Die komplette Geschichte der KI-Kunst: Von AARON bis Midjourney (1973–2025)
Zuletzt aktualisiert: 2026-01-22 18:07:34

Wie sich künstliche Intelligenz von einer akademischen Spielerei zur künstlerischen Revolution entwickelt hat – und warum das heute relevant ist
Dieser Leitfaden führt durch die Geschichte der KI-Kunst – von frühen regelbasierten Systemen bis zu heutigen Diffusionsmodellen – und zeigt, wie jeder Durchbruch die kreativen Möglichkeiten von Künstler:innen verändert hat.
Als ein Roboter Kunst für fast eine halbe Million Dollar verkaufte
Im Oktober 2018 passierte bei Christie’s in New York etwas bis dahin Einmaliges. Ein leicht verschwommenes Porträt, lose angelehnt an die europäische Malerei des 18. Jahrhunderts, wurde für 432.500 US-Dollar versteigert. Der Käufer? Ein anonymer Sammler. Der Verkäufer? Das französische Kollektiv Obvious. Der Künstler? Ein Algorithmus.
„Portrait of Edmond de Belamy“ wurde nicht von Menschenhand gemalt. Das Werk entstand durch ein Generative Adversarial Network (GAN), das mit 15.000 historischen Porträts trainiert wurde. Die Signatur in der Ecke ist kein Name, sondern eine mathematische Formel: „min max Ex[log(D(x))] + Ez[log(1 D(G(z)))].“
Die Kunstwelt war gespalten. Für die einen war es ein Wendepunkt, für die anderen ein Gimmick – manche sprachen sogar von einem Skandal, als bekannt wurde, dass das Kollektiv Open-Source-Code ohne korrekte Nennung des ursprünglichen Entwicklers Robbie Barrat verwendet hatte. Doch unabhängig von der Kontroverse wurde eines deutlich: KI-generierte Kunst war angekommen – und dieser Geist ließ sich nicht mehr zurück in die Flasche stecken.
Was die meisten übersehen: Diese Auktion im Jahr 2018 war nicht der Beginn der Geschichte der KI-Kunst. Nicht einmal ansatzweise. Die Geschichte beginnt tatsächlich 45 Jahre früher – in einem universitären Computerlabor, mit einem britischen Maler, dem sein Pinsel plötzlich nicht mehr Herausforderung genug war.
Kurze Timeline:
1960er-Jahre: Frühe Experimente mit Computer- und algorithmischer Kunst legen den Grundstein
1973: Harold Cohen startet AARON
2015: DeepDream und frühe Style-Transfer-Experimente gehen viral
2014–2018: GANs treiben den Bildrealismus voran; KI-Kunst hält Einzug in Galerien und Auktionshäuser
2021: CLIP ermöglicht ein neues Verständnis von Text und Bild
2022: Diffusionsmodelle + Midjourney / DALL·E / Stable Diffusion machen KI-Kunst massentauglich
2023–2025: Urheberrecht, Datensatz‑Einwilligungen, Provenienz‑Tools und Regulierungsdebatten gewinnen an Intensität
Der unbeabsichtigte Pionier: Wie ein Maler den ersten KI-Künstler erschuf
Harold Cohen und AARON (1973–2016)

1968 stand Harold Cohen auf dem Höhepunkt seiner Karriere. Er hatte Großbritannien auf der Biennale von Venedig vertreten. Seine abstrakten Gemälde hingen in renommierten Galerien. Und doch ließ ihn ein Gedanke nicht los. Wie er später sagte: „Vielleicht passieren außerhalb meines Ateliers interessantere Dinge als darin.“
Cohen lehrte an der UC San Diego, als er erstmals mit Computern in Berührung kam. Nicht als bloßes Werkzeug zur Digitalisierung seiner bestehenden Arbeiten, sondern auf einer viel grundsätzlicheren Ebene: Kann ein Computer selbst Kunst erschaffen? Nicht reproduzieren, nicht kopieren, sondern wirklich erschaffen?
Das Ergebnis war AARON – benannt unter anderem nach dem Bruder des Moses im Buch Exodus. Als Cohen das System 1974 an der UC Berkeley erstmals vorführte, konnte AARON lediglich abstrakte Muster erzeugen. Doch genau hier lag die Revolution: Das Programm folgte nicht einfach fest einprogrammierten Anweisungen. Cohen hatte ihm Regeln zu Komposition, Geschlossenheit und Form vermittelt – Konzepte, die er als Maler verinnerlicht hatte. Innerhalb dieses Rahmens traf AARON jedoch eigene Entscheidungen.
Man kann es so sehen: Cohen brachte AARON die Grammatik der visuellen Sprache bei – doch AARON formulierte seine eigenen Sätze.
In den 1980er-Jahren erzeugte AARON bereits klar erkennbare Bildwelten: menschliche Figuren, Pflanzen, Innenräume. Cohen ließ das System mit einem robotischen Zeichenarm arbeiten – entwickelt gemeinsam mit Forschungspartnern an Universitäten, während er erforschte, wie Code in der physischen Welt „zeichnen“ kann. So entstanden detailreiche Zeichnungen: Jede ein Unikat. Jede eindeutig im Stil von AARON – und doch jedes Mal anders.
Das Faszinierende daran: Cohen konnte nie vollständig vorhersagen, was AARON erschaffen würde. Einige seiner Programmieranweisungen führten zu Formen, die er selbst nie antizipiert hatte. Die Maschine eröffnete ihm Möglichkeiten innerhalb seines eigenen künstlerischen Systems, die ihm zuvor verborgen geblieben waren.
AARON entwickelte sich über mehr als 40 Jahre hinweg kontinuierlich weiter. Die Version von 2001 erzeugte farbenfrohe Szenen mit Figuren und Pflanzen. Die Version von 2007 („Gijon“) schuf dschungelartige Landschaften. Als Cohen 2016 starb, hinterließ er nicht nur Tausende von Kunstwerken, sondern auch eine grundlegende Frage: Wenn AARON seinen Schöpfer mit neuartigen Kompositionen überraschte – war es dann kreativ?
Große Institutionen wie das Whitney haben Cohens AARON‑bezogene Arbeiten und Dokumentationen ausgestellt und damit ihre Bedeutung für die Geschichte der digitalen Kunst unterstrichen. AARON erzeugt bis heute Bilder – allerdings gelten alle Werke, die nach Cohens Tod entstanden sind, als umstritten in Bezug auf ihre Authentizität.
Vor AARON: Generative Kunst und frühe Computerexperimente (1960er-Jahre)
Lange vor den heutigen Modellen nutzten Künstler bereits Algorithmen, um visuelle Formen zu erzeugen. Frühe Plotterzeichnungen am Computer und regelbasierte „Generative Kunst“ der 1960er-Jahre führten ein zentrales Prinzip ein, das KI-Kunst bis heute prägt: Der Künstler entwirft ein System – und dieses System erzeugt Variationen, die weit über manuelle Wiederholung hinausgehen.
Die stillen Jahrzehnte: KI-Kunst vor dem Hype (1980er–2000er)
Während Cohen an AARON arbeitete, experimentierten andere Künstler mit computergestützter Kreativität – doch außerhalb akademischer Kreise fand das kaum Beachtung.
Karl Sims ist aus dieser Ära wohl der bekannteste Name – zumindest in der digitalen Kunstszene. In den 1980er-Jahren arbeitete er am MIT Media Lab und später bei Thinking Machines (einem Supercomputer-Unternehmen). Dort schuf Sims 3D-Animationen mithilfe „künstlicher Evolution“. Sein Ansatz: zufällige 3D-Formen erzeugen, sie mutieren lassen, die spannenden auswählen und den Prozess wiederholen. Im Grunde eine Art natürliche Selektion für digitale Kreaturen.
Seine Werke „Panspermia“ (1991) und „Liquid Selves“ (1992) gewannen Spitzenpreise beim renommierten Digitalkunstfestival Ars Electronica. Wenn du diese hypnotischen, organisch wirkenden 3D-Animationen kennst, die nichts Konkretem in der Natur ähneln und sich dennoch lebendig anfühlen – genau diese Ästhetik hat Sims maßgeblich geprägt.
Scott Draves wählte mit „Electric Sheep“ (1999) einen ganz anderen Ansatz. Ein Bildschirmschoner – ja, die gab es mal –, aber einer, der dazulernt. Über tausende Computer verteilt erzeugt das System sich ständig weiterentwickelnde, fractale Animationen, die sogenannten „Sheep“. Zuschauer stimmen darüber ab, welche Muster ihnen gefallen, und genau diese werden weiter „gezüchtet“. Und ja: Das Projekt läuft bis heute. Auf electricsheep.org kannst du ihm immer noch zusehen.
In dieser Phase setzte sich der Begriff „Generative Kunst“ durch. Künstlerinnen und Künstler schrieben Code, der Regeln und Parameter festlegte – und überließen es anschließend den Algorithmen, innerhalb dieser Vorgaben Werke zu erzeugen. Mit Processing, einer speziell für Kreative entwickelten Programmiersprache, wurde dieser Ansatz ab 2001 deutlich zugänglicher.
Aber eines ist klar: Für die meisten fühlte sich das nicht wie „KI“ an. Es waren beeindruckende digitale Kunstprojekte, keine Frage – aber nicht intelligent. Die Systeme verstanden nicht, was sie erschufen. Sie folgten Regeln, so komplex sie auch waren.
Doch das sollte sich bald ändern.
Deep Learning verändert alles (2012–2015)
Anfang der 2010er-Jahre kam es zu einem grundlegenden Wandel. Drei Entwicklungen trafen zusammen:
Zunächst wurden GPUs (Graphics Processing Units) leistungsfähig genug, um riesige neuronale Netzwerke zu trainieren. Ausgerechnet Chips, die ursprünglich fürs Gaming entwickelt wurden, machten damit zentrale KI‑Durchbrüche möglich.
Zweitens wurden große Datensätze verfügbar. ImageNet, 2009 gestartet, umfasst Millionen gelabelter Bilder. Damit hatten neuronale Netze erstmals genug Beispiele, um Muster wirklich zu lernen.
Drittens machten Deep-Learning-Algorithmen enorme Fortschritte. Ab 2012 verbesserten Deep-Learning-Modelle die Benchmarks der Bilderkennung drastisch (bekannt geworden durch ImageNet) und zeigten, dass neuronale Netze visuelle Muster in großem Maßstab lernen können – und damit klassische Computer-Vision-Ansätze klar übertrafen. Forschende erkannten: Macht man neuronale Netze tief genug (mit vielen Schichten), versorgt sie mit ausreichend Daten und Rechenleistung, beginnen sie Dinge zu leisten, die überraschend intelligent wirken.
Für die Kunst waren die Auswirkungen tiefgreifend.
Der Deep-Dream-Moment (2015)
Im Juni 2015 veröffentlichte der Google-Ingenieur Alexander Mordvintsev etwas ziemlich Ungewöhnliches. Er beschäftigte sich damit, sichtbar zu machen, wie neuronale Netze Objekte erkennen. Die zugrunde liegende Frage: Wenn ein Netzwerk darauf trainiert ist, Hunde zu erkennen – was passiert, wenn man den Prozess umkehrt und es auffordert, die hundeähnlichen Muster, die es in einem Bild erkennt, gezielt zu verstärken?
Die Ergebnisse waren abgefahren. Psychedelisch. Geradezu halluzinogen. Gab man dem Netzwerk ein Foto von Wolken, entdeckte es überall Hundegesichter, Augen und architektonische Formen – und verstärkte sie zu surrealen Landschaften. Die Kunstszene war elektrisiert.
Google nannte es DeepDream (offiziell „Inceptionism“). Innerhalb weniger Wochen entstanden ganze Galerien mit DeepDream-Kunst. Der Stil wurde sofort ikonisch: Bilder voller Augen, verschlungener, organischer Muster und surrealer Strukturen. Bis heute erkennt man ein DeepDream-Bild auf den ersten Blick.
Kulturell bedeutsam war nicht nur die Optik. Entscheidend war die Erkenntnis: So sieht ein neuronales Netzwerk die Welt. Es sieht nicht, was wir sehen. Es erkennt Muster, Korrelationen, statistische Zusammenhänge. Und visualisiert man diese Muster, wirken sie wie Fieberträume.
Es war unglaublich seltsam. Und genau das liebten die Leute.
Style Transfer: Neuronale Netzwerke als Künstler (2015–2016)
Etwa zur gleichen Zeit fanden Forscher heraus, wie sich neuronale Netzwerke für sogenanntes „Style Transfer“ nutzen lassen: Der Stil eines Bildes wird auf ein anderes übertragen. Dein Foto im Stil von Van Goghs „Sternennacht“? In Sekunden erledigt.
Das technische Paper war anspruchsvoll (Gatys et al., 2015), doch die Umsetzung ließ nicht lange auf sich warten: Apps schossen aus dem Boden. Prisma wurde 2016 zum viralen Hit. Plötzlich konnte jeder mit dem Smartphone „Kunst“ erschaffen, die aussah wie berühmte Gemälde.
Kritiker merkten an, dass hier keine wirklich neue Kunst entstehe, sondern eher algorithmische Nachahmung. Dennoch zeigte sich erstmals, dass neuronale Netze künstlerische Stile so gut erfassen konnten, dass sie sie überzeugend reproduzierten. Das war neu.
GANs: Die Technologie, die den Durchbruch schaffte (2014–2020)
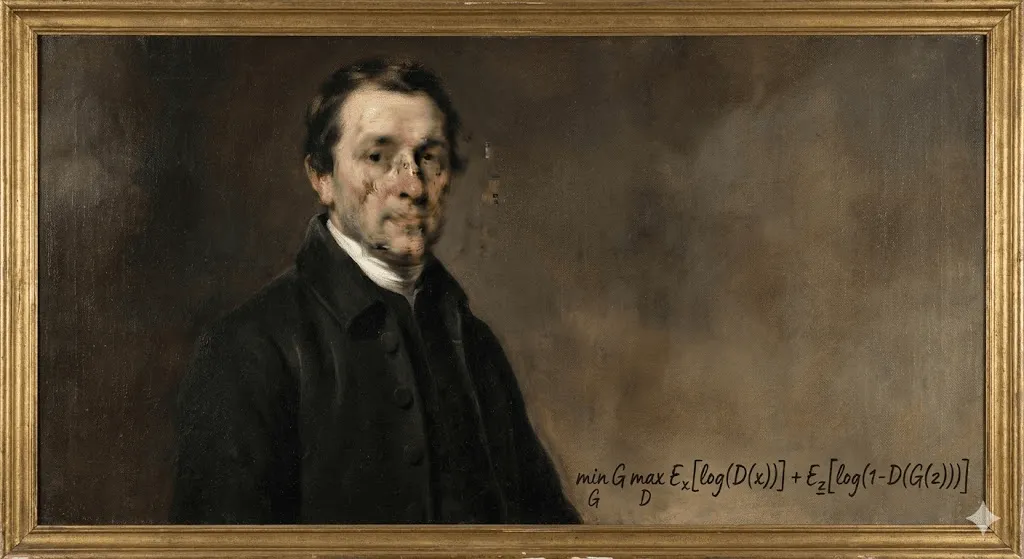
Für Künstler:innen waren GANs so wichtig, weil sie „Stil“ aus Daten lernbar machten. Plötzlich ließ sich ein ganzes visuelles Universum erkunden, ohne jede einzelne Regel mühsam von Hand zu programmieren.
Wie GANs funktionieren (ganz ohne Mathe)
2014 stellte Ian Goodfellow, damals Doktorand an der University of Montreal, Generative Adversarial Networks in einer wissenschaftlichen Arbeit vor, die sich zu einer der meistzitierten Publikationen im Machine Learning entwickeln sollte. Yann LeCun, einer der Vordenker des Deep Learning, nannte GANs „die interessanteste Idee im Machine Learning der letzten zehn Jahre“.
Das Grundprinzip: Zwei neuronale Netzwerke treten in einem spielerischen Wettstreit gegeneinander an.
Network 1 (der Generator): Versucht, künstliche Bilder zu erzeugen, die von echten kaum zu unterscheiden sind.
Netzwerk 2 (der Discriminator): Versucht, echte von gefälschten Bildern zu unterscheiden.
Der Generator beginnt kläglich und produziert reines Rauschen. Der Discriminator erkennt die Fälschungen sofort. Doch jetzt kommt der clevere Teil: Der Generator lernt aus seinen Fehlern. Er passt sich an, um den Discriminator zu täuschen. Der Discriminator wird besser darin, Fakes zu entlarven. Der Generator justiert erneut nach. Hin und her, tausendfach.
Irgendwann wird der Generator so gut, dass selbst der Diskriminator echte von falschen Bildern nicht mehr zuverlässig unterscheiden kann. In diesem Moment entsteht ein neuronales Netzwerk, das aus dem Nichts überzeugende Bilder erzeugt.
Der Durchbruch: GANs brauchen keine von Menschen gelabelten Trainingsdaten für jede einzelne Ausgabe. Sie lernen die zugrunde liegende statistische Verteilung dessen, worauf sie trainiert werden – Gesichter, Landschaften, alles – und können daraus unendlich viele Varianten generieren.
Von bizarren Gesichtern zu überzeugender Kunst (2015–2018)
Die ersten GAN-Ergebnisse waren … nennen wir sie „experimentell“. Wer sich an die verzerrten, alptraumhaften KI-Gesichter von etwa 2015 erinnert – irgendwo zwischen gruselig und uncanny valley – hat frühe GANs gesehen. Forschende teilten sie als Machbarkeitsnachweis, und im Internet wurden sie schnell zu Memes.
Doch die Technologie entwickelte sich rasant. Bereits 2017 erzeugte NVIDIAs Progressive GAN Gesichter in 1024×1024 Pixeln, die von Fotografien nicht zu unterscheiden waren. 2018 ging StyleGAN noch einen Schritt weiter: mit höherer Auflösung und zusätzlicher Kontrolle über verschiedene Aspekte der Bilder.
Künstler begannen zu experimentieren. Mario Klingemann, ein deutscher Künstler, schuf mit „Memories of Passersby I“ (2018) eine Installation mit zwei Bildschirmen, auf denen endlos generierte Porträts erscheinen. Sie ziehen vorbei wie Erinnerungen, ohne sich jemals zu wiederholen. Das Werk wurde bei Sotheby’s für 40.000 £ verkauft.
Helena Sarin wählte einen anderen Ansatz: Sie trainierte GANs mit ihren eigenen Zeichnungen statt mit Fotografien. So behielt sie die künstlerische Kontrolle und nutzte zugleich die generative Kraft von KI. Ihre Serie „AI Candy Store“ hat eine unverwechselbare, klar als KI erkennbare Ästhetik – durchzogen von ihrem ganz persönlichen Stil.
Robbie Barrat, damals noch Schüler, trainierte GANs mit klassischer Kunst und stellte seinen Code offen auf GitHub zur Verfügung. (Genau dieser Code wurde später von Obvious für den Verkauf bei Christie’s genutzt – und löste eine Debatte über Urheberschaft und künstlerische Anerkennung aus.)
The Next Rembrandt (2016)
Bevor Obvious mit seiner Auktion für Schlagzeilen sorgte, gab es bereits „The Next Rembrandt“ (2016) – ein Marketingprojekt der ING-Bank gemeinsam mit mehreren niederländischen Institutionen. Dafür wurden 346 Gemälde Rembrandts analysiert, ein Algorithmus auf seinen Stil trainiert und schließlich ein „neues“ Rembrandt-Porträt generiert.
Technisch gesehen war es noch kein GAN, doch die Idee war ähnlich: Kann KI im Stil eines bestimmten Künstlers erschaffen? Das Projekt sorgte für enorme mediale Aufmerksamkeit. Kritiker lobten die technische Leistung, stellten aber infrage, ob es sich um Kunst handelte – oder lediglich um eine raffinierte Form der Nachahmung.
Es warf Fragen auf, mit denen wir bis heute ringen: Ist das Training mit den Werken einzelner Künstler eine respektvolle Hommage oder rechnerische Aneignung? Ab wann wird Inspiration zum Diebstahl?
Der Durchbruch: Als KI-Kunst im Mainstream ankam (2022–heute)
CLIP: KI beibringen, Text und Bilder zu verstehen (2021)
Der nächste Durchbruch kam im Januar 2021 von OpenAI: CLIP (Contrastive Language Image Pre-Training). Die technischen Details sind komplex, die Wirkung dagegen leicht zu verstehen: CLIP konnte den Zusammenhang zwischen Text und Bildern erfassen.
Frühere Systeme brauchten gelabelte Daten: „Das ist eine Katze“, „das ist ein Hund“. CLIP hingegen lernte aus 400 Millionen Bild-Text-Paaren, die aus dem Internet gesammelt wurden. Dabei erkannte das Modell, welche Wörter typischerweise mit welchen visuellen Merkmalen zusammen auftreten. So entstand ein gemeinsamer „Raum“, in dem sich Texte und Bilder direkt miteinander vergleichen lassen.
Warum das entscheidend war: CLIP wurde mit einem generativen Modell kombiniert – und plötzlich ließen sich Bilder direkt aus Textbeschreibungen erzeugen. Einfach „ein Astronaut auf einem Pferd“ eingeben, und das System versteht, wie dieses Bild aussehen soll.
Künstler integrierten CLIP rasch in ihre Workflows. In Kombination mit GANs oder anderen Generatoren ließ sich die Bildentstehung erstmals gezielt über Sprache steuern. Umständlich war es – aber es funktionierte.
Die Revolution 2022: DALL E 2, Midjourney, Stable Diffusion

Dann kam 2022 – und plötzlich war alles anders.
DALL·E 2 (OpenAI, April 2022) kombinierte CLIP mit Diffusionsmodellen (dazu gleich mehr), um aus Text hochwertige, in sich stimmige Bilder zu erzeugen. Der frühe Zugang war ausgewählten Künstler:innen und Forscher:innen vorbehalten. Die Warteliste wuchs schnell auf über eine Million Menschen an. Die von OpenAI veröffentlichten Bilder waren beeindruckend kreativ, kohärent und oft schlichtweg schön.
Midjourney (Midjourney Inc., Juli 2022) ging einen anderen Weg: communitygetrieben, auf Discord beheimatet, mit klarem Fokus auf ästhetische Schönheit. Schnell entwickelte sich ein unverwechselbarer Stil – malerisch, dramatisch, oft fantastisch. Künstlerinnen und Künstler strömten zur Plattform. Der Discord-Server wurde zu einer der aktivsten kreativen Communities im Netz.
Stable Diffusion (Stability AI, August 2022) war der Durchbruch in Sachen Zugänglichkeit. Im Gegensatz zu DALL E 2 (nur im Web, mit kontrolliertem Zugriff) oder Midjourney (abo-basiert) war Stable Diffusion Open Source. Jeder konnte es herunterladen, lokal ausführen und nach Belieben anpassen.
Innerhalb weniger Monate entstand ein ganzes Ökosystem: Weboberflächen, mobile Apps, Plugins für Photoshop, Hunderte maßgeschneiderte Modelle, trainiert auf bestimmte Stile. Diese Explosion war beispiellos.
Ende 2022 wurden soziale Netzwerke von KI-Kunst überschwemmt. „Prompt Engineering“ wurde plötzlich zur eigenen Fähigkeit. Überall teilten Menschen Tipps, um bessere Ergebnisse zu erzielen. Gleichzeitig entbrannten hitzige Debatten darüber, ob das die Kunst demokratisiert – oder sie zerstört.
Diffusion Models: Die Technologie hinter der Magie
Was ist also ein Diffusionsmodell? Es ist tatsächlich von der Physik inspiriert – konkret davon, wie sich Teilchen in einem Medium ausbreiten.
Der Trainingsprozess:
- Nimm ein reales Bild
- Füge schrittweise Rauschen hinzu, bis nur noch zufälliges Bildrauschen übrig ist (Forward Diffusion)
- Trainiere ein neuronales Netz, diesen Prozess umzukehren und das Rauschen wieder zu entfernen (Reverse Diffusion)
Der Generierungsprozess: Er beginnt mit reinem Rauschen, durchläuft den umgekehrten Diffusionsprozess und endet in einem stimmigen Bild. Die Textkonditionierung (über CLIP) steuert dabei, welche Art von Motiv entsteht.
Warum sich Diffusionsmodelle für diesen Anwendungsfall gegen GANs durchgesetzt haben: Sie sind stabiler, einfacher zu trainieren und deutlich besser darin, Text-Prompts präzise umzusetzen. GANs kommen zwar weiterhin in bestimmten Bereichen zum Einsatz, doch die explosionsartige Entwicklung im Jahr 2022 wurde klar von Diffusionsmodellen geprägt.
Technischer Exkurs: Das zentrale Paper war „Denoising Diffusion Probabilistic Models“ (Ho et al., 2020). Frühere Arbeiten von Sohl-Dickstein et al. (2015) haben jedoch bereits die Grundlagen gelegt. Wer die Mechanik wirklich verstehen möchte, findet in diesen Veröffentlichungen gute Einstiegspunkte – sollte sich aber auf anspruchsvolle Mathematik einstellen.
Die Zahlen
- Anfang 2023 hatten diese Tools bereits Millionen von Nutzer:innen erreicht – und KI-generierte Bilder überschwemmten soziale Plattformen.
- DALL·E: über 3 Millionen Nutzer:innen (Warteliste aufgehoben)
- Stable Diffusion: nicht exakt erfassbar (Open Source, dezentral), GitHub-Statistiken deuten jedoch auf Millionen hin
Menschen erzeugten Hunderte Millionen KI-Bilder. Ganze Geschäftsmodelle entstanden rund um KI-Kunst-Services. Stockfoto-Plattformen mussten hastig neue Richtlinien entwickeln. Und viele traditionelle Künstler sahen mit Entsetzen zu, wie „KI-Künstler“ plötzlich zu einer offiziellen Berufsbezeichnung wurde.
Die andere Seite der KI-Kunst: Akademische Anwendungen
Während sich alle auf Text-zu-Bild-Generatoren konzentrierten, nutzten Forschende KI im Hintergrund, um die kunsthistorische Forschung grundlegend zu verändern. Dieser Teil der Geschichte der KI-Kunst bekommt deutlich weniger Aufmerksamkeit – ist wissenschaftlich betrachtet aber vielleicht der bedeutendere.
Computer Vision für Zuschreibung und Analyse
Kunsthistoriker hatten schon immer Schwierigkeiten mit der Zuschreibung – also damit festzustellen, wer ein bestimmtes Werk geschaffen hat. Heute helfen dabei neuronale Netze.
Rutgers Art & AI Lab (geleitet von Ahmed Elgammal) entwickelte Systeme, die Pinselstriche, Kompositionselemente und stilistische Merkmale analysieren, um Künstler zu identifizieren oder Fälschungen zu erkennen. 2017 bestimmten diese Systeme in kontrollierten Tests die Künstler nicht beschrifteter Werke mit einer Trefferquote von über 90 %.
Rekonstruktion verlorener Werke: Neuronale Netzwerke, die mit den bekannten Arbeiten eines Künstlers trainiert werden, können plausible Rekonstruktionen verlorener oder beschädigter Werke erzeugen. Das bekannteste Beispiel: der Einsatz von KI, um Rembrandts „Die Nachtwache“ zu extrapolieren, die 1715 beschädigt wurde – und zu zeigen, wie die abgeschnittenen Bildteile ausgesehen haben könnten. (Auch wenn Kunsthistoriker über die Genauigkeit diskutieren, handelt es sich um fundierte Spekulation, nicht um eine tatsächliche Wiederherstellung.)
Herculaneum-Schriftrollen: Im Jahr 2023 nutzten Informatiker maschinelles Lernen, um Texte aus antiken Schriftrollen zu lesen, die beim Ausbruch des Vesuvs im Jahr 79 n. Chr. karbonisiert wurden. Die Rollen sind zu fragil, um sie zu entrollen, doch mithilfe von CT-Scans und trainierten neuronalen Netzen konnten Tintenmuster erkannt werden. So ermöglicht KI erstmals seit 2.000 Jahren wieder den Zugang zu diesen antiken Texten. (Quelle: Nature, 2023)
Museen und KI
Große Institutionen haben auf faszinierende Weise mit KI experimentiert:
Das Met experimentierte mit KI-gestützter Sammlungsvisualisierung und kartierte riesige Museumsarchive in einen „latenten Raum“, um unerwartete Beziehungen zwischen Objekten sichtbar zu machen.: In Zusammenarbeit mit dem Metropolitan Museum, dem MIT und dem Künstler Refik Anadol wurden neuronale Netzwerke mit der gesamten Sammlung des Met (über 375.000 Kunstwerke) trainiert. Anschließend visualisierte man diesen „latenten Raum“ – ein konzeptuelles Zwischenfeld zwischen unterschiedlichen Objektarten. Dabei traten überraschende Verbindungen zutage: Ein antiker persischer Krug und eine Vase aus dem 19. Jahrhundert können konzeptionell näher beieinanderliegen, als es menschliche Kurator:innen je vermutet hätten.
KI-Experimente im MoMA: Refik Anadol zeigte mit „Unsupervised“ (2022–2023) eine Arbeit, die mithilfe von Machine Learning auf Basis der Sammlung des MoMA entstand. Das Modell erzeugte fließende, traumartige Projektionen im Foyer des Museums. Die Reaktionen waren gespalten: Für die einen wirkte es wie ein kurzlebiger Effekt, für andere eröffnete es einen völlig neuen Zugang zu Museumsarchiven.
Transparent-AI-Projekt der LMU München: Unter der Leitung von Professor Hubertus Kohle entwickelt dieses Forschungsprojekt KI-Tools für die Kunstgeschichte, die ihre Entscheidungen nachvollziehbar erklären. Klassische neuronale Netze gelten als „Black Boxes“: Sie liefern Ergebnisse, ohne offenzulegen, warum. Genau hier setzt das Projekt an und macht KI-Entscheidungen transparent – eine zentrale Voraussetzung für die Akzeptanz in der Wissenschaft. Die Modelle werden darauf trainiert, visuelle Ähnlichkeiten zwischen Kunstwerken zu erkennen und verständlich darzulegen, welche Merkmale zu ihren Schlussfolgerungen geführt haben.
Diese Anwendungen schaffen keine neue Kunst – aber sie verändern grundlegend, wie wir Kunstgeschichte erforschen und verstehen. Das ist womöglich nachhaltiger als jedes einzelne generierte Bild.
Die Debatte: Urheberrecht, Ethik und die Zukunft der Kreativität

Ab hier wird es hitzig. Die technischen Fortschritte sind beeindruckend – doch die ethischen Fragen dahinter sind … komplex.
Der Urheberrechtsstreit
Das Kernproblem: KI-Kunstmodelle werden mit Milliarden von Bildern aus dem Internet trainiert. Viele davon sind urheberrechtlich geschützt. Künstler:innen wurden weder um Erlaubnis gefragt noch dafür vergütet. Und nun können Systeme, die mit ihren Werken trainiert wurden, in Sekunden Bilder „in ihrem Stil“ erzeugen.
Bedeutende Klagen eingereicht:
Getty Images vs. Stability AI (Januar 2023): Getty wirft Stability vor, Millionen eigener Bilder für das Training von Stable Diffusion gescrapet zu haben. Als Beleg führen sie an, dass einige der generierten Bilder noch Fragmente von Getty-Wasserzeichen enthalten – ein klar sichtbarer Hinweis auf die Herkunft.
Sammelklage von Künstler:innen gegen Midjourney, Stable Diffusion, DeviantArt (Januar 2023): Angeführt von den Künstlerinnen Sarah Andersen, Kelly McKernan und Karla Ortiz. Der Vorwurf: massenhafte Urheberrechtsverletzungen. Das Verfahren ist Stand Ende 2024 noch anhängig, und Rechtsexpert:innen sind sich über den möglichen Ausgang uneins.
Die rechtliche Kernfrage lautet: Gilt das Training mit urheberrechtlich geschützten Bildern als Fair Use – vergleichbar mit einem Studenten, der durch das Studium bestehender Kunst lernt – oder handelt es sich um eine Urheberrechtsverletzung, weil fremde Werke ohne Erlaubnis kommerziell genutzt werden?
Die Gerichte haben noch nicht entschieden. Diese Entscheidung wird die gesamte Branche prägen.
Künstlerreaktionen: Gegenwehr
Künstler warten nicht auf Gerichtsurteile – sie entwickeln technische Gegenmaßnahmen.
Glaze (University of Chicago, 2023): Eine Software, die digitale Kunstwerke für Menschen unsichtbar verändert, aber KI-Trainingsdaten gezielt „vergiftet“. Trainiert ein Modell mit Glaze-geschützten Bildern, werden seine Ergebnisse verzerrt. Im Grunde eine aktive Art von Wasserzeichen – nur dass es nicht identifiziert, sondern sabotiert.
Nightshade (ebenfalls University of Chicago, 2023): Deutlich aggressiver als Glaze. Schützt nicht nur das einzelne Nightshade‑Bild, sondern verschlechtert gezielt die Gesamtleistung des Modells. Werden genügend Nightshade‑Bilder hochgeladen, die als „Hund“ beschriftet sind, tatsächlich aber Katzen zeigen, verliert das Modell mit der Zeit sein klares Verständnis davon, wie Hunde aussehen.
Diese Tools sind umstritten. KI-Forschende sprechen von schädlicher Sabotage. Künstlerinnen und Künstler sehen darin Selbstverteidigung. Beide Seiten haben gute Argumente.
Der „Do Not Train“-Vorschlag: Künstler:innen und Interessenvertretungen schlagen Metadaten-Tags vor, die Werke für das KI-Training sperren. Einige Plattformen (DeviantArt, Shutterstock) haben Opt-out-Systeme eingeführt. Doch die Durchsetzung ist gering. KI-Unternehmen können die Tags schlicht ignorieren – und viele tun es.
Die Debatte um Kreativität
Jenseits des Urheberrechts steht eine grundlegendere, philosophische Frage: Ist KI‑generierte Kunst überhaupt Kunst?
Was es nicht ist:
- Fehlt menschliche Intention und emotionale Tiefe
- Entsteht durch das Neukombinieren bestehender Werke – nicht durch echte Neuerfindung
- Erfordert keine besondere Fähigkeit: Jede:r kann einen Prompt eingeben
- Untergräbt das, was Kunst wertvoll macht: menschliche Kreativität und den schöpferischen Prozess
Argumente dafür:
- Werkzeuge machen Kunst nicht weniger wertvoll (die Kamera hat die Malerei auch nicht beendet)
- Prompt Engineering und kuratorische Auswahl sind echte Fähigkeiten
- Der Mensch lenkt die KI und trifft die kreativen Entscheidungen
- Ermöglicht neue Ausdrucksformen, die zuvor unmöglich waren
Meine Sicht: Das ist die falsche Debatte. Das ist, als würde man 1850 darüber streiten, ob Fotografie Kunst ist. Natürlich kann KI Kunst schaffen – das haben wir längst gesehen. Die besseren Fragen sind: Welche Art von Beziehung wollen wir zwischen menschlicher und maschineller Kreativität? Wer profitiert? Was geht verloren? Und was gewinnen wir?
Die Realität der Arbeitsplatzverdrängung
Das ist keine Theorie – echte Menschen verlieren ihre Jobs.
Eine Umfrage der Concept Art Association aus dem Jahr 2023 ergab:
- 73 % der Concept Artists berichteten von weniger Jobmöglichkeiten
- 62 % verloren Freelance-Aufträge an KI
- Einstiegspositionen verschwinden am schnellsten
Unternehmen setzen KI zunehmend für erste Konzeptentwürfe, Storyboards und Hintergrunddesigns ein – also genau für die Aufgaben, die früher oft von Nachwuchskünstler:innen übernommen wurden. Manche verteidigen das mit dem Argument, das sei nichts anderes als der Wechsel von traditionellen zu digitalen Werkzeugen. Doch das Tempo dieses Wandels ist beispiellos, und die betroffenen Künstler:innen sind nachvollziehbarerweise wütend.
Gleichzeitig entstehen neue Rollen: KI-Art-Direktoren, Prompt Engineers, Spezialisten für hybride Mensch-KI-Workflows. Ob diese die wegfallenden Jobs im Verhältnis 1:1 ersetzen, bleibt abzuwarten.
Das Bias-Problem
KI-Kunstmodelle übernehmen Verzerrungen aus ihren Trainingsdaten. Fragt man nach „a CEO“, erscheinen überwiegend weiße Männer. „A nurse“ liefert vor allem Frauen. Und „a beautiful person“ ist stark auf junge, weiße, konventionell attraktive Gesichter verzerrt.
Google versuchte 2024 mit Gemini gegenzusteuern, indem die Vielfalt in historischen Bildern erhöht wurde – schoss dabei jedoch über das Ziel hinaus. Das löste eine Kontroverse darüber aus, wie KI-Modelle historische Genauigkeit, Repräsentation und Sicherheit ausbalancieren sollen, etwa bei der Darstellung ethnisch vielfältiger europäischer Adliger des 18. Jahrhunderts. Google entschuldigte sich und nahm die Funktion offline. Der Vorfall machte deutlich, wie schwierig diese Balance in der Praxis ist.
Bias betrifft nicht nur demografische Fragen. KI-Kunst tendiert auch ästhetisch in bestimmte Richtungen: glatt, kommerziell, konventionell „schön“. Experimentelle, avantgardistische oder bewusst hässliche Kunst erscheint seltener in den Ergebnissen, weil sie auch in den Trainingsdaten seltener ist – und weniger belohnt wird. In diesem Sinne kann KI künstlerisch erstaunlich konservativ sein, selbst wenn sie technisch radikal wirkt.
Wo wir heute stehen (2024–2025)
Der aktuelle Stand
Ende 2024/Anfang 2025 ist die KI-Kunst zwar gereift, befindet sich aber weiterhin im Umbruch:
DALL E 3 (in ChatGPT Plus integriert) verbesserte die Prompt-Interpretation deutlich. Du kannst jetzt im Dialog beschreiben, was du willst – die KI versteht Nuancen viel besser.
Midjourney V6 setzte die Messlatte für Ästhetik noch höher – mit verbesserter Textdarstellung (noch nicht perfekt) und deutlich besser steuerbaren Stilen.
Stable Diffusion XL und darüber hinaus entwickelt sich kontinuierlich weiter: Die Open-Source-Community bringt spezialisierte Modelle hervor – von Anime über Fotorealismus bis hin zu klar definierten künstlerischen Stilen.
Adobe Firefly steht für einen „Responsible AI“-Ansatz: trainiert ausschließlich mit Adobe-Stock-Bildern und gemeinfreien Inhalten, inklusive integrierter kommerzieller Nutzungslizenzen. Technisch weniger leistungsfähig als Stable Diffusion, dafür rechtlich deutlich sicherer für den professionellen Einsatz.
Videogenerierung: Die nächste Evolutionsstufe
Text-zu-Bild war erst der Anfang. 2024 brachte der KI‑Videogenerierung spürbare Fortschritte:
Runway Gen 2 und Pika können kurze Videoclips aus Text oder Bildern erzeugen. Die Qualität ist noch uneinheitlich: Objekte verformen sich teils unnatürlich, die Physik wirkt seltsam – wird aber von Monat zu Monat besser.
OpenAI’s Sora (angekündigt im Februar 2024, mit begrenzter Verfügbarkeit) zeigte erstmals fotorealistische, in sich stimmige Videos von bis zu einer Minute Länge. Die Demo-Videos waren schlicht atemberaubend. Gleichzeitig machten sie vielen Menschen Angst – denn Deepfakes galten schon als Problem, noch bevor KI überzeugende Videos direkt aus Text erzeugen konnte.
3D und darüber hinaus
KI-Kunst entwickelt sich längst über zweidimensionale Bilder hinaus:
Point E und Shap E (OpenAI) erzeugen 3D-Modelle aus Text-Prompts. Die Qualität ist noch begrenzt, doch die Richtung ist eindeutig.
Die NeRF (Neural Radiance Fields)-Technologie erzeugt aus 2D-Bildern 3D-Szenen – mit Einsatzmöglichkeiten von der Filmproduktion über Game Development bis hin zur architektonischen Visualisierung.
Musik, Text und Multimodalität
KI-Musikgeneration (Suno, Udio) erreichte 2024 ein „ziemlich gutes“ Niveau. Musiker wurden dadurch nicht ersetzt, aber funktionale Hintergrundmusik lässt sich seitdem deutlich einfacher und kostengünstiger produzieren.
Multimodale Modelle (GPT‑4 mit Vision, Gemini) können Bilder analysieren, sie in Text beschreiben und auf dieser Basis neue Bilder erzeugen. Die Grenzen zwischen Text‑KI und Bild‑KI verschwimmen zunehmend.
Was kommt als Nächstes: Prognosen und Möglichkeiten
Kurzfristig (2025–2027)
Wahrscheinlich:
- Videogenerierung erreicht Massentauglichkeit
- Konsistente Charaktergenerierung (dieselbe Person über mehrere Bilder hinweg) wird zuverlässig
- Mehr rechtliche Klarheit beim Urheberrecht (erzwungen durch laufende Klagen)
- Marktkonsolidierung, da kleinere Anbieter übernommen werden oder vom Markt verschwinden
- Der Gegenwind nimmt zu: Einige Plattformen und Kunden verbieten KI-Kunst
Möglich:
- Echtzeit-Videoerzeugung während Videoanrufen oder Livestreams
- KI-Kunst wird zum Standardwerkzeug in professionellen Kreativ-Workflows
- Entstehung von „Certified Human Made“-Kunst als Premium-Kategorie
- Große Museumsausstellungen zur Geschichte der KI-Kunst (über einzelne Installationen hinaus)
Mittelfristig (2027–2030)
Spekulativ, aber plausibel:
- Text‑, Bild‑, Video‑, 3D‑ und Audiogenerierung werden in einzelnen Modellen zusammengeführt
- Personalisierte KI‑Modelle, die auf individuelle künstlerische Stile trainiert sind, werden zum Standard
- AR/VR‑Integration bringt KI‑Kunst über Headsets direkt in den physischen Raum
- Rechtliche Rahmenbedingungen schaffen (wahrscheinlich holprige) Kompromisse rund um Trainingsdaten
- Neue Kunstbewegungen entstehen, die genuin KI‑basiert sind – nicht bloß Adaptionen vor‑KI‑Stile
Langfristig: Die großen Fragen
Wird KI die menschliche Kreativität übertreffen? Falsche Frage – es sind unterschiedliche Dinge.
Werden menschliche Künstler überflüssig? Unwahrscheinlich. Die Nachfrage nach „authentisch menschlichen“ Arbeiten könnte sogar steigen, wenn KI den Markt mit leicht produzierten Inhalten überschwemmt.
Wem gehört KI‑generierte Kunst? Darüber wird noch vor Gericht gestritten. Nach aktueller US‑Urheberrechtslage gehört sie niemandem (keine menschliche Urheberschaft) – doch das dürfte sich ändern.
Wie entschädigen wir Künstler:innen, deren Werke KI trainieren? Das ist die Milliardenfrage – im wahrsten Sinne. Mögliche Ansätze: Lizenzgebühren, nutzungsbasierte Micropayments oder verpflichtende Lizenzmodelle wie in der Musikbranche. Keines davon existiert bislang in großem Maßstab.
Sollte es KI-freie Zonen geben? Manche fordern, bestimmte Bereiche – etwa Kinderbücher, Gedenkstätten oder juristische Beweismittel – ausschließlich menschlichen Kreativen vorzubehalten. Andere halten das für modernen Luddismus. Die Debatte ist weiterhin offen.
Lehren aus der Geschichte
Blickt man auf über 50 Jahre KI-Kunstgeschichte zurück, lassen sich einige Muster erkennen:
- Die Werkzeuge werden demokratisiert. AARON verlangte Programmierkenntnisse. GANs erfordern Machine-Learning-Wissen. Moderne Tools brauchen im Grunde nur einen Discord-Account. Jede Generation wird zugänglicher.
- Der anfängliche Hype übertrifft die Realität. Jeder Durchbruch löst „Die Kunst ist tot“-Rufe aus. Kunst stirbt nicht. Sie passt sich an.
- Rechtliche und ethische Rahmenbedingungen hinken der Technologie hinterher. Wir diskutieren noch immer Urheberrechtsfragen zu Technologien, die vor drei Jahren eingeführt wurden. Recht bewegt sich langsam; Technologie nicht.
- Sorgen über Verdrängung sind oft berechtigt, aber unvollständig. Ja, manche Jobs verschwinden. Gleichzeitig entstehen neue. Die Übergangsphase ist schmerzhaft – besonders für diejenigen, die mittendrin stecken.
- Kunst überlebt. Fotografie hat die Malerei nicht getötet. Digitale Werkzeuge haben traditionelle Medien nicht verdrängt. KI wird menschliche Kreativität nicht beenden. Aber sie verändert, wie, warum und was wir schaffen.
Fazit: Das nächste Kapitel aufschlagen
Von Harold Cohens geduldiger Programmierarbeit im Jahr 1973 bis hin zu Millionen von Menschen, die heute in Sekunden Bilder erzeugen, ist die Geschichte der KI-Kunst vor allem eine Geschichte darüber, wie sich das Verhältnis zwischen menschlicher Kreativität und rechnerischer Leistungsfähigkeit immer wieder neu definiert hat.
Die Fragen, vor denen wir heute stehen, sind nicht in erster Linie technischer Natur – die Technologie funktioniert und entwickelt sich rasant weiter. Es sind menschliche Fragen:
- Wie stellen wir sicher, dass KI menschliche Kreativität stärkt statt sie zu ersetzen?
- Wie können Künstler:innen fair entlohnt werden, deren Werke KI überhaupt erst ermöglichen?
- Wer darf an dieser neuen kreativen Landschaft teilhaben?
- Welche Aspekte von Kreativität sollen bewusst menschlich bleiben?
- Wie sichern wir künstlerische Karrieren und Existenzen in Zeiten des technologischen Wandels?
Auf diese Fragen gibt es keine einfachen Antworten. Sie erfordern einen kontinuierlichen Aushandlungsprozess zwischen Künstler:innen, Technolog:innen, Unternehmen, politischen Entscheidungsträgern und der Öffentlichkeit. Die Geschichte der KI-Kunst ist noch lange nicht abgeschlossen – wir erleben gerade eines ihrer prägendsten Kapitel.
Fest steht: KI zu ignorieren lässt sie nicht verschwinden – genauso wenig wie das Verdrängen der echten Herausforderungen, die sie mit sich bringt. Der Weg nach vorn führt über Auseinandersetzung: ehrlich in der Problembenennung, offen für neue Möglichkeiten und konsequent im Einsatz für Fairness.
Ob KI wirklich kreativ sein kann, ist vielleicht die falsche Frage. Kreativität ist kein Entweder-oder. Sie bewegt sich auf Skalen, entsteht in Zusammenarbeit und zeigt sich in unerwarteten Kombinationen. Wenn uns die ersten 50 Jahre der KI-Kunst eines gelehrt haben, dann dies: Kreativität ist größer, vielschichtiger und seltsamer, als wir dachten. Und der Mensch scheint – im Guten wie im Schlechten – entschlossen, sie zu teilen.
Das nächste Kapitel wird gerade geschrieben. Gestalte es bewusst mit.