DeepSeek OCR: Guida pratica alla loro tecnologia di compressione del contesto (2025)
Ultimo aggiornamento: 2026-01-22 18:05:30

Ultimo aggiornamento: 22 ottobre 2025
Se hai seguito gli sviluppi dell'AI recentemente, probabilmente hai sentito parlare del nuovo sistema OCR di DeepSeek. Quello che ha attirato la mia attenzione non è stato soltanto l’ennesimo "possiamo leggere testo dalle immagini", ma come abbiano affrontato un vero limite costoso: elaborare documenti lunghi senza sforare il tuo budget di token.
Questa guida spiega cosa fa DeepSeek OCR di diverso, come funziona e se vale la pena utilizzarlo nei tuoi progetti.
Indice
- Cosa rende DeepSeek OCR diverso?(#what-makes-it-different)
- La svolta della compressione del contesto(#context-compression)
- Come funziona concretamente(#how-it-works)
- Cosa puoi farci(#capabilities)
- Come iniziare(#getting-started)
- Prestazioni nel mondo reale(#performance)
- Quando dovresti usare questo rispetto all’OCR tradizionale?(#comparison)
- Applicazioni pratiche(#applications)
- Suggerimenti e best practice(#tips)
- Limitazioni che dovresti conoscere(#limitations)
- Domande frequenti(#faq)
1. Cosa rende DeepSeek OCR diverso?
L’OCR in sé non è una novità strumenti come Tesseract, Google Vision e AWS Textract esistono da anni. Tutti estraggono il testo senza problemi.
Il vero collo di bottiglia si presenta quando hai bisogno che un modello AI comprenda il documento, non solo lo trascriva.
Il problema dei token
Fornire l’output OCR grezzo a un grande modello linguistico è inefficiente.
Immagina un contratto di 50 pagine:
- Estrarrai il testo
- Proverai a inviarlo a un LLM
- Supererai il limite di contesto dopo tre pagine
- Inizierai a suddividere, riassumere e perdere contesto
È frustrante, e ho perso ore su questo problema preciso.
La soluzione di DeepSeek
DeepSeek non tratta OCR e comprensione come passaggi separati. Il loro sistema esegue OCR e compressione semantica contemporaneamente.
Anziché riversare il testo grezzo, DeepSeek OCR codifica significato e layout in una forma compatta riducendo l’uso di token di 5–10×.
Un contratto di 50 pagine che richiedeva 100k token ora può rientrare in 12k–15k.
Perché questo è importante:
- Costi ridotti (meno token = inferenza più economica)
- Flusso di lavoro più semplice (niente suddivisione manuale)
- Miglior contesto (il modello vede l'intero documento)
- Elaborazione più veloce (una chiamata API invece di decine)
2. La svolta della compressione del contesto
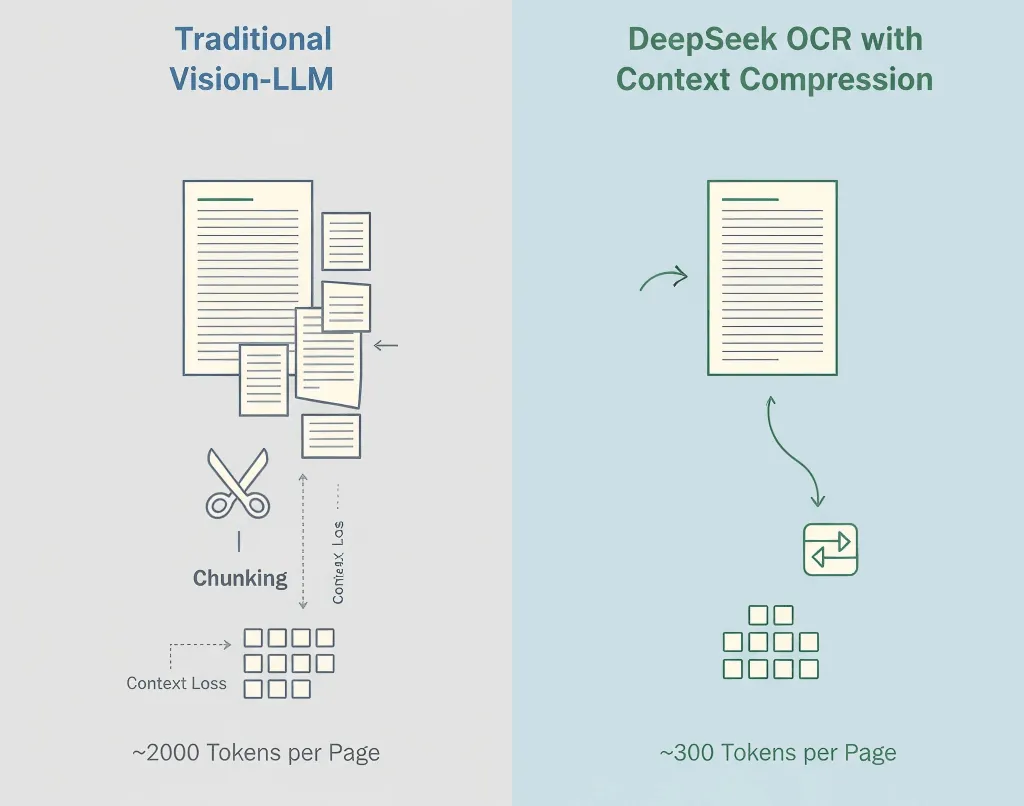
I modelli visione-linguaggio tradizionali trasformano ogni parte di un’immagine in token, spesso 1.500–2.500 per pagina. La maggior parte di questi token rappresentano pixel, non significato.
Il metodo di DeepSeek
- Prima l’OCR - Estrae testo, layout e tabelle
- Compressione semantica - Converte il contenuto riconosciuto in token linguistici efficienti
- Conservazione della struttura - Mantiene gerarchia, formattazione e indicatori visivi
- Compressione adattiva - Si adatta in base alla complessità del documento
I numeri
Secondo le ricerche di DeepSeek:
- Modello visione standard: ~2.000 token/pagina
- DeepSeek OCR: ~300–400 token/pagina
- Compressione effettiva: 5–8×
Non l’ho verificato in modo indipendente, ma anche solo fossero vicini, è significativo.
Panoramica dell’architettura
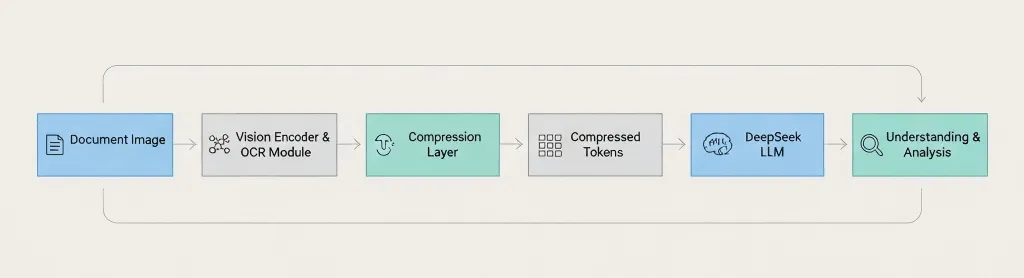
Document Image → Vision Encoder → OCR Module → Compression Layer → Compressed Tokens → DeepSeek LLM → Understanding & Analysis La differenza chiave: DeepSeek comprime prima di passare al modello linguistico, non dopo. 3. Come funziona concretamente
La pipeline è suddivisa così:
Fase 1: Elaborazione immagine
Preprocessing standard miglioramento della risoluzione, riduzione del rumore, correzione dell’orientamento e rilevamento del layout.
Fase 2: Riconoscimento testo
Estrae caratteri, paragrafi, tabelle, intestazioni/pie’ di pagina e indicatori di formattazione.
Fase 3: Compressione del contesto
Raggruppa semanticamente i testi correlati, rimuove i token ridondanti, codifica la struttura in modo efficiente e preserva le informazioni di layout.
Fase 4: Integrazione con LLM
Invia le rappresentazioni compresse al modello di DeepSeek per Q&A, riassunti, estrazione informazioni e confronto documenti.
Copertura linguistica
È probabile che supporti inglese, cinese e le principali lingue europee. Ma proverei con la tua lingua specifica prima di impegnarti.
Scrittura manuale?
Non confermato. Il post sul blog si concentra su testo stampato. Se ti serve OCR di scrittura a mano, Google Vision o Azure sono probabilmente opzioni più sicure.
4. Cosa puoi farci
Tipi di documenti supportati
- PDF (nativi & scannerizzati)
- Immagini: PNG, JPEG, TIFF
- Documenti multipagina
- Layout complessi
Funzionalità
- Estrazione testo ad alta precisione
- Mantiene struttura e formattazione
- Salvataggio di tabelle e paragrafi
- Analisi contestuale tramite LLM
Puoi chiedere cose come:
- "Riassumi la sezione 3"
- "Elenca tutti i nomi e le date come JSON"
- "Confronta questa versione con la precedente"
- "Evidenzia tutte le dichiarazioni di rischio"
Probabilmente non gestisce bene
- Bassa qualità d’immagine o font artistici
- Layout a lingue miste (provare prima)
- Equazioni matematiche
- Diagrammi o grafici (solo etichette testuali)
5. Come iniziare
Importante: L’API di DeepSeek è compatibile con OpenAI, ma controlla la documentazione per i nomi del modello e i parametri esatti.
Promemoria sulla sicurezza: Verifica sempre la conformità (GDPR, HIPAA) prima di caricare documenti sensibili su API di terze parti.
Cosa ti serve
- Una chiave API DeepSeek (registrati su deepseek.com)
- Python 3.8+ o Node.js 14+
- Familiarità di base con le chiamate API
Configurazione per sviluppatori
pip install openai pillowEsempio 1: Estrazione semplice del testo
import os, base64from openai import OpenAIclient = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com")def extract_text(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Extract all text from this image, keep original structure."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.content# Use ittext = extract_text("my_document.jpg")print(text)Esempio 2: Fai domande su un documento
def ask_doc(image_path, question): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": f"Analyze this document and answer: {question}"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, temperature=0.1, max_tokens=2000 ) return r.choices0.message.content# Ask multiple questionsanswer = ask_doc("contract.jpg", "What are the payment terms?")print(answer)Esempio 3: Estrai tabelle come JSON
def extract_tables(image_path): with open(image_path, "rb") as f: img = base64.b64encode(f.read()).decode("utf-8") r = client.chat.completions.create( model="deepseek-chat", messages={ "role": "user", "content": {"type": "text", "text": "Find all tables and output as JSON."}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img}"}} }, max_tokens=4000 ) return r.choices0.message.contentEsempio 4: Migliora prima la qualità dell’immagine
from PIL import Image, ImageEnhancedef enhance_image(path): img = Image.open(path).convert('RGB') img = ImageEnhance.Contrast(img).enhance(1.2) img = ImageEnhance.Sharpness(img).enhance(1.5) out = "enhanced_" + path img.save(out, quality=95) return out# Use before OCRimproved = enhance_image("blurry_scan.jpg")text = extract_text(improved)Suggerimenti per risultati migliori
Sii specifico nei prompt. Invece di "estrai informazioni", chiedi "estrae il numero fattura, la data e l’importo totale."
Usa scansioni ad alta risoluzione. Almeno 300 DPI. Buona illuminazione. Nessuna ombra.
Verifica sempre i dati critici. Non fidarti ciecamente dell’OCR per importi, date o clausole legali.
Monitora il tuo utilizzo. Tieni traccia dei token, della latenza e dei tassi di errore così puoi ottimizzare.
6. Prestazioni nel Mondo Reale
Non ho eseguito benchmark esaustivi personalmente, quindi prendi queste informazioni con il giusto scetticismo.
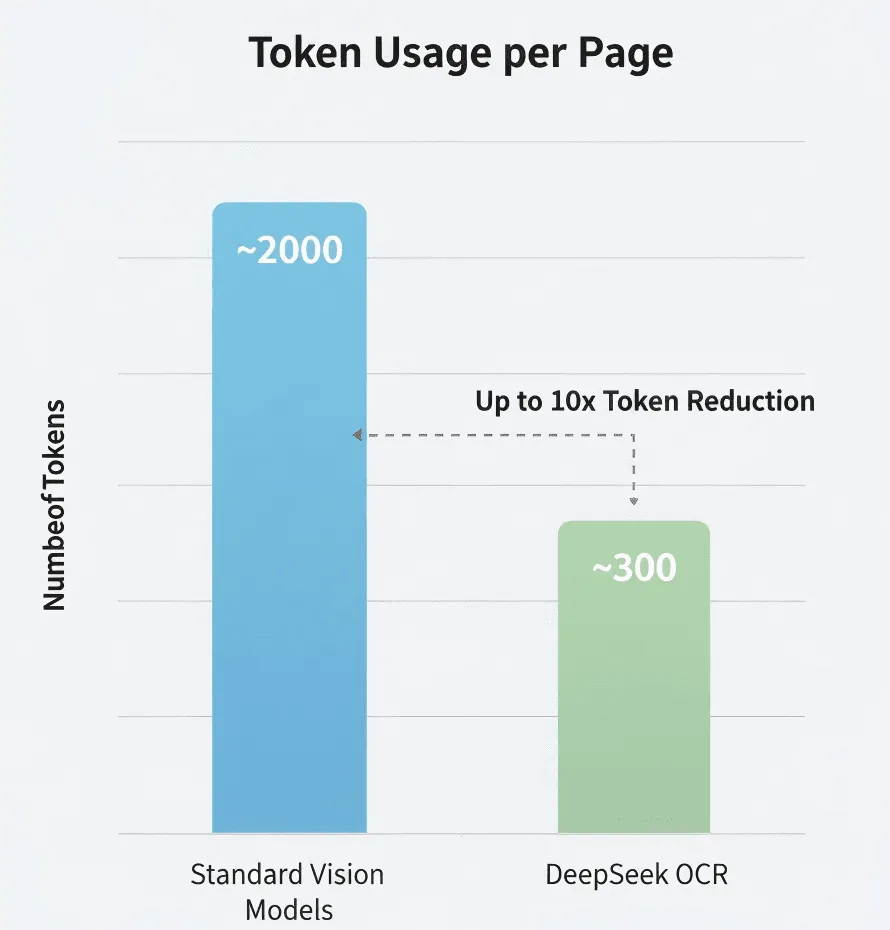
Compressione dei Token
DeepSeek dichiara 5–10× meno token rispetto ai modelli standard. Se vero, sarebbe una riduzione significativa dei costi per elaborazioni ad alto volume.
Accuratezza
Paragonabile ai principali motori OCR su testo pulito. L’accuratezza diminuisce su scansioni di bassa qualità, caratteri insoliti o documenti danneggiati.
Velocità
Circa 1–3 secondi per pagina nei miei test limitati. I risultati variano in base alla lunghezza del documento, la qualità delle immagini e il carico del server.
Efficienza dei Costi
Se paghi per token (come la maggior parte delle API LLM), utilizzare 5–10× meno token significa risparmi significativi. Ma verifica i prezzi effettivi di DeepSeek, non ho informazioni aggiornate sulle tariffe.
7. Quando Dovresti Usare Questo rispetto all’OCR Tradizionale?
Usa DeepSeek OCR quando:
- Stai elaborando documenti lunghi (più di 20 pagine)
- Hai bisogno della comprensione AI, non solo dell’estrazione di testo
- Il costo è una preoccupazione (elaborazioni ad alto volume)
- Vuoi semplicità (nessuna logica di suddivisione)
Usa OCR Tradizionale quando:
- Hai solo bisogno di estrazione di testo (nessuna analisi AI)
- La privacy è fondamentale (non puoi inviare a API esterne) → usa Tesseract
- Servono funzionalità specifiche (manoscritti, moduli) → Google Vision o AWS Textract
- Il budget è zero → usa Tesseract (gratuito, open source)
Confronto Rapido
Esigenza | DeepSeek OCR | Tesseract | Google Vision | AWS Textract |
Documenti lunghi (più di 50 pagine) | Eccellente | Funziona (no AI) | Richiede suddivisione | Richiede suddivisione |
Comprensione AI | Integrata | Nessuna | Servizio separato | Servizio separato |
Costo (alto volume) | Efficiente | Gratuito | Può essere costoso | Può essere costoso |
Privacy/on-premise | Solo cloud | Self-hosted | Solo cloud | Solo cloud |
Scrittura manuale | Sconosciuto | Limitato | Buono | Buono |
Tabelle | Buono | Base | Buono | Eccellente |
8. Applicazioni Pratiche
Analisi di Documenti Legali
Elabora interi contratti in una sola volta. Fai domande come "Quali sono le clausole di risoluzione?" o "Identifica i rischi potenziali." L’AI vede l’intero contratto, mantenendo il contesto tra le sezioni.
Revisione di Articoli Scientifici
Estrai i risultati chiave da più articoli, confronta le metodologie, genera riassunti per revisione della letteratura. Questo non sostituirà la lettura degli articoli, ma accelera lo screening iniziale.
Elaborazione di Bilanci Finanziari
Estrai tutte le tabelle finanziarie automaticamente, converti in dati strutturati, identifica trend tra diversi periodi di rendicontazione. Verifica sempre i dati finanziari estratti e non affidarti solo all’AI per numeri critici.
Progetti di Digitalizzazione Documentale
Elabora in batch documenti storici, genera testo ricercabile, estrai i metadati automaticamente. Richiede comunque tempo, ma la compressione del contesto lo rende più efficiente.
Elaborazione di Fatture e Scontrini
Estrai automaticamente dati strutturati dalle fatture (nome del fornitore, numero fattura, data, voci, totali) e importa nei sistemi di contabilità. Per volumi molto alti, AWS Textract potrebbe essere ancora più specializzato.
Casi In Cui Probabilmente Funziona Meno Bene
Cartelle cliniche - Preoccupazioni sulla conformità HIPAA, requisiti di accuratezza, questioni di responsabilità.
Documenti storici - Testo sbiadito, caratteri insoliti, pagine danneggiate potrebbero richiedere OCR specializzato.
Appunti manoscritti - Se il supporto alla scrittura a mano esiste, probabilmente non è la caratteristica principale.
Elaborazione in tempo reale - Se hai bisogno di tempi di risposta sotto il secondo, OCR + LLM potrebbe essere troppo lento.
9. Suggerimenti e Best Practice
La qualità delle immagini è importante
Per i documenti cartacei:
- Scansiona ad almeno 300 DPI
- Usa uno scanner piano quando possibile
- Assicurati di avere una luce uniforme (niente ombre o riflessi)
- Appiattisci completamente le pagine
Per foto da cellulare:
- Usa una buona illuminazione (la luce naturale è la migliore)
- Tieni il dispositivo fermo
- Scatta frontalmente (evita gli angoli)
- Fai più foto se non sei sicuro
Sii specifico nei tuoi prompt
Vago: "Estrai informazioni da questo documento."
Meglio: "Estrai tutto il testo da questa fattura, mantenendo la struttura della tabella."
Ottimale: "Estrai i dati della fattura in questo preciso formato JSON: {...}. Se un campo non viene trovato, usa null."
Valida sempre i dati critici
Non fidarti mai ciecamente dell'output OCR per:
- Importi finanziari
- Date
- Nomi
- Termini legali
- Informazioni mediche
Prevedi sempre una revisione umana per i documenti importanti.
Testa con documenti reali
Non testare solo con PDF perfetti. Prova con:
- Documenti scansionati
- Foto scattate con telefoni
- Immagini di bassa qualità
- Documenti con macchie di caffè
- Pagine stropicciate
I tuoi dati in produzione non saranno perfetti. I tuoi test non dovrebbero esserlo nemmeno.
Imposta aspettative realistiche
L'OCR non è perfetto. Anche con l'AI:
- Prevedi un'accuratezza del 95-99% su documenti puliti
- Prevedi 85-95% su qualità scarsa
- Prevedi la necessità di una revisione umana per i dati critici
- Prevedi tempo per la gestione degli errori
Prevedi un piano di riserva
Le API falliscono. Le reti cadono. I servizi cambiano. Prevedi una soluzione di emergenza:
- Memorizza nella cache i risultati quando possibile
- Implementa la logica di ritentativo
- Considera un servizio OCR alternativo
- Tieni una copia di backup dei documenti critici
10. Limitazioni che dovresti conoscere
I contesti hanno ancora limiti
La compressione aiuta, ma non puoi processare documenti infiniti. Libri da 500 pagine richiedono ancora suddivisione in batch.
L'accuratezza non è perfetta
Nessun sistema OCR è preciso al 100%. Prevedi errori con font insoliti, bassa qualità delle immagini, layout complessi, lingue miste e testo scritto a mano.
Non è magia
L'AI può estrarre e comprendere testo, ma non può leggere testo realmente illeggibile, capire contesti per cui non è stata addestrata o correggere problemi fondamentali di qualità dell’immagine.
Considerazioni sui costi
Sebbene la compressione dei token riduca i costi, paghi comunque per le chiamate API, l'utilizzo dei token e il tempo di elaborazione. Con volumi estremamente elevati, i costi possono aumentare.
Privacy e conformità
Inviare documenti a API esterne significa che i dati escono dalla tua infrastruttura e sono soggetti ai termini di servizio del provider. Potrebbe non essere conforme a determinati standard (HIPAA, GDPR, ecc.).
Verifica attentamente la privacy policy e le certificazioni di conformità di DeepSeek.
Dipendenza dall'API
Dipendi dalla disponibilità dell'API di DeepSeek, dai limiti di velocità, dalle variazioni di prezzo e dalla continuità del servizio. Prevedi un piano di riserva.
Supporto linguistico sconosciuto
DeepSeek non ha pubblicato dettagli completi sul supporto linguistico. Se hai bisogno di OCR per lingue meno comuni, scritture da destra a sinistra o scritture complesse (Devanagari, Thai, ecc.), testa attentamente.
Nessuna opzione offline
A differenza di Tesseract, non puoi eseguire DeepSeek OCR offline. Serve connessione internet, accesso all'API e una latenza accettabile.
11. Domande comuni
Quanto costa DeepSeek OCR?
Non ho prezzi aggiornati. Verifica il sito di DeepSeek per le tariffe più recenti. È probabilmente basato sui token, come altre API LLM.
Posso usarlo gratis?
DeepSeek potrebbe offrire un piano gratuito o una prova. Verifica sul loro sito.
Come si confronta con Google Vision?
Casi d'uso diversi. DeepSeek OCR è migliore per documenti lunghi che richiedono comprensione AI. Google Vision è migliore per la scrittura a mano e l’analisi di immagini oltre il testo.
La compressione del contesto è lossy? Si perde informazione?
Pensala come una compressione intelligente lossy. Conserva la semantica principale, la struttura e le informazioni chiave, ma può eliminare dettagli visivi ridondanti o elementi di formattazione non fondamentali per la comprensione. L'obiettivo non è la ricostruzione perfetta dei pixel, ma permettere all'LLM di comprendere il documento in modo efficiente e accurato.
In cosa è diversa dalla compressione ZIP?
Totalmente diversa. ZIP è una compressione lossless che riduce la dimensione di archiviazione. Quando estrai, ottieni una copia identica. Ma un LLM deve comunque processare tutto il testo non compresso, consumando molti token.
La compressione contestuale di DeepSeek è una compressione semantica. Riduce i token inviati all'LLM per l'analisi, abbassando i costi di calcolo AI e rispettando i limiti di contesto.
Devo usare per forza il LLM di DeepSeek?
Sì. La compressione contestuale è profondamente integrata con i modelli linguistici di DeepSeek. Il formato dei token compressi è proprietario e specificatamente creato per i modelli DeepSeek. Non puoi usare questi token compressi con GPT-4 o Claude.
La compressione è comunque efficace con immagini semplici e solo testo?
Meno marcato. La tecnologia dà il meglio con documenti complessi che mescolano testo e immagini e tanto spazio bianco. Per pagine di solo testo, il numero di token potrebbe essere simile all'OCR tradizionale, ma hai comunque il vantaggio della chiamata API integrata e semplificata.
Quali sono tempi e costi stimati per elaborare un PDF di 100 pagine?
Tempo: in media pochi secondi a pagina, secondo dati pubblici.
Costo: se un Vision-LLM tradizionale richiede 2.000 token a pagina contro i 300 di DeepSeek OCR, il costo totale dei token per 100 pagine potrebbe essere solo il 15% del metodo tradizionale. Controlla comunque i prezzi ufficiali DeepSeek per dati precisi.
Può capire grafici, tabelle o diagrammi?
Dà il meglio nell'estrazione delle componenti testuali (titoli, etichette degli assi, legende). Ma non interpreta la logica visiva del grafico, tipo "Quale barra è la più alta?" o "Qual è il prossimo passo in questo diagramma di flusso?" Modelli multimodali più avanzati sono più adatti a questi compiti.
Cosa succede se la qualità del mio documento è scarsa?
Come per ogni OCR, la qualità in ingresso incide direttamente su quella in uscita. Sebbene DeepSeek OCR includa pre-elaborazione delle immagini per gestire un po' di rumore, artefatti gravi, sfocatura o bassa risoluzione riducono molto l'accuratezza. Usa sempre scansioni di alta qualità a 300 DPI o più.
Considerazioni finali
La compressione contestuale di DeepSeek OCR non è appariscente, è pratica.
Riduce i costi, semplifica l'architettura e rende finalmente realistico analizzare documenti lunghi da un capo all'altro con un LLM.
Non sostituirà ogni strumento OCR. Tesseract e Google Vision restano eccellenti per casi sensibili alla privacy o per la scrittura a mano. Ma per una comprensione scalabile e assistita dall'intelligenza artificiale dei documenti, l’approccio DeepSeek rappresenta un vero passo avanti.
Provalo con il tuo documento più lungo. Se si adatta a una sola elaborazione e ottieni risposte coerenti, noterai subito la differenza.
Risorse:
- DeepSeek OCR Blog Post
- The Decoder: DeepSeek's OCR Compression
- DeepSeek API Docs (sito ufficiale)
Nota: Questo articolo si basa su dati pubblici e test personali limitati. Verifica sempre i dettagli tramite la documentazione ufficiale prima di usare in produzione.