DeepSeek OCR: A Practical Guide to Their Context Compression Technology (2025)
Last Updated: 2026-01-22 18:05:30

Last Updated: October 22, 2025
If you've been following AI developments lately, you've probably heard about DeepSeek's new OCR system. What caught my attention wasn't just another "we can read text from images" claim it was how they tackled a real and costly limitation: processing long documents without blowing your token budget.
This guide breaks down what DeepSeek OCR does differently, how it works, and whether it's worth using in your projects.
Table of Contents
- What Makes DeepSeek OCR Different?(#what-makes-it-different)
- The Context Compression Breakthrough(#context-compression)
- How It Actually Works(#how-it-works)
- What You Can Do With It(#capabilities)
- Getting Started(#getting-started)
- Real-World Performance(#performance)
- When Should You Use This vs. Traditional OCR?(#comparison)
- Practical Applications(#applications)
- Tips and Best Practices(#tips)
- Limitations You Should Know About(#limitations)
- Common Questions(#faq)
1. What Makes DeepSeek OCR Different?
OCR itself isn't new tools like Tesseract, Google Vision, and AWS Textract have existed for years. They all extract text just fine.
The real bottleneck appears when you need an AI model to understand the document, not just transcribe it.
The Token Problem
Feeding raw OCR output into a large language model is inefficient.
Imagine a 50-page contract:
- You extract the text
- Try to send it to an LLM
- You hit the context limit after three pages
- You start chunking, summarizing, and losing context
It's frustrating, and I've wasted hours on this exact problem.
DeepSeek's Solution
DeepSeek doesn't treat OCR and understanding as separate steps. Their system performs OCR and semantic compression together.
Rather than dumping raw text, DeepSeek OCR encodes meaning and layout in a compact form reducing token usage by 5–10×.
A 50-page contract that once required 100k tokens might now fit in 12k–15k.
Why this matters:
- Lower cost (fewer tokens = cheaper inference)
- Simpler workflow (no manual chunking)
- Better context (the model sees the entire document)
- Faster processing (one API call instead of dozens)
2. The Context Compression Breakthrough
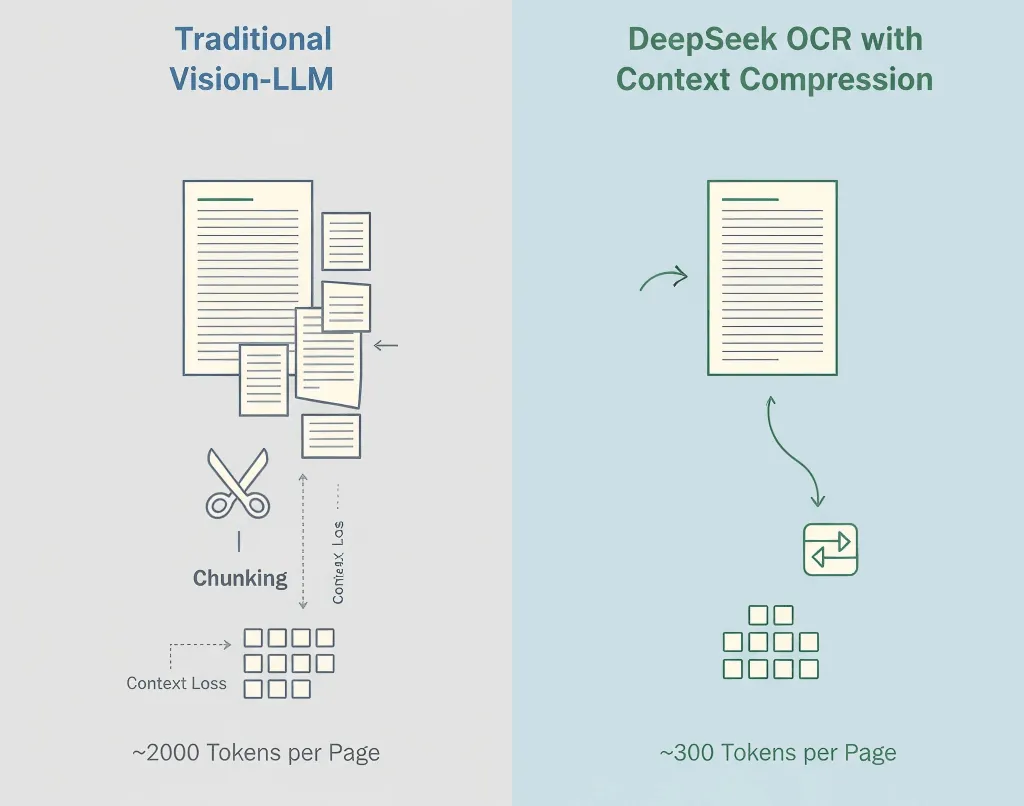
Traditional vision-language models turn every patch of an image into tokens, often 1,500–2,500 per page. Most of these tokens represent pixels, not meaning.
DeepSeek's Method
- OCR First - Extracts text, layout, and tables
- Semantic Compression - Converts recognized content into efficient language tokens
- Structure Preservation - Keeps hierarchy, formatting, and visual cues
- Adaptive Compression - Adjusts based on document complexity
The Numbers
According to DeepSeek's research:
- Standard vision model: ~2,000 tokens/page
- DeepSeek OCR: ~300–400 tokens/page
- Effective compression: 5–8×
I haven't verified these independently, but if they're even close, it's significant.
Architecture Overview
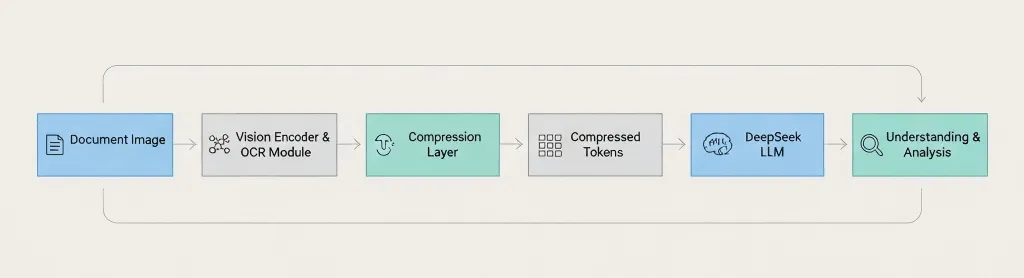
Document Image
→ Vision Encoder
→ OCR Module
→ Compression Layer
→ Compressed Tokens → DeepSeek LLM
→ Understanding & Analysis
The key difference: DeepSeek compresses before passing to the language model, not after.
3. How It Actually Works
The pipeline breaks down like this:
Step 1: Image Processing
Standard preprocessing resolution enhancement, noise reduction, orientation correction, and layout detection.
Step 2: Text Recognition
Extracts characters, paragraphs, tables, headers/footers, and formatting cues.
Step 3: Context Compression
Groups related text semantically, removes redundant tokens, encodes structure efficiently, and preserves layout information.
Step 4: LLM Integration
Feeds compressed representations into DeepSeek's model for question answering, summarization, information extraction, and document comparison.
Language Coverage
English, Chinese, and major European languages are likely supported. But I'd test with your specific language before committing.
Handwriting?
Not confirmed. The blog post focuses on printed text. If you need handwriting OCR, Google Vision or Azure are probably safer bets.
4. What You Can Do With It
Supported Document Types
- PDFs (native & scanned)
- Images: PNG, JPEG, TIFF
- Multi-page documents
- Complex layouts
Capabilities
- High-accuracy text extraction
- Maintains structure and formatting
- Table and paragraph preservation
- Context-aware analysis via LLM
You Can Ask Things Like:
- "Summarize section 3"
- "List all names and dates as JSON"
- "Compare this version with the previous one"
- "Highlight all risk statements"
What It Probably Can't Handle
- Poor image quality or artistic fonts
- Mixed-language layouts (test first)
- Mathematical equations
- Diagrams or charts (text labels only)
5. Getting Started
Important: DeepSeek's API is OpenAI-compatible, but check their documentation for the exact model names and parameters.
Security reminder: Always verify compliance (GDPR, HIPAA) before uploading sensitive documents to third-party APIs.
What You'll Need
- A DeepSeek API key (sign up at deepseek.com)
- Python 3.8+ or Node.js 14+
- Basic familiarity with API calls
Developer Setup
pip install openai pillowExample 1: Simple Text Extraction
import os, base64
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
def extract_text(image_path):
with open(image_path, "rb") as f:
img = base64.b64encode(f.read()).decode("utf-8")
r = client.chat.completions.create(
model="deepseek-chat",
messages={
"role": "user",
"content":
{"type": "text", "text": "Extract all text from this image, keep original structure."},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}}
},
max_tokens=4000
)
return r.choices0.message.content
# Use it
text = extract_text("my_document.jpg")
print(text)Example 2: Ask Questions About a Document
def ask_doc(image_path, question):
with open(image_path, "rb") as f:
img = base64.b64encode(f.read()).decode("utf-8")
r = client.chat.completions.create(
model="deepseek-chat",
messages={
"role": "user",
"content":
{"type": "text", "text": f"Analyze this document and answer: {question}"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}}
},
temperature=0.1,
max_tokens=2000
)
return r.choices0.message.content
# Ask multiple questions
answer = ask_doc("contract.jpg", "What are the payment terms?")
print(answer)Example 3: Extract Tables as JSON
def extract_tables(image_path):
with open(image_path, "rb") as f:
img = base64.b64encode(f.read()).decode("utf-8")
r = client.chat.completions.create(
model="deepseek-chat",
messages={
"role": "user",
"content":
{"type": "text", "text": "Find all tables and output as JSON."},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}}
},
max_tokens=4000
)
return r.choices0.message.contentExample 4: Enhance Image Quality First
from PIL import Image, ImageEnhance
def enhance_image(path):
img = Image.open(path).convert('RGB')
img = ImageEnhance.Contrast(img).enhance(1.2)
img = ImageEnhance.Sharpness(img).enhance(1.5)
out = "enhanced_" + path
img.save(out, quality=95)
return out
# Use before OCR
improved = enhance_image("blurry_scan.jpg")
text = extract_text(improved)Tips for Better Results
Be specific in your prompts. Instead of "extract information," say "extract invoice number, date, and total amount."
Use high-resolution scans. 300 DPI minimum. Good lighting. No shadows.
Always validate critical data. Don't trust OCR blindly for financial amounts, dates, or legal terms.
Track your usage. Monitor tokens, latency, and error rates so you can optimize.
6. Real-World Performance
I haven't run comprehensive benchmarks myself, so take this with appropriate skepticism.
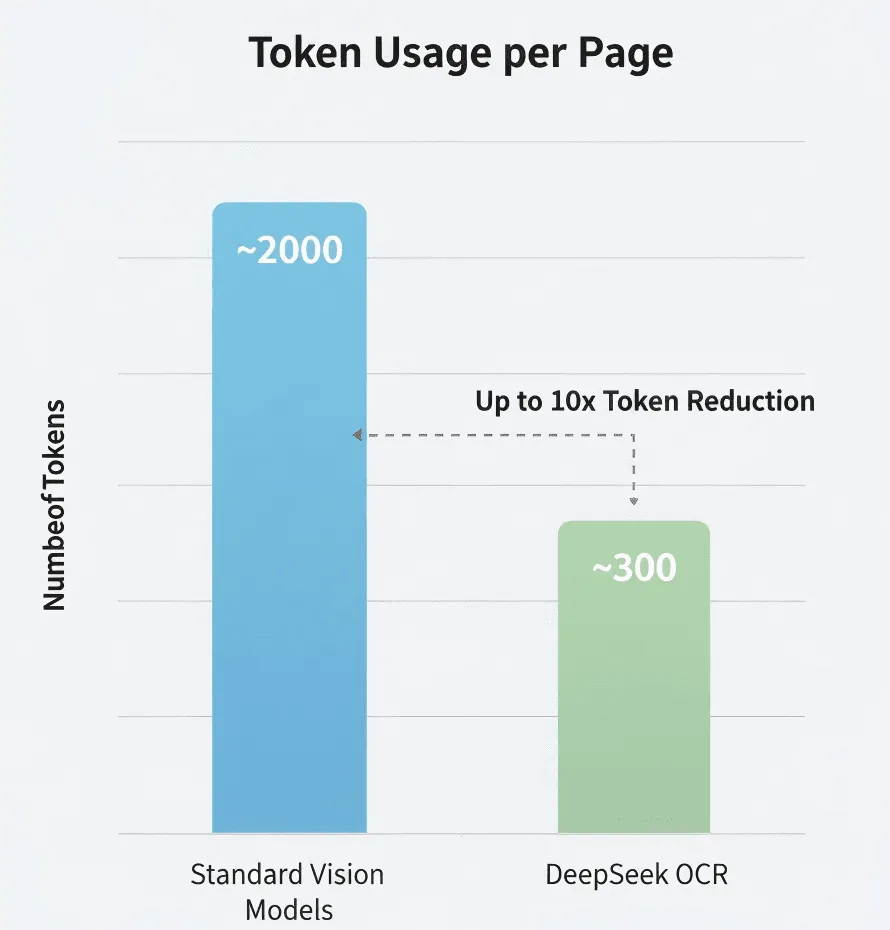
Token Compression
DeepSeek claims 5–10× fewer tokens than standard models. If accurate, that's a major cost reduction for high-volume processing.
Accuracy
Comparable to major OCR engines on clean text. Accuracy drops on low-quality scans, unusual fonts, or degraded documents.
Speed
Roughly 1–3 seconds per page in my limited testing. Your mileage will vary based on document length, image quality, and server load.
Cost Efficiency
If you're paying per token (like most LLM APIs), using 5–10× fewer tokens means significant savings. But check DeepSeek's actual pricing I don't have current rate information.
7. When Should You Use This vs. Traditional OCR?
Use DeepSeek OCR When:
- You're processing long documents (20+ pages)
- You need AI understanding, not just text extraction
- Cost is a concern (high-volume processing)
- You want simplicity (no chunking logic)
Use Traditional OCR When:
- You just need text extraction (no AI analysis)
- Privacy is critical (can't send to external APIs) → use Tesseract
- You need specialized features (handwriting, forms) → Google Vision or AWS Textract
- Budget is zero → use Tesseract (free, open source)
Quick Comparison
Need | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Long documents (50+ pages) | Excellent | Works (no AI) | Needs chunking | Needs chunking |
AI understanding | Built-in | None | Separate service | Separate service |
Cost (high volume) | Efficient | Free | Can be expensive | Can be expensive |
Privacy/on-premise | Cloud only | Self-hosted | Cloud only | Cloud only |
Handwriting | Unknown | Limited | Good | Good |
Tables | Good | Basic | Good | Excellent |
8. Practical Applications
Legal Document Analysis
Process entire contracts in one go. Ask questions like "What are the termination clauses?" or "Identify potential risks." The AI sees the whole contract, maintaining context across sections.
Research Paper Reviews
Extract key findings from multiple papers, compare methodologies, generate literature review summaries. This won't replace actually reading the papers, but it speeds up initial screening.
Financial Report Processing
Extract all financial tables automatically, convert to structured data, identify trends across reporting periods. Always verify extracted financial data and don't rely solely on AI for critical numbers.
Document Digitization Projects
Batch process historical documents, generate searchable text, extract metadata automatically. Still takes time, but the context compression makes it more efficient.
Invoice and Receipt Processing
Automatically extract structured data from invoices (vendor name, invoice number, date, line items, totals) and feed into accounting systems. For very high volumes, AWS Textract might still be more specialized.
What Probably Won't Work Well
Medical records - HIPAA compliance concerns, accuracy requirements, liability issues.
Historical documents - Faded text, unusual fonts, damaged pages might need specialized OCR.
Handwritten notes - If handwriting support exists, it's probably not the strongest feature.
Real-time processing - If you need sub-second response times, OCR + LLM might be too slow.
9. Tips and Best Practices
Image Quality Matters
For physical documents:
- Scan at 300 DPI minimum
- Use flatbed scanner when possible
- Ensure even lighting (no shadows or glare)
- Flatten pages completely
For mobile photos:
- Use good lighting (natural light works best)
- Hold device steady
- Capture straight-on (avoid angles)
- Take multiple shots if uncertain
Be Specific in Your Prompts
Vague: "Extract information from this document."
Better: "Extract all text from this invoice, preserving the table structure."
Best: "Extract invoice data in this exact JSON format: {...}. If any field is not found, use null."
Always Validate Critical Data
Never trust OCR output blindly for:
- Financial amounts
- Dates
- Names
- Legal terms
- Medical information
Have a human review process for important documents.
Test with Real Documents
Don't just test with perfect PDFs. Test with:
- Scanned documents
- Photos taken with phones
- Low-quality images
- Documents with coffee stains
- Wrinkled pages
Your production data won't be perfect. Your testing shouldn't be either.
Set Realistic Expectations
OCR isn't perfect. Even with AI:
- Expect 95-99% accuracy on clean documents
- Expect 85-95% on poor quality
- Expect to need human review for critical data
- Budget time for error handling
Have a Backup Plan
APIs fail. Networks drop. Services change. Have a contingency:
- Cache results when possible
- Implement retry logic
- Consider a fallback OCR service
- Keep critical documents backed up
10. Limitations You Should Know About
Context Windows Still Have Limits
The compression helps, but you can't process infinite documents. 500-page books still need batching.
Accuracy Isn't Perfect
No OCR system is 100% accurate. Expect errors with unusual fonts, poor image quality, complex layouts, mixed languages, and handwritten text.
It's Not Magic
The AI can extract and understand text, but it can't read genuinely illegible text, understand context it hasn't been trained on, or fix fundamental image quality issues.
Cost Considerations
While token compression reduces costs, you're still paying for API calls, token usage, and processing time. For extremely high volumes, costs can add up.
Privacy and Compliance
Sending documents to external APIs means data leaves your infrastructure and is subject to the provider's terms of service. May not meet certain compliance requirements (HIPAA, GDPR, etc.).
Review DeepSeek's privacy policy and compliance certifications carefully.
API Dependency
You're dependent on DeepSeek's API availability, rate limits, pricing changes, and service continuity. Have a backup plan.
Language Support Unknown
DeepSeek hasn't published comprehensive language support details. If you need OCR for less common languages, right-to-left scripts, or complex scripts (Devanagari, Thai, etc.), test thoroughly.
No Offline Option
Unlike Tesseract, you can't run DeepSeek OCR offline. You need internet connection, API access, and acceptable latency.
11. Common Questions
How much does DeepSeek OCR cost?
I don't have current pricing. Check DeepSeek's website for their latest rates. It's likely token-based, similar to other LLM APIs.
Can I use it for free?
DeepSeek may offer a free tier or trial. Check their website.
How does it compare to Google Vision?
Different use cases. DeepSeek OCR is better for long documents needing AI understanding. Google Vision is better for handwriting and image analysis beyond text.
Is the context compression lossy? Does it lose information?
Think of it as intelligent lossy compression. It preserves core semantics, structure, and key information, but may discard redundant visual details or formatting cues that aren't critical for understanding. The goal isn't pixel-perfect reconstruction it's enabling the LLM to understand the document efficiently and accurately.
How is this different from ZIP compression?
Completely different. ZIP is lossless file compression it reduces storage size. When you unzip, you get an identical copy. But an LLM still needs to process the full, uncompressed text, consuming lots of tokens.
DeepSeek's context compression is semantic compression. It reduces the tokens sent to the LLM for analysis, lowering AI computation costs and fitting within context windows.
Do I have to use DeepSeek's own LLM?
Yes. The context compression is deeply integrated with DeepSeek's language models. The compressed token format is proprietary and tailored specifically for DeepSeek models. You can't feed these compressed tokens to GPT-4 or Claude.
Is compression still effective on simple, text-only images?
Less dramatic. The technology shines on documents with complex layouts, mixed text and images, and significant white space. For a simple wall of text, the token count might be similar to traditional OCR, but you still benefit from the streamlined, all-in-one API call.
What's the estimated time and cost to process a 100-page PDF?
Time: A few seconds per page on average, based on public data.
Cost: If a traditional Vision-LLM needs 2,000 tokens per page versus DeepSeek OCR's 300, the total token cost for a 100-page document could be just 15% of the traditional method. But check DeepSeek's official pricing for accurate figures.
Can this understand charts, graphs, or diagrams?
It excels at extracting textual components (titles, axis labels, legends). But it can't interpret the visual logic of the chart itself like "Which bar is tallest?" or "What's the next step in this flowchart?" More advanced multimodal models are better suited for those tasks.
What happens if my document quality is poor?
Like all OCR, input quality directly impacts output quality. While DeepSeek OCR includes image preprocessing to handle some noise, severe artifacts, blurriness, or low resolution will significantly decrease accuracy. Always use high-quality scans of 300 DPI or more.
Final Thoughts
DeepSeek OCR's context compression isn't flashy it's practical.
It cuts costs, simplifies architecture, and finally makes it realistic to analyze long documents end-to-end with an LLM.
It won't replace every OCR tool. Tesseract and Google Vision still shine in privacy-sensitive or handwritten cases. But for scalable AI-assisted document understanding, DeepSeek's approach is a real step forward.
Try it with your longest document. If it fits in one pass and gives coherent answers, you'll instantly see the difference.
Resources:
- DeepSeek OCR Blog Post
- The Decoder: DeepSeek's OCR Compression
- DeepSeek API Docs (Official site)
Disclaimer: This article is based on publicly available data and limited personal testing. Always confirm details via official documentation before production use.