DeepSeek OCR : Guide pratique sur leur technologie de compression du contexte (2025)
Dernière mise à jour: 2026-01-22 18:05:30

Dernière mise à jour : 22 octobre 2025
Si vous suivez de près les développements de l'IA ces derniers temps, vous avez probablement entendu parler du nouveau système OCR de DeepSeek. Ce qui a retenu mon attention, ce n'est pas seulement une autre affirmation du type "nous pouvons lire le texte des images", mais la manière dont ils ont abordé une réelle limite coûteuse : traiter de longs documents sans exploser votre budget de jetons.
Ce guide explique en détail ce que DeepSeek OCR fait différemment, comment cela fonctionne et si cela vaut la peine de l'utiliser dans vos projets.
Table des matières
- Qu'est-ce qui distingue DeepSeek OCR ?(#what-makes-it-different)
- L'innovation de la compression du contexte(#context-compression)
- Comment cela fonctionne vraiment(#how-it-works)
- Ce que vous pouvez en faire(#capabilities)
- Premiers pas(#getting-started)
- Performance en conditions réelles(#performance)
- Quand l'utiliser par rapport à un OCR classique ?(#comparison)
- Applications pratiques(#applications)
- Conseils et bonnes pratiques(#tips)
- Limites à connaître(#limitations)
- Questions fréquentes(#faq)
1. Qu'est-ce qui distingue DeepSeek OCR ?
L'OCR en soi n'est pas nouveau : des outils comme Tesseract, Google Vision et AWS Textract existent depuis des années. Tous extraient le texte correctement.
Le vrai goulot d'étranglement apparaît lorsque vous avez besoin qu'un modèle d'IA comprenne le document, et non juste le transcrive.
Le problème des jetons
Envoyer la sortie brute d'un OCR dans un grand modèle de langage est inefficace.
Imaginez un contrat de 50 pages :
- Vous extrayez le texte
- Vous essayez de l'envoyer à un LLM
- Vous atteignez la limite de contexte après trois pages
- Vous commencez à découper, résumer et perdre le contexte
C'est frustrant, et j'ai perdu des heures sur ce problème précis.
La solution de DeepSeek
DeepSeek ne considère pas l'OCR et la compréhension comme des étapes séparées. Leur système réalise l'OCR et la compression sémantique en même temps.
Plutôt que de restituer du texte brut, DeepSeek OCR encode le sens et la mise en page sous forme compacte, réduisant l'utilisation de jetons par 5 à 10×.
Un contrat de 50 pages qui nécessitait autrefois 100k jetons pourrait maintenant tenir dans 12k à 15k.
Pourquoi c'est important :
- Coûts réduits (moins de jetons = inférence moins chère)
- Flux de travail plus simple (pas de découpage manuel)
- Meilleur contexte (le modèle voit l'intégralité du document)
- Traitement plus rapide (un appel API au lieu de dizaines)
2. L'innovation de la compression du contexte
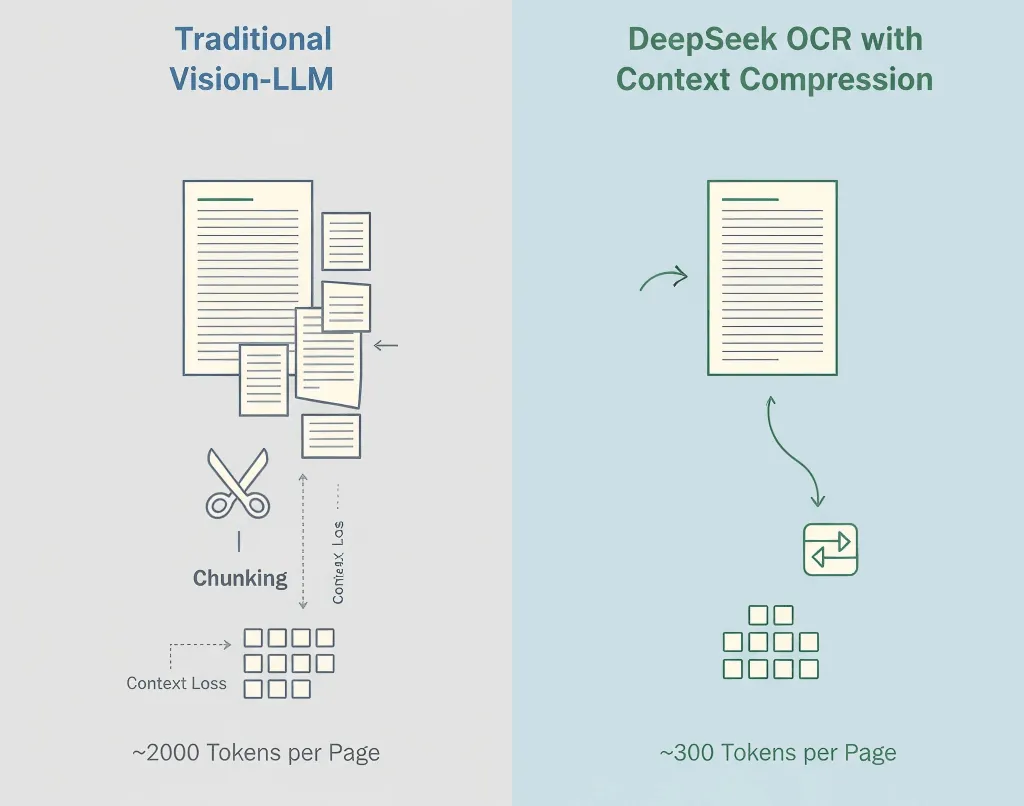
Les modèles visiolangages traditionnels transforment chaque morceau d'une image en jetons, souvent 1 500 à 2 500 par page. La plupart de ces jetons représentent des pixels et non du sens.
La méthode DeepSeek
- OCR en premier - Extraction du texte, de la mise en page et des tableaux
- Compression sémantique - Convertit le contenu reconnu en jetons linguistiques efficaces
- Préservation de la structure - Maintient la hiérarchie, la mise en forme et les indices visuels
- Compression adaptative - S'ajuste en fonction de la complexité du document
Les chiffres
D'après les recherches de DeepSeek :
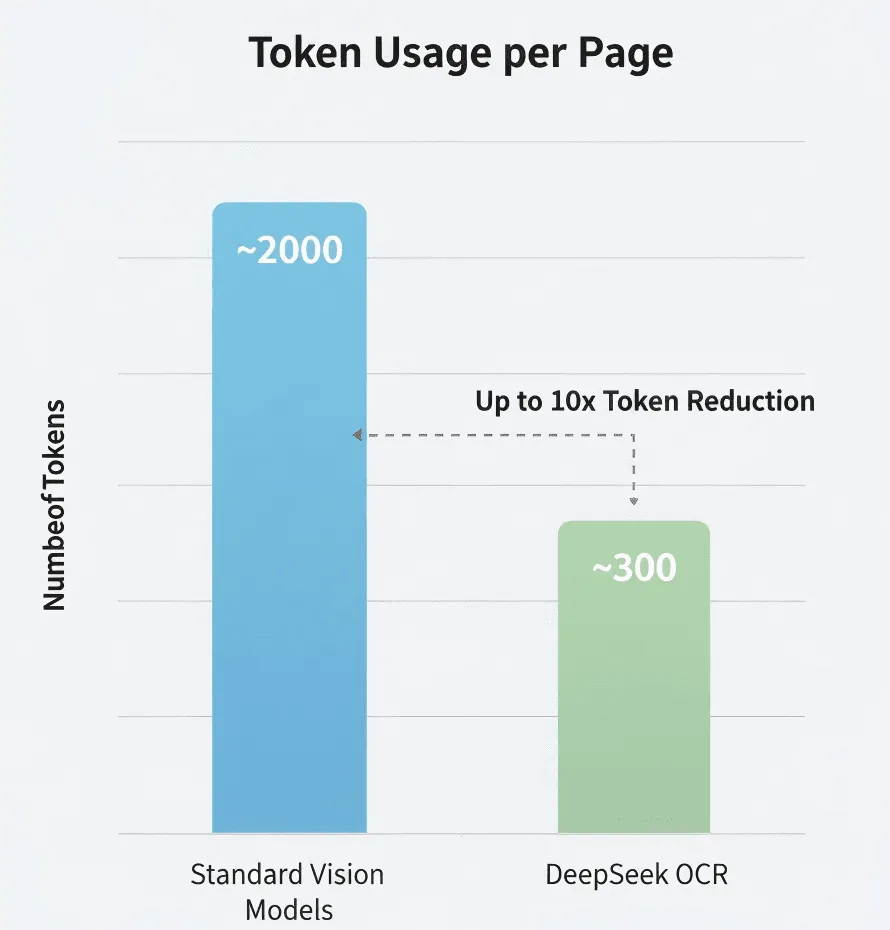
- Modèle visuel standard : ~2 000 jetons/page
- DeepSeek OCR : ~300–400 jetons/page
- Compression effective : 5–8×
Je n'ai pas vérifié ces chiffres moi-même, mais s'ils sont même proches de la réalité, c'est significatif.
Vue d'ensemble de l'architecture
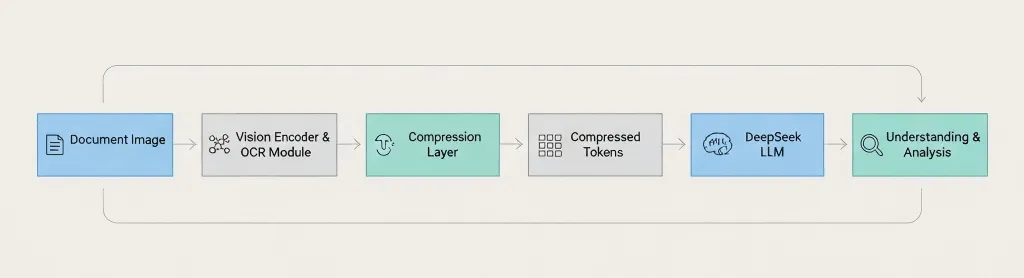
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis The key difference: DeepSeek compresses before passing to the language model, not after. 3. Comment cela fonctionne vraiment
Le pipeline se déroule ainsi :
Étape 1 : Traitement de l'image
Prétraitement standard : amélioration de la résolution, réduction du bruit, correction de l'orientation, détection de la mise en page.
Étape 2 : Reconnaissance du texte
Extraction des caractères, paragraphes, tableaux, en-têtes/pieds de page, et indices de mise en forme.
Étape 3 : Compression du contexte
Regroupe de façon sémantique les textes liés, retire les jetons redondants, encode efficacement la structure et préserve les informations de mise en page.
Étape 4 : Intégration avec les LLM
Passe les représentations compressées dans le modèle DeepSeek pour du question-réponse, du résumé, de l'extraction d'information et la comparaison de documents.
Langues prises en charge
L'anglais, le chinois et les principales langues européennes sont probablement supportées. Mais je vous conseille de tester avec votre langue précise avant de vous engager.
Écriture manuscrite ?
Non confirmé. L'article de blog se concentre sur le texte imprimé. Si vous avez besoin d'un OCR manuscrit, Google Vision ou Azure sont probablement des choix plus sûrs.
4. Ce que vous pouvez en faire
Types de documents pris en charge
- PDF (natif & numérisé)
- Images : PNG, JPEG, TIFF
- Documents multipages
- Mises en page complexes
Fonctionnalités
- Extraction de texte haute précision
- Maintien de la structure et de la mise en forme
- Préservation des tableaux et des paragraphes
- Analyse contextuelle via LLM
Vous pouvez demander par exemple :
- "Résume la section 3"
- "Liste tous les noms et dates au format JSON"
- "Compare cette version avec la précédente"
- "Mets en évidence toutes les déclarations de risque"
Ce que cela ne peut probablement pas gérer
- Mauvaise qualité d'image ou polices artistiques
- Mises en page multilingues (testez d'abord)
- Équations mathématiques
- Schémas ou graphiques (seulement les étiquettes textuelles)
5. Premiers pas
Important : L'API de DeepSeek est compatible OpenAI, mais vérifiez leur documentation pour les noms exacts des modèles et les paramètres.
Rappel sécurité : Vérifiez toujours la conformité (RGPD, HIPAA) avant d'envoyer des documents sensibles à des APIs tierces.
Ce dont vous aurez besoin
- Une clé API DeepSeek (inscription sur deepseek.com)
- Python 3.8+ ou Node.js 14+
- Notions de base sur l'utilisation d'une API
Installation pour les développeurs
pip install openai pillowExemple 1 : Extraction simple de texte
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Exemple 2 : Poser des questions sur un document
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Exemple 3 : Extraire les tableaux au format JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentExemple 4 : Améliorer d'abord la qualité de l'image
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Conseils pour de meilleurs résultats
Soyez précis dans vos consignes. Au lieu de "extraire les informations", dites "extraire le numéro de facture, la date et le montant total".
Utilisez des scans haute résolution. 300 DPI minimum. Bonne luminosité. Pas d'ombres.
Validez toujours les données critiques. Ne faites pas confiance aveuglément à l'OCR pour les montants financiers, les dates ou les mentions juridiques.
Suivez votre utilisation. Surveillez les jetons, la latence et les taux d’erreur afin d’optimiser votre utilisation.
6. Performance en situation réelle
Je n’ai pas réalisé de tests complets moi-même, donc prenez cela avec une certaine réserve.
Compression de jetons
DeepSeek annonce 5 à 10 fois moins de jetons que les modèles standards. Si c’est exact, cela représente une réduction majeure des coûts pour des traitements à gros volume.
Précision
Comparable aux principaux moteurs OCR sur du texte propre. La précision baisse sur des numérisations de mauvaise qualité, des polices inhabituelles ou des documents dégradés.
Vitesse
Environ 1 à 3 secondes par page selon mes essais limités. Les résultats varieront selon la longueur du document, la qualité des images et la charge serveur.
Efficacité des coûts
Si vous payez au jeton (comme la plupart des API LLM), utiliser 5 à 10 fois moins de jetons se traduit par des économies notables. Mais vérifiez tout de même les tarifs réels de DeepSeek, je n’ai pas l’information à jour.
7. Quand utiliser ceci plutôt que l’OCR traditionnel ?
Utilisez DeepSeek OCR lorsque :
- Vous traitez de longs documents (20 pages ou plus)
- Vous avez besoin de compréhension par l’IA, pas seulement d’extraction de texte
- Le coût est un enjeu (traitement à gros volume)
- Vous recherchez la simplicité (pas de logique d’extraction par bloc)
Utilisez l’OCR traditionnel lorsque :
- Vous avez simplement besoin d’extraire du texte (pas d’analyse IA)
- La confidentialité est primordiale (impossible d’envoyer à des API externes) → utilisez Tesseract
- Vous avez besoin de fonctionnalités spécialisées (écriture manuscrite, formulaires) → Google Vision ou AWS Textract
- Le budget est nul → utilisez Tesseract (gratuit, open source)
Comparaison rapide
Besoins | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Documents longs (50 pages ou plus) | Excellente | Fonctionne (pas d’IA) | Nécessite un découpage | Nécessite un découpage |
Compréhension IA | Intégrée | Aucune | Service séparé | Service séparé |
Coût (gros volume) | Efficient | Gratuit | Peut être onéreux | Peut être onéreux |
Confidentialité / local | Cloud uniquement | Auto-hébergé | Cloud uniquement | Cloud uniquement |
Écriture manuscrite | Inconnu | Limité | Bon | Bon |
Tableaux | Bon | Basique | Bon | Excellent |
8. Cas pratiques
Analyse de documents juridiques
Traitez des contrats entiers en une seule fois. Posez des questions comme « Quels sont les clauses de résiliation ? » ou « Identifiez les risques potentiels. » L’IA analyse l’intégralité du contrat, en respectant le contexte global.
Analyse d’articles de recherche
Extrayez les résultats majeurs de plusieurs articles, comparez les méthodologies, générez des synthèses de revue de la littérature. Cela ne remplace pas la lecture des articles, mais accélère le filtrage initial.
Traitement de rapports financiers
Extrayez automatiquement tous les tableaux financiers, convertissez-les en données structurées, identifiez les tendances entre périodes. Pensez toujours à vérifier les données extraites et ne vous reposez pas uniquement sur l’IA pour les chiffres critiques.
Projets de numérisation de documents
Traitez par lots des documents historiques, générez du texte indexable, extrayez automatiquement les métadonnées. Cela reste chronophage, mais la compression contextuelle améliore l’efficacité.
Traitement de factures et reçus
Extrayez automatiquement des données structurées à partir de factures (nom du fournisseur, numéro de facture, date, lignes, totaux) et intégrez-les dans les systèmes comptables. En très gros volumes, AWS Textract reste plus spécialisé.
Ce qui ne fonctionnera probablement pas bien
Dossiers médicaux - problèmes de conformité HIPAA, exigences de précision, enjeux juridiques.
Documents historiques - texte effacé, polices inhabituelles, pages endommagées nécessitent souvent un OCR spécialisé.
Notes manuscrites - même si la prise en charge existe, ce n’est probablement pas la fonctionnalité la plus robuste.
Traitement en temps réel - si vous avez besoin d’une réponse en moins d’une seconde, OCR + LLM risque d’être trop lent.
9. Conseils et bonnes pratiques
La qualité de l'image compte
Pour les documents physiques :
- Numérisez à 300 DPI minimum
- Utilisez un scanner à plat si possible
- Assurez un éclairage homogène (pas d'ombres ni de reflets)
- Aplatissez complètement les pages
Pour les photos mobiles :
- Utilisez un bon éclairage (la lumière naturelle est la meilleure)
- Tenez l'appareil stable
- Capturez de face (évitez les angles)
- Prenez plusieurs clichés si vous n'êtes pas sûr
Soyez précis dans vos requêtes
Vague : « Extraire des informations de ce document. »
Mieux : « Extraire tout le texte de cette facture, en préservant la structure du tableau. »
Optimal : « Extraire les données de la facture dans ce format JSON exact : {...}. Si un champ n'est pas trouvé, utilisez null. »
Validez toujours les données critiques
Ne faites jamais confiance aux résultats de l'OCR à l'aveugle pour :
- Les montants financiers
- Les dates
- Les noms
- Les termes juridiques
- Les informations médicales
Prévoyez une vérification humaine pour les documents importants.
Testez avec de vrais documents
Ne vous contentez pas de tester avec des PDF parfaits. Testez avec :
- Des documents numérisés
- Des photos prises avec des téléphones
- Des images de mauvaise qualité
- Des documents tachés de café
- Des pages froissées
Vos données en production ne seront pas parfaites. Vos tests ne devraient pas l'être non plus.
Ayez des attentes réalistes
L'OCR n'est pas parfait. Même avec l'IA :
- Attendez-vous à une précision de 95-99 % sur des documents propres
- Attendez-vous à 85-95 % sur des documents de mauvaise qualité
- Prévoyez une validation humaine pour les données critiques
- Prévoyez du temps pour la gestion des erreurs
Prévoyez un plan de secours
Les API peuvent échouer. Les réseaux peuvent tomber. Les services peuvent changer. Prévoyez une solution de repli :
- Stockez les résultats en cache si possible
- Implémentez une logique de reprise automatique
- Envisagez un service OCR de secours
- Conservez des sauvegardes des documents critiques
10. Limitations à connaître
Les fenêtres de contexte ont toujours des limites
La compression aide, mais vous ne pouvez pas traiter une infinité de documents. Les livres de 500 pages nécessitent toujours un traitement par lots.
La précision n'est pas parfaite
Aucun système OCR n'est 100 % précis. Attendez-vous à des erreurs avec des polices inhabituelles, une qualité d'image médiocre, des mises en page complexes, des langues mélangées et du texte manuscrit.
Ce n'est pas de la magie
L'IA peut extraire et comprendre du texte, mais elle ne peut pas lire du texte réellement illisible, comprendre un contexte sur lequel elle n'a pas été entraînée ou réparer des problèmes fondamentaux de qualité d'image.
Questions de coût
Bien que la compression de tokens réduise les coûts, vous payez toujours pour les appels API, l'utilisation de tokens et le temps de traitement. Pour des volumes très élevés, les coûts peuvent s'accumuler.
Confidentialité et conformité
L'envoi de documents à des API externes signifie que les données quittent votre infrastructure et sont soumises aux conditions d'utilisation du fournisseur. Cela peut ne pas répondre à certaines exigences de conformité (HIPAA, RGPD, etc.).
Examinez attentivement la politique de confidentialité et les certifications de conformité de DeepSeek.
Dépendance à l'API
Vous dépendez de la disponibilité de l'API DeepSeek, des limites de débit, des évolutions tarifaires et de la continuité du service. Prévoyez un plan de secours.
Support linguistique inconnu
DeepSeek n'a pas publié de détails complets sur le support linguistique. Si vous avez besoin d'OCR pour des langues peu courantes, des écritures de droite à gauche ou complexes (Devanagari, thaï, etc.), testez soigneusement.
Aucune option hors ligne
Contrairement à Tesseract, vous ne pouvez pas faire fonctionner DeepSeek OCR hors ligne. Vous avez besoin d'une connexion internet, d'un accès à l'API et d'une latence acceptable.
11. Questions fréquentes
Combien coûte DeepSeek OCR ?
Je n'ai pas les tarifs actuels. Consultez le site web de DeepSeek pour connaître leurs tarifs les plus récents. Il est probable que ce soit basé sur les tokens, comme d'autres API LLM.
Puis-je l'utiliser gratuitement ?
DeepSeek peut proposer une offre gratuite ou une période d'essai. Consultez leur site web.
Comment cela se compare-t-il à Google Vision ?
Cas d'utilisation différents. DeepSeek OCR est meilleur pour les longs documents nécessitant une compréhension par l'IA. Google Vision est meilleur pour l'écriture manuscrite et l'analyse d'image au-delà du texte.
La compression de contexte est-elle avec perte ? Perd-elle des informations ?
Pensez-y comme à une compression intelligente avec perte. Elle préserve la sémantique principale, la structure et les informations clés, mais peut supprimer des détails visuels redondants ou des indices de mise en forme non essentiels à la compréhension. Le but n'est pas la reconstruction fidèle au pixel près ; il s'agit de permettre à un LLM de comprendre efficacement et précisément le document.
En quoi cela diffère-t-il de la compression ZIP ?
Totalement différent. ZIP est une compression de fichiers sans perte ; elle réduit la taille du stockage. Quand vous décompressez, vous obtenez une copie identique. Mais un LLM a toujours besoin de traiter tout le texte non compressé, consommant beaucoup de tokens.
La compression de contexte de DeepSeek est une compression sémantique. Elle réduit les tokens envoyés au LLM pour l'analyse, diminuant les coûts de calcul de l'IA et permettant de rentrer dans les fenêtres de contexte.
Dois-je obligatoirement utiliser le LLM de DeepSeek ?
Oui. La compression de contexte est profondément intégrée aux modèles linguistiques DeepSeek. Le format de token compressé est propriétaire et spécialement conçu pour leurs modèles. Vous ne pouvez pas utiliser ces tokens compressés avec GPT-4 ou Claude.
La compression est-elle toujours efficace pour des images simples contenant uniquement du texte ?
Moins spectaculaire. La technologie donne de meilleurs résultats sur des documents à mise en page complexe, mélange de texte et d'images, ou beaucoup d'espace blanc. Pour un simple mur de texte, le comptage de tokens peut être similaire à celui d'un OCR traditionnel, mais vous bénéficiez tout de même de l'appel API simplifié et tout-en-un.
Quel temps et coût estimés pour traiter un PDF de 100 pages ?
Temps : quelques secondes par page en moyenne, selon les données publiques.
Coût : si un Vision-LLM traditionnel a besoin de 2 000 tokens par page contre 300 pour DeepSeek OCR, le coût total en tokens pour un document de 100 pages pourrait n'être que 15 % de la méthode traditionnelle. Mais vérifiez la tarification officielle DeepSeek pour des chiffres exacts.
Peut-il comprendre des graphiques, des diagrammes ou des schémas ?
Il excelle dans l'extraction des éléments textuels (titres, axes, légendes). Mais il ne peut pas interpréter la logique visuelle du graphique comme « Quelle barre est la plus haute ? » ou « Quelle est l'étape suivante de ce diagramme ? ». Des modèles multimodaux plus avancés sont plus adaptés à ces tâches.
Que se passe-t-il si la qualité de mon document est mauvaise ?
Comme tout OCR, la qualité d'entrée affecte directement la qualité de sortie. DeepSeek OCR intègre un prétraitement d'image pour traiter certains bruits, mais les artefacts graves, le flou ou la basse résolution réduiront fortement la précision. Utilisez toujours des scans de haute qualité, au moins 300 DPI.
Conclusion
La compression de contexte de DeepSeek OCR n'est pas tape-à-l'œil ; elle est pragmatique.
Elle réduit les coûts, simplifie l'architecture, et rend enfin réaliste l'analyse de longs documents de bout en bout avec un LLM.
Elle ne remplacera pas tous les outils OCR. Tesseract et Google Vision restent les meilleurs pour la confidentialité ou l'écriture manuscrite. Mais pour une compréhension de documents à grande échelle assistée par l'IA, l'approche DeepSeek marque un vrai progrès.
Essayez-la avec votre document le plus long. Si cela passe en une seule fois et donne des réponses cohérentes, vous verrez la différence instantanément.
Ressources :
- Article de blog DeepSeek OCR
- The Decoder : la compression OCR de DeepSeek
- Documentation API DeepSeek (site officiel)
Avertissement : Cet article se base sur des données publiques et des tests personnels limités. Confirmez toujours les informations via la documentation officielle avant tout usage en production.