DeepSeek OCR: Bağlam Sıkıştırma Teknolojisi Üzerine Pratik Bir Rehber (2025)
Son Güncelleme: 2026-01-22 18:05:30

Son Güncelleme: 22 Ekim 2025
Eğer son zamanlarda AI gelişmelerini takip ettiyseniz, muhtemelen DeepSeek'in yeni OCR sistemini duymuşsunuzdur. Benim ilgimi çeken sadece bir “görsellerden metin okuyabiliyoruz” iddiası değildi, asıl ilgimi çeken uzun belgeleri işleme konusundaki gerçek ve maliyetli bir sınırlamayı nasıl ele aldıklarıydı: jeton bütçenizi aşmadan uzun belgeleri işleyebilmek.
Bu rehber, DeepSeek OCR'ın neyi farklı yaptığını, nasıl çalıştığını ve projelerinizde kullanmaya değer olup olmadığını açıklıyor.
İçindekiler
- DeepSeek OCR’ı Farklı Kılan Ne?(#what-makes-it-different)
- Bağlam Sıkıştırmada Atılım(#context-compression)
- Gerçekte Nasıl Çalışıyor?(#how-it-works)
- Bununla Neler Yapabilirsiniz?(#capabilities)
- Başlarken(#getting-started)
- Gerçek Dünya Performansı(#performance)
- Geleneksel OCR’a Karşı Ne Zaman Bunu Kullanmalısınız?(#comparison)
- Pratik Uygulamalar(#applications)
- İpuçları ve En İyi Uygulamalar(#tips)
- Bilmeniz Gereken Sınırlamalar(#limitations)
- Sıkça Sorulan Sorular(#faq)
1. DeepSeek OCR’ı Farklı Kılan Ne?
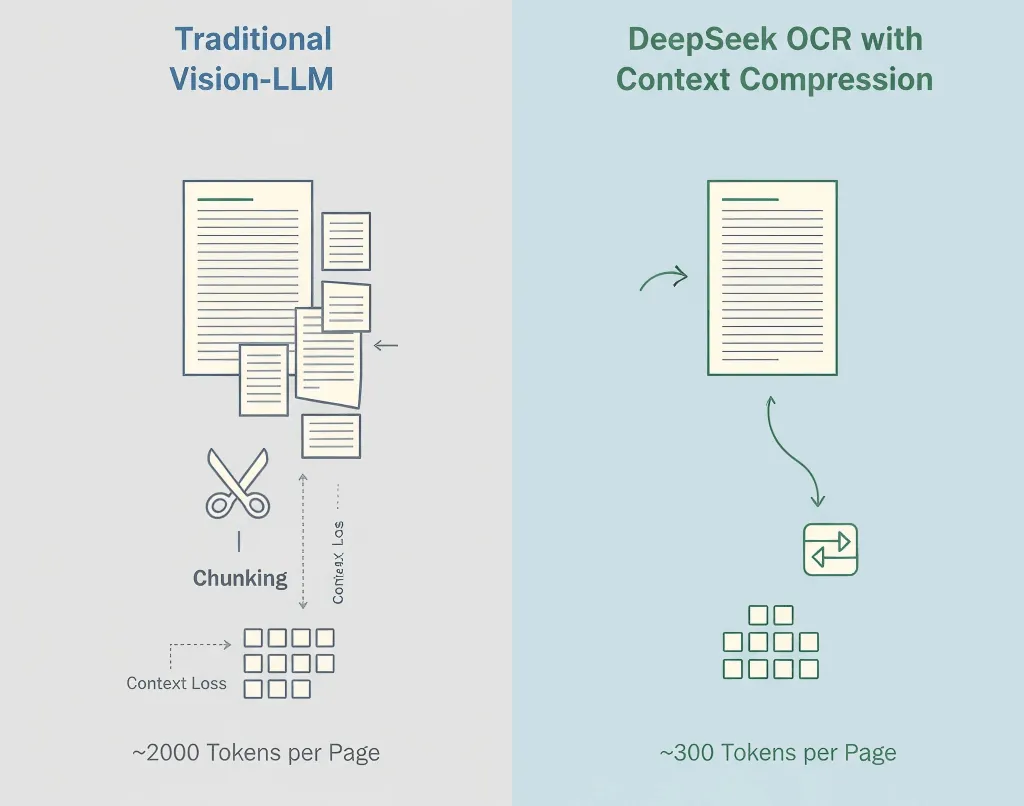
OCR’in kendisi yeni değil; Tesseract, Google Vision ve AWS Textract gibi araçlar yıllardır var. Hepsi metni gayet iyi çıkarıyor.
Asıl darboğaz, bir AI modelinin belgeyi anlamasını istediğinizde ortaya çıkıyor, sadece çözmesini değil.
Jeton Problemi
Ham OCR çıktısını büyük bir dil modeline göndermek verimsizdir.
50 sayfalık bir sözleşmeyi hayal edin:
- Metni çıkarıyorsunuz
- LLM’ye göndermeye çalışıyorsunuz
- Üçüncü sayfadan sonra bağlam sınırına takılıyorsunuz
- Parçalara ayırmaya, özetlemeye ve bağlamı kaybetmeye başlıyorsunuz
Bu oldukça sinir bozucu ve tam olarak bu sorun yüzünden saatler harcadım.
DeepSeek’in Çözümü
DeepSeek, OCR ve anlamayı ayrı adımlar olarak görmüyor. Sistemleri OCR’ı ve anlamsal sıkıştırmayı birlikte gerçekleştiriyor.
Ham metni dökmek yerine, DeepSeek OCR anlamı ve düzeni kompakt bir biçimde kodluyor - bu da jeton kullanımını 5–10 kat azaltıyor.
Eskiden 100k jeton gerektiren 50 sayfalık bir sözleşme şimdi 12k–15k jetonda sığabiliyor.
Neden önemli:
- Daha düşük maliyet (daha az jeton = daha ucuz çıkarım)
- Daha basit iş akışı (manuel ayırmaya gerek yok)
- Daha iyi bağlam (model tüm belgeyi görebiliyor)
- Daha hızlı işleme (bir API çağrısı, onlarcası yerine)
2. Bağlam Sıkıştırmada Atılım
Geleneksel görsel-dil modelleri, bir görüntünün her yamasını jetonlara çevirir; çoğunlukla sayfa başına 1.500–2.500 jeton olur. Bu jetonların çoğu anlamı değil, pikselleri temsil eder.
DeepSeek’in Yöntemi
- Önce OCR - Metin, düzen ve tabloları çıkarır
- Anlamsal Sıkıştırma - Tanınan içeriği verimli dil jetonlarına çevirir
- Yapıyı Korumak - Hiyerarşi, biçimlendirme ve görsel ipuçlarını korur
- Uyarlanabilir Sıkıştırma - Belge karmaşıklığına göre ayarlama yapar
Sayılar
DeepSeek’in araştırmasına göre:
- Standart görsel model: ~2.000 jeton/sayfa
- DeepSeek OCR: ~300–400 jeton/sayfa
- Etkin sıkıştırma: 5–8 kat
Bunları bağımsız olarak doğrulamadım, ama yakın bile olsalar bu önemli.
Mimari Genel Bakış
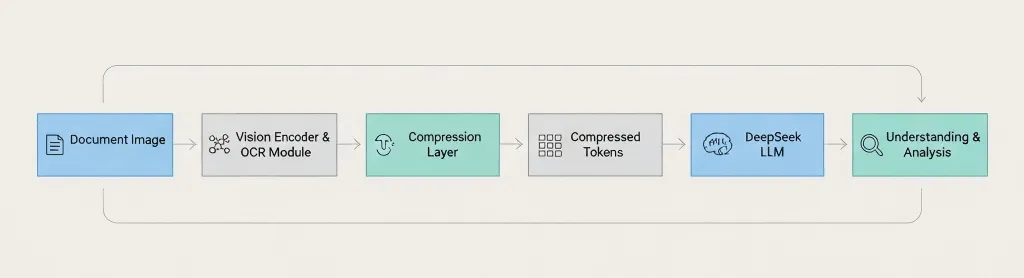
Belge Görseli → Görsel Kodlayıcı → OCR Modülü → Sıkıştırma Katmanı → Sıkıştırılmış Jetonlar → DeepSeek LLM → Anlama & Analiz Ana fark: DeepSeek, dili modele iletmeden önce sıkıştırma yapıyor, sonra değil. 3. Gerçekte Nasıl Çalışıyor?
Boru hattı şu şekilde ilerliyor:
Adım 1: Görüntü İşleme
Standart ön işleme: çözünürlük artırma, gürültü azaltma, yön düzeltme, düzen tespiti.
Adım 2: Metin Tanıma
Karakterler, paragraflar, tablolar, başlıklar/dipnotlar ve biçimlendirme ipuçlarını çıkarır.
Adım 3: Bağlam Sıkıştırma
İlgili metni anlamsal olarak gruplar, gereksiz jetonları atar, yapıyı verimli kodlar ve düzen bilgisini korur.
Adım 4: LLM Entegrasyonu
Sıkıştırılmış temsilleri DeepSeek’in modeline aktarır; soru yanıtlama, özetleme, bilgi çıkarımı ve belge karşılaştırma için.
Dil Desteği
İngilizce, Çince ve başlıca Avrupa dilleri muhtemelen destekleniyor. Ancak, bağlanmadan önce kendi dilinizle test etmenizi öneririm.
El Yazısı?
Doğrulanmadı. Blog gönderisi basılı metne odaklanıyor. El yazısı OCR gerekiyorsa, Google Vision veya Azure büyük ihtimalle daha güvenli tercihlerdir.
4. Bununla Neler Yapabilirsiniz?
Desteklenen Doküman Türleri
- PDF’ler (yerel & taranmış)
- Görüntüler: PNG, JPEG, TIFF
- Çok sayfalı belgeler
- Karmaşık düzenler
Yetenekler
- Yüksek doğruluklu metin çıkarımı
- Yapı ve biçimlendirmeyi korur
- Tablo ve paragraf bütünlüğünü koruma
- LLM ile bağlamsal analiz
Şunları Sorabilirsiniz:
- "3. bölümü özetle"
- "Tüm adları ve tarihleri JSON olarak listele"
- "Bu sürümü öncekiyle karşılaştır"
- "Tüm risk ifadelerini vurgula"
Büyük İhtimalle Yapamadıkları
- Düşük görüntü kalitesi ya da sanatsal fontlar
- Karışık dilli düzenler (önce test edin)
- Matematiksel denklemler
- Şema ya da grafikler (yalnızca metin etiketleri)
5. Başlarken
Önemli: DeepSeek’in API’si OpenAI ile uyumlu, ancak tam model adları ve parametreler için belgelerine bakın.
Güvenlik hatırlatması: Hassas belgeleri üçüncü taraf API’lara yüklemeden önce her zaman uyumluluğu (GDPR, HIPAA) doğrulayın.
İhtiyacınız Olanlar
- Bir DeepSeek API anahtarı (deepseek.com’dan kayıt olun)
- Python 3.8+ veya Node.js 14+
- API çağrıları konusunda temel bilgi
Geliştirici Kurulumu
pip install openai pillowÖrnek 1: Basit Metin Çıkarma
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Örnek 2: Bir Belge Hakkında Soru Sor
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Örnek 3: Tabloları JSON Olarak Çıkar
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentÖrnek 4: Önce Görüntü Kalitesini Yükselt
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Daha İyi Sonuçlar İçin İpuçları
Açık talimatlar verin. "Bilgi çıkar" yerine "fatura numarası, tarih ve toplam tutarı çıkar" deyin.
Yüksek çözünürlüklü taramalar kullanın. En az 300 DPI. İyi aydınlatma. Gölgeler olmasın.
Kritik verileri her zaman doğrulayın. Finansal tutarlar, tarihler ya da yasal terimler için OCR’ye körü körüne güvenmeyin.
Kullanımınızı takip edin. Jetonları, gecikmeleri ve hata oranlarını izleyin, böylece optimize edebilirsiniz.
6. Gerçek Dünya Performansı
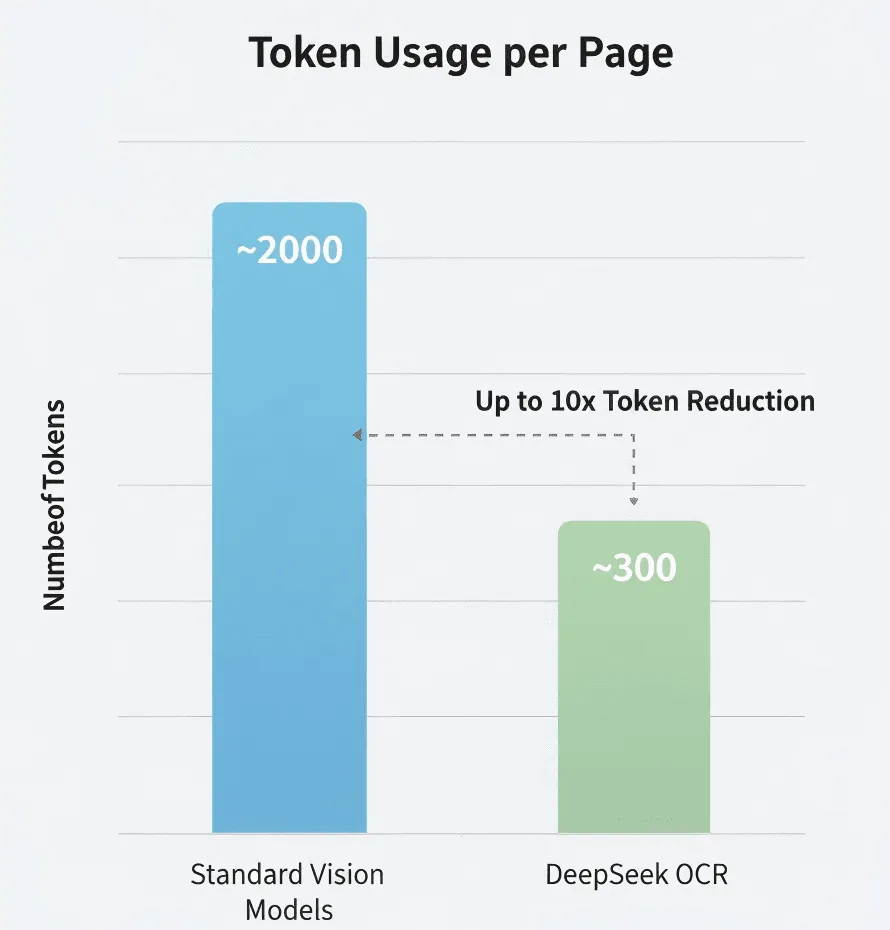
Kapsamlı kıyaslamalar yapmadığım için, buna uygun bir şüpheyle yaklaşın.
Jeton Sıkıştırması
DeepSeek, standart modellere göre 5–10× daha az jeton kullandığını iddia ediyor. Doğruysa, bu yüksek hacimli işlemler için önemli bir maliyet azalması anlamına geliyor.
Doğruluk
Temiz metin üzerinde büyük OCR motorlarıyla karşılaştırılabilir düzeyde. Düşük kaliteli taramalarda, alışılmadık yazı tiplerinde veya bozulmuş belgelerde doğruluk azalıyor.
Hız
Sınırlı testlerimde sayfa başına yaklaşık 1–3 saniye. Sonuçlarınız belge uzunluğuna, görüntü kalitesine ve sunucu yüküne göre değişiklik gösterebilir.
Maliyet Verimliliği
Eğer jeton başına ödeme yapıyorsanız (çoğu LLM API'si gibi), 5–10× daha az jeton kullanmak önemli bir tasarruf sağlar. Ancak DeepSeek'in gerçek fiyatlandırmasını kontrol edin; güncel ücret bilgim yok.
7. Ne Zaman Bunu Klasik OCR’a Kıyasla Kullanmalısınız?
DeepSeek OCR’ı Şu Durumlarda Kullanın:
- Uzun belgeleri işliyorsanız (20+ sayfa)
- Sadece metin çıkarmak değil, yapay zekâ anlayışı da istiyorsanız
- Maliyet önemliyse (yüksek hacimli işleme)
- Basitlik istiyorsanız (parçalama mantığı gerekmez)
Geleneksel OCR’ı Şu Durumlarda Kullanın:
- Sadece metin çıkarmak istiyorsanız (AI analizi yok)
- Gizlilik kritikse (dış API’ye gönderemiyorsanız) → Tesseract kullanın
- Özel özelliklere ihtiyacınız varsa (el yazısı, formlar) → Google Vision veya AWS Textract kullanın
- Bütçeniz sıfırsa → Tesseract kullanın (ücretsiz, açık kaynak)
Hızlı Karşılaştırma
İhtiyaç | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Uzun belgeler (50+ sayfa) | Mükemmel | Çalışır (AI yok) | Parçalara ayırmak gerekir | Parçalara ayırmak gerekir |
Yapay zekâ anlayışı | Entegre | Yok | Ayrı servis | Ayrı servis |
Maliyet (yüksek hacim) | Verimli | Ücretsiz | Pahalı olabilir | Pahalı olabilir |
Gizlilik/sunucu üzerinde | Sadece bulut | Kendi sunucunuzda | Sadece bulut | Sadece bulut |
El yazısı | Bilinmiyor | Sınırlı | İyi | İyi |
Tablolar | İyi | Temel | İyi | Mükemmel |
8. Pratik Uygulamalar
Hukuki Belge Analizi
Tüm sözleşmeleri tek seferde işleyin. "Fesih maddeleri neler?", "Potansiyel riskleri tanımla." gibi sorular sorun. Yapay zekâ tüm sözleşmeyi bir bütün olarak görür ve bölümler arasında bağlamı korur.
Akademik Makale İncelemeleri
Birden fazla makaleden ana bulguları çıkarın, metodolojileri karşılaştırın, literatür özeti oluşturun. Bu yöntem makaleleri okumayı tamamen ortadan kaldırmaz, ancak ilk taramayı hızlandırır.
Finansal Rapor İşleme
Tüm finansal tabloları otomatik olarak çıkarın, yapılandırılmış veriye dönüştürün, rapor dönemleri boyunca eğilimleri analiz edin. Her zaman çıkarılan finansal verileri doğrulayın ve kritik rakamlar için sadece yapay zekâya güvenmeyin.
Belge Dijitalleştirme Projeleri
Tarihi belgeleri toplu olarak işleyin, aranabilir metin üretin, meta verileri otomatik olarak çıkarın. Yine zaman alır ancak bağlam sıkıştırması süreci daha verimli hale getirir.
Fatura ve Makbuz İşleme
Faturalardan (satıcı adı, fatura numarası, tarih, kalemler, toplamlar) otomatik olarak yapılandırılmış veri çıkarın ve muhasebe sistemlerine aktarın. Çok yüksek hacimli işlemlerde AWS Textract hâlâ daha uzman olabilir.
Muhtemelen İyi Çalışmayacak Alanlar
Tıbbi kayıtlar - HIPAA uyumluluğu, doğruluk gereksinimleri, sorumluluk riskleri.
Tarihi belgeler - Solmuş metinler, alışılmadık yazı tipleri, hasarlı sayfalar özel OCR gerektirebilir.
El yazısı notlar - El yazısı desteği varsa bile muhtemelen en güçlü özelliği değildir.
Gerçek zamanlı işleme - Milisaniye düzeyinde yanıt süresi gerekiyorsa, OCR + LLM yavaş kalabilir.
9. İpuçları ve En İyi Uygulamalar
Görüntü Kalitesi Önemlidir
Fiziksel belgeler için:
- En az 300 DPI'da tarayın
- Mümkünse düz yataklı tarayıcı kullanın
- Eşit aydınlatma sağlayın (gölge veya yansıma olmamalı)
- Sayfaları tamamen düzleştirin
Mobil fotoğraflar için:
- İyi bir aydınlatma kullanın (doğal ışık en iyisidir)
- Cihazı sabit tutun
- Düz bir açıdan çekin (açılardan kaçının)
- Emin değilseniz birden fazla fotoğraf çekin
Komutlarınızda Spesifik Olun
Belirsiz: "Bu belgeden bilgi çıkar."
Daha iyi: "Bu faturadaki tüm metni tablo yapısını koruyarak çıkar."
En iyisi: "Fatura verilerini tam olarak şu JSON formatında çıkar: {...}. Herhangi bir alan bulunamazsa null olarak kullan."
Kritik Verileri Daima Doğrulayın
OCR çıktısına şu alanlar için asla körü körüne güvenmeyin:
- Mali tutarlar
- Tarihler
- İsimler
- Hukuki terimler
- Tıbbi bilgiler
Önemli belgeler için insan tarafından inceleme süreci oluşturun.
Gerçek Belgelerle Test Edin
Sadece mükemmel PDF'lerle test etmeyin. Şunlarla da test edin:
- Tarama belgeleri
- Telefonla çekilmiş fotoğraflar
- Düşük kaliteli görüntüler
- Kahve lekesi olan belgeler
- Buruşmuş sayfalar
Üretim verileriniz mükemmel olmayacak. Testleriniz de olmamalı.
Gerçekçi Beklentiler Belirleyin
OCR kusursuz değildir. AI ile bile:
- Temiz belgelerde %95-99 doğruluk bekleyin
- Düşük kalitede %85-95 arası bekleyin
- Kritik veriler için insan incelemesine ihtiyaç duyacağınızı unutmayın
- Hata yönetimi için zaman ayırın
Yedek Bir Planınız Olsun
API'ler arızalanır. Ağ kopar. Servisler değişir. Şu önlemleri alın:
- Mümkünse sonuçları önbelleğe alın
- Tekrar deneme mantığını uygulayın
- Yedek bir OCR servisini değerlendirin
- Kritik belgelerinizi yedekleyin
10. Bilmeniz Gereken Sınırlamalar
Bağlam Pencerelerinde Hâlâ Sınırlar Var
Sıkıştırma yardımcı olur, ancak sonsuz belge işleyemezsiniz. 500 sayfalık kitaplar hâlâ bölümlere ayrılmalı.
Doğruluk Mükemmel Değil
Hiçbir OCR sistemi %100 doğru değildir. Sıradışı yazı tiplerinde, düşük görüntü kalitesinde, karmaşık yerleşimlerde, karışık dillerde ve el yazısında hatalar bekleyin.
Sihir Değil
Yapay zeka metni çıkarıp anlayabilir, fakat gerçekten okunaksız metni okuyamaz, eğitilmediği bir bağlamı kavrayamaz veya temel görüntü kalitesi sorunlarını düzeltemez.
Maliyet Faktörleri
Token sıkıştırma maliyeti azaltsa da, hâlâ API çağrıları, token kullanımı ve işlem süresinden ücret ödersiniz. Çok büyük hacimlerde maliyet artabilir.
Gizlilik ve Uyumluluk
Belgeleri harici API'lara göndermek, verilerin altyapınızdan çıkması ve sağlayıcının hizmet şartlarına tabi olması anlamına gelir. Bazı uyumluluk gereksinimlerini (HIPAA, GDPR, vb.) karşılamayabilir.
DeepSeek'in gizlilik politikasını ve uyumluluk sertifikalarını dikkatle inceleyin.
API Bağımlılığı
DeepSeek'in API erişilebilirliğine, istek sınırlarına, fiyat değişikliklerine ve hizmet devamlılığına bağlısınız. Yedek planınız olsun.
Dil Desteği Bilinmiyor
DeepSeek kapsamlı dil desteği ayrıntılarını yayınlamadı. Daha az yaygın diller, sağdan sola yazılan diller veya karmaşık alfabeler (Devanagari, Tayca, vb.) için OCR gerekiyorsa kapsamlı test yapın.
Çevrimdışı Seçenek Yok
Tesseract'in aksine, DeepSeek OCR'ı çevrimdışı çalıştıramazsınız. İnternet bağlantısı, API erişimi ve kabul edilebilir gecikme gereklidir.
11. Sık Sorulan Sorular
DeepSeek OCR'ın fiyatı nedir?
Güncel fiyat bilgim yok. En yeni fiyatlandırma için DeepSeek'in sitesine bakın. Muhtemelen diğer LLM API'leri gibi token tabanlıdır.
Ücretsiz kullanabilir miyim?
DeepSeek ücretsiz bir katman veya deneme sunabilir. Sitelerini kontrol edin.
Google Vision ile karşılaştırıldığında nasıldır?
Farklı kullanım alanları. DeepSeek OCR, AI anlayışı gerektiren uzun belgeler için daha iyidir. Google Vision ise el yazısı ve metin ötesi resim analizinde daha güçlüdür.
Bağlam sıkıştırması kayıplı mı? Bilgi kaybı olur mu?
Bunu akıllı bir kayıplı sıkıştırma gibi düşünün. Temel anlamı, yapıyı ve ana bilgileri korur; ama kritik olmayan, tekrarlı görsel detayları veya biçim ipuçlarını atabilir. Amaç pikselle mükemmel bir dosya oluşturmak değil; LLM'nin belgeyi verimli ve doğru anlamasını sağlamak.
Bu, ZIP sıkıştırmasından nasıl farklı?
Tamamen farklı. ZIP kayıpsız dosya sıkıştırmadır; depolama boyutunu küçültür. Zip'i açınca birebir aynı kopyayı alırsınız. Ancak bir LLM, tüm, sıkıştırılmamış metni yine de işlemesi gerekir, bu da çok fazla token harcamasına yol açar.
DeepSeek'in bağlam sıkıştırması ise anlamsal sıkıştırmadır. LLM'ye analiz için gönderilen token sayısını azaltır, AI hesaplama maliyetini düşürür ve bağlam pencerelerine sığar.
DeepSeek'in kendi LLM'ini mi kullanmam gerekiyor?
Evet. Bağlam sıkıştırması DeepSeek'in dil modelleriyle derinlemesine entegredir. Sıkıştırılmış token formatı özeldir ve yalnızca DeepSeek modellerine özeldir. Bu sıkıştırılmış token'ları GPT-4 veya Claude'a veremezsiniz.
Kompresyon, sadece basit metinli görüntülerde de etkili mi?
Daha az belirgin. Teknolojinin gücü; karmaşık yerleşimli, metin ve görsellerin karışık olduğu, önemli miktarda beyaz alanın bulunduğu belgelerde ortaya çıkar. Sadece metin duvarı olan bir belgedeyse token sayısı geleneksel OCR ile benzer olabilir, yine de tek seferlik, sadeleşmiş API çağrısının avantajını yaşarsınız.
100 sayfalık bir PDF'yi işlemek ne kadar sürüyor ve maliyeti nedir?
Süre: Kamuya açık verilere göre ortalama birkaç saniye/sayfa.
Maliyet: Geleneksel bir Vision-LLM sayfa başı 2.000 token isterken DeepSeek OCR 300 token gerektiriyorsa, 100 sayfalık bir belge için toplam token maliyeti geleneksel yöntemin yalnızca %15’i olabilir. Doğru veriler için DeepSeek’in resmi fiyatlarına bakın.
Bu sistem tablo, grafik veya diyagramları anlayabilir mi?
Metinsel öğeleri (başlıklar, eksen etiketleri, açıklamalar) çıkarmada başarılıdır. Ancak bir tablonun görsel mantığını yorumlayamaz; örneğin "En uzun sütun hangisi?" veya "Bu akış diyagramında sonraki adım nedir?" gibi soruları yanıtlayamaz. Bu tür işler için gelişmiş multimodal modeller daha uygundur.
Belge kalitesi kötü olursa ne olur?
Tüm OCR'lerde olduğu gibi, giriş kalitesi çıkış kalitesini doğrudan etkiler. DeepSeek OCR bazı gürültüyü işleyebilecek görüntü ön işlemesi içerse de, aşırı bozulma, bulanıklık veya düşük çözünürlük doğruluğu ciddi şekilde azaltacaktır. Daima 300 DPI veya üzeri yüksek kaliteli taramalar kullanın.
Son Düşünceler
DeepSeek OCR'ın bağlam sıkıştırması gösterişli değil; pratik.
Maliyetleri azaltır, mimariyi sadeleştirir ve uzun belgelerin uçtan uca LLM ile analizini gerçekçi kılar.
Her OCR aracının yerini alamaz. Tesseract ve Google Vision hâlâ gizlilik veya el yazısı gerektiren durumlarda öne çıkar. Fakat ölçeklenebilir AI destekli belge anlama için DeepSeek’in yaklaşımı gerçek bir ilerleme.
En uzun belgenizle deneyin. Tek geçişte sığdırıp tutarlı cevaplar veriyorsa farkı hemen göreceksiniz.
Kaynaklar:
- DeepSeek OCR Blog Yazısı
- The Decoder: DeepSeek'in OCR Sıkıştırması
- DeepSeek API Dokümanları (Resmi site)
Feragatname: Bu makale, herkese açık veriler ve sınırlı kişisel testler temelinde hazırlanmıştır. Üretim ortamında kullanmadan önce detayları mutlaka resmi dokümantasyonla doğrulayın.