你需要準備
- DeepSeek API 金鑰(可至 deepseek.com 註冊)
- Python 3.8+ 或 Node.js 14+
- 具備基本 API 呼叫經驗
開發者環境建置
pip install openai pillow範例1:簡單文字擷取
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)範例2:針對文件提問
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)範例3:擷取表格為 JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content範例4:預先增強影像品質
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)提升成果的建議
描述請盡量明確。 不要只寫「擷取資訊」,而是直接寫「擷取發票號碼、日期與總金額」。
請用高解析度掃描。 建議至少 300 DPI、光線充足、沒有陰影。
關鍵資料務必自行核對。 千萬不要盲信 OCR 輸出的金額、日期或法律條文。
追蹤您的使用情況。 監控 Token 數量、延遲時間與錯誤率,讓您得以優化。
6. 真實世界的效能
我自己沒有執行過全面性的基準測試,因此請以適當的懷疑態度看待以下內容。
Token 壓縮
DeepSeek 宣稱比標準模型少 5–10 倍的 Token。如果屬實,對於大量處理來說成本會大幅降低。
準確度
在乾淨的文件文字上,準確度可媲美主流 OCR 引擎。在低品質掃描、不尋常字體或劣化文件時,準確度會下降。
速度
在我有限的測試中,每頁大概 1–3 秒。實際速度會根據文件長度、圖像品質及伺服器負載而有所不同。
成本效益
如果您是按 Token 計費(如多數 LLM API),能少用 5–10 倍的 Token 意味著可節省大量費用。不過請查閱 DeepSeek 的實際價目,因為我沒有目前的費率資訊。
7. 什麼時候該用這種方法而不是傳統 OCR?
建議在以下情境使用 DeepSeek OCR:
- 您要處理長文件(20 頁以上)
- 您需要 AI 理解,而不只是純文字擷取
- 成本是考量因素(大量處理)
- 您追求簡單(不需分段處理邏輯)
建議在以下情境使用傳統 OCR:
- 您只需要純文字擷取(無 AI 分析)
- 隱私至關重要(無法傳送至外部 API)→ 可用 Tesseract
- 需要特殊功能(手寫、表格)→ Google Vision 或 AWS Textract
- 預算為零 → 用 Tesseract(免費開源)
快速比較
需求 | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
長文件(50 頁以上) | 極佳 | 可用(無 AI) | 需分段 | 需分段 |
AI 理解 | 內建 | 無 | 需另用服務 | 需另用服務 |
成本(高用量) | 高效率 | 免費 | 可能昂貴 | 可能昂貴 |
隱私/在地部署 | 僅限雲端 | 自架 | 僅限雲端 | 僅限雲端 |
手寫辨識 | 未知 | 有限 | 良好 | 良好 |
表格 | 良好 | 基本 | 良好 | 極佳 |
8. 實務應用
法律文件分析
一次處理整份合約。可問 AI「終止條款有哪些?」或「指出潛在風險」。AI 能掌握整份契約,保持跨段落的脈絡。
論文審閱
從多份論文中萃取關鍵發現、比對方法學、產生文獻回顧摘要。雖無法取代完整閱讀,但可加快初步篩選速度。
財報處理
自動擷取所有財務表格、轉換成結構化資料、比對不同報告期間的趨勢。所有擷取的財務資料都應再次確認,重要數字不可僅依賴 AI。
文件數位化專案
批次處理歷史文件,自動生成可搜尋文字、擷取中繼資料。雖然仍需花費時間,但脈絡壓縮促使效率提升。
發票與收據處理
自動從發票中擷取結構化資料(供應商名稱、發票號碼、日期、明細、總計)並串接到會計系統。如用量極大,AWS Textract 可能更專業。
哪些應用可能效果不好
醫療紀錄 - 需符合法規(如 HIPAA)、高準確度需求及法律責任等問題。
歷史文件 - 字跡斑駁、不常見字體、破損頁面可能需要專門 OCR。
手寫筆記 - 即使有手寫辨識,通常也不是強項。
即時處理 - 若需要亞秒級回應時間,OCR + LLM 可能過慢。
9. 技巧與最佳實踐
影像品質很重要
對於紙本文件:
- 至少以 300 DPI 掃描
- 盡可能使用平板掃描器
- 確保光線均勻(避免陰影或反光)
- 將頁面完全攤平
對於手機拍攝:
- 使用良好光源(自然光最佳)
- 手持設備要穩定
- 正面拍攝(避免角度偏斜)
- 不確定時多拍幾張
提示要具體
模糊: 「從這份文件萃取資訊。」
較好: 「萃取這份發票的所有文字,並保留表格結構。」
最佳: 「以這個精確 JSON 格式:{...} 萃取發票資料。若任何欄位未找到則填 null。」
重要資料一定要驗證
絕對不要盲信 OCR 輸出於以下資料:
- 金額
- 日期
- 姓名
- 法律條款
- 醫療資訊
對重要文件應設置人工審核流程。
用真實文件測試
不要只用完美的 PDF 測試。請用:
- 掃描文件
- 手機拍攝的照片
- 低畫質影像
- 有咖啡漬的文件
- 有摺痕的頁面
你的正式數據不會完美,測試也不該是完美的。
設定合理期望值
OCR 並非完美,即使有 AI:
- 乾淨文件預期 95-99% 準確度
- 低品質預期 85-95%
- 重要資料需人工審核
- 要預留錯誤處理時間
要有備案
API 可能失效、網路可能中斷、服務可能變動,請預先規劃:
- 盡可能快取結果
- 實作重試邏輯
- 考慮備用 OCR 服務
- 備份重要文件
10. 你應該知道的限制
Context Window 仍有限制
壓縮有幫助,但無法處理無限量文件。像 500 頁書仍需分批。
準確性非百分百
沒有任何 OCR 系統能做到 100% 準確。異常字型、影像品質差、複雜排版、混合語言、手寫文字都容易出錯。
不是魔法
AI 能萃取和理解文字,但它無法讀取真正無法辨識的文字、理解未訓練的語境,或修復根本性的影像品質問題。
成本考量
雖然 Token 壓縮可減省成本,但仍需支付 API 呼叫、Token 使用與處理時間的費用。極大量資料時,成本仍會累積。
隱私與合規性
將文件傳送至外部 API 意味著資料會離開你的基礎設施,並受限於服務商條款。可能不符合部分合規要求(如 HIPAA、GDPR 等)。
請仔細查閱 DeepSeek 的隱私政策與合規認證。
API 依賴性
你會依賴 DeepSeek API 的可用性、速率限制、價格調整和服務連續性。請預先準備備案。
語言支援未知
DeepSeek 尚未公布完整的語言支援資訊。若需要處理較少見語言、由右至左的文字、或複雜字母(如天城文、泰文等),請務必充分測試。
無離線選項
不像 Tesseract,你無法離線執行 DeepSeek OCR。需要網路連線、API 存取及接受的延遲。
11. 常見問題
DeepSeek OCR 要多少費用?
我沒有目前定價。請查 DeepSeek 官方網站取得最新費率。很可能採 Token 制,類似其他 LLM API。
可以免費使用嗎?
DeepSeek 可能提供免費方案或試用,請查其網站。
和 Google Vision 有什麼不同?
用途不同。DeepSeek OCR 更適合需要 AI 理解的長文件。Google Vision 更擅長辨識手寫和文字以外的影像分析。
語境壓縮會不會遺失資訊?
可視為智能有損壓縮。可保留核心語意、結構和主要資訊,但可能捨棄冗餘的視覺細節或非關鍵格式資訊。目的不是畫素完美還原,而是讓 LLM 能高效且準確理解文件。
這和 ZIP 壓縮有什麼不同?
完全不同。ZIP 是無損檔案壓縮,能減少儲存空間。解壓後仍是完整複本。但 LLM 仍需處理完整、未壓縮的文字,消耗大量 Token。
DeepSeek 的語境壓縮是語意壓縮。它減少送進 LLM 分析的 Token 數量,降低 AI 運算成本,也可壓進 context window。
一定要用 DeepSeek 自家 LLM 嗎?
是的。語境壓縮深度整合於 DeepSeek 的語言模型。壓縮後的 Token 格式是專有的,專為 DeepSeek 模型設計。你無法將這些壓縮 Token 給 GPT-4 或 Claude 用。
在簡單純文字影像也有壓縮效果嗎?
效果較不明顯。這技術在複雜排版、混合文字與圖像、大片空白的文件表現最佳。若只是純文字,Token 數可能與傳統 OCR 類似,但仍能受惠於簡化、全包 API 呼叫。
處理 100 頁 PDF 的預估時間與費用?
時間:根據公開資料,每頁平均數秒。
花費:如傳統 Vision-LLM 每頁需 2,000 Token,而 DeepSeek OCR 只需 300,100 頁文件的 Token 成本可能僅為傳統方法的 15%。但精準數字請查 DeepSeek 官方定價。
能理解圖表、圖形或流程圖嗎?
很擅長萃取文字元件(標題、軸標籤、圖例)。但無法像「哪個長條最高?」或「流程圖下一步是什麼?」這類解讀視覺邏輯,更進階的多模態模型更適合這類任務。
若文件畫質很差會怎樣?
如所有 OCR,輸入品質直接影響輸出。雖然 DeepSeek OCR 有影像前處理以減少雜訊,但嚴重畫質缺陷、模糊或低解析度都會大幅降低準確度。請優先使用 300 DPI 以上的高品質掃描。
最後心得
DeepSeek OCR 的語境壓縮不是華麗技術,而是實用解決方案。
它降低成本、簡化架構,終於讓用 LLM 分析長文件成為現實。
它不會取代所有 OCR 工具。隱私敏感或手寫情境,Tesseract 和 Google Vision 仍有優勢。但若需可擴展的 AI 文件理解,DeepSeek 的方式確實是新突破。
試試用它解析你最長的文件。如果一次處理完且答案完整,你會立刻看出差異。
資源:
- DeepSeek OCR 部落格文章
- The Decoder:DeepSeek 的 OCR 壓縮
- DeepSeek API Docs(官方網站)
免責聲明: 本文依據公開資料及有限的實際測試整理,實際使用前請務必參考官方文件確認細節。