AIアートの完全年表:AARONからMidjourneyまで(1973–2025)
最終更新日: 2026-01-22 18:07:34

人工知能はいかにして学術的な研究対象から、表現の世界を揺さぶるアートの革新へと進化したのか――そして、なぜ今それが重要なのか
本ガイドでは、初期のルールベースのシステムから現在の拡散モデルに至るまで、AIアートの歴史をたどりながら、それぞれのブレイクスルーがアーティストの表現をどう進化させてきたのかをわかりやすく紹介します。
ロボットが生み出したアートが、約50万ドルで売られた日
2018年10月、ニューヨークのクリスティーズで前例のない出来事が起きました。どこかぼやけた、18世紀ヨーロッパ絵画を思わせる肖像画が、$432,500で落札されたのです。買い手は匿名のコレクター。売り手はフランスのコレクティブ「Obvious」。そして、作者は――アルゴリズムでした。
「エドモン・ド・ベラミの肖像」は、人の手で描かれた作品ではありません。15,000点におよぶ歴史的肖像画を学習した敵対的生成ネットワーク(GAN)によって生み出されました。キャンバスの隅に記されたサインも、人名ではなく数式――「min max Ex[log(D(x))] + Ez[log(1 D(G(z)))]」だったのです。
美術界は真っ二つに割れた。歴史的転換点だと評価する声がある一方で、単なる話題作り、さらにはスキャンダルだと批判する声もあった。特に、オープンソースのコードが本来の開発者であるロビー・バラットへの適切なクレジットなしに使われていたことが明らかになると、議論は一層過熱した。しかし論争の行方とは無関係に、ひとつだけ確かな事実があった。AI生成アートはすでに世に出てしまったということだ。そして、この流れを元に戻すことは、もはや不可能だった。
しかし、多くの人が見落としがちなのは、2018年のあのオークションがAIアートの始まりではないということです。実は、まったく始まりでもありません。物語はそこから45年もさかのぼり、大学のコンピューターラボで幕を開けます。きっかけは、「筆だけでは物足りない」と感じ始めた一人のイギリス人画家でした。
クイック年表:
1960年代:コンピュータとアルゴリズムを用いた初期のアート実験が始まり、後のAIアートにつながる基盤が築かれる
1973: ハロルド・コーエンがAARONの開発を開始
2015: DeepDreamと初期のスタイル転送技術が話題に
2014–2018:GANsの登場で画像表現のリアリティが飛躍。AIアートがギャラリーやオークションの舞台へと進出
2021: CLIPがテキストと画像の意味理解を可能にする
2022: 拡散モデルの登場と、Midjourney / DALL·E / Stable Diffusionの普及により、AIアートが一気にメインストリームへ
2023–2025:著作権、学習データの同意、来歴(プロヴェナンス)ツール、規制をめぐる議論が本格化
偶然のパイオニア:一人の画家が生んだ、世界初のAIアーティスト
ハロルド・コーエンとAARON(1973–2016)

1968年、ハロルド・コーエンは画家として頂点にいました。ヴェネツィア・ビエンナーレではイギリス代表を務め、抽象絵画は名だたるギャラリーに展示されていました。それでも、彼の心には小さな違和感が残っていたのです。後に彼はこう振り返っています。「自分のアトリエの中よりも、外の世界のほうが、もっと面白いことが起きているのかもしれない。」
コーエンがUCサンディエゴで教鞭をとっていた頃、彼はコンピュータと出会う。それは既存の作品をデジタル化するための道具ではなかった。もっと根源的な問いだった――コンピュータそのものが、アートを生み出せるのか? 再現でも模倣でもなく、本当に創造できるのか?
その成果として生まれたのが、旧約聖書『出エジプト記』に登場するモーセの兄にちなんで名付けられた「AARON」でした。1974年にコーエンがUCバークレーで初めて公開した当初、AARONが生み出せたのは抽象的なパターンのみ。しかし、革新的だったのはそこではありません。AARONは、あらかじめ決められた指示を機械的に実行する存在ではなかったのです。コーエン自身が画家として理解していた「構図」「閉合」「形態」といった概念をルールとして組み込みつつも、その枠内でAARONは自ら判断し、作品を生成していました。
こう捉えるとわかりやすいでしょう。コーエンはAARONに視覚言語の「文法」を教えただけで、文を書いたのはAARON自身でした。
1980年代に入ると、AARONは人物や植物、室内風景など、ひと目でそれと分かるイメージを描くようになります。コーエンは、大学の研究環境で協力者とともに開発したロボット描画アームを使い、「コードが物理世界でどう描くのか」を探求しながらAARONを実際に動かしました。そうして生み出されるドローイングは、精緻で、すべてが一点もの。どれも紛れもなくAARONのスタイルでありながら、同じ作品は二つとありませんでした。
興味深いのは、コーエン自身でさえAARONが何を生み出すのかを完全には予測できなかったことです。プログラムに与えた指示の一部が、彼の想像を超える形や構造を生み出していったのです。そのマシンは、彼自身が構築した芸術システムの中に潜んでいた、まだ見ぬ可能性を次々と可視化していました。
AARONは40年以上にわたり進化を続けました。2001年版では人物や植物を描いた色彩豊かなシーンを生成し、2007年版の「Gijon」ではジャングルを思わせる風景を生み出しました。2016年にコーエンが亡くなったとき、彼が残したのは数千点の作品だけではありません。AARONが制作者の予想を超える新しい構図を生み出していたとしたら、それは「創造的」だと言えるのか――そんな根源的な問いでした。
ホイットニー美術館をはじめとする主要な美術機関が、コーエンのAARON関連作品や資料を展示しており、その存在がデジタルアート史においていかに重要かを物語っています。現在でもAARONは画像を生成し続けていますが、コーエンの死後に生み出された作品については、その真正性をめぐって議論が続いています。
AARON以前:生成アートと初期のコンピュータ実験(1960年代)
現在のようなモデルが登場するずっと前から、アーティストたちはアルゴリズムを使って視覚表現を生み出してきました。1960年代のコンピュータ・プロッターによるドローイングや、ルールに基づく「生成アート」は、AIアートの本質となる考え方を提示しています。つまり、アーティストは仕組みを設計し、その仕組みが人の手作業では生み出せない多様なバリエーションを生産する、という発想です。
静かな時代:ブーム前夜のAIアート(1980年代–2000年代)
CohenがAARONの開発に取り組む一方で、他のアーティストたちも計算による創造性の可能性を模索していました。ただし、その動きに注目していたのは、主に学術界の限られた人々にとどまっていました。
Karl Simsは、この時代の中では、少なくともデジタルアート界隈では最も知られた存在と言えるかもしれません。1980年代にMITメディアラボで活動し、その後はスーパーコンピュータ企業であるThinking Machinesに在籍。Simsは「人工進化」という手法を用いて、3Dアニメーションを制作しました。ランダムに生成した3D形状を変異させ、魅力的なものを選び、さらに進化させる——このプロセスを繰り返します。いわば、デジタルな生き物に対する自然淘汰そのものです。
1991年の「Panspermia」、1992年の「Liquid Selves」は、世界的に権威あるデジタルアートの祭典「アルス・エレクトロニカ」で最高賞を受賞しました。自然界のどこにも存在しないのに、なぜか生命感を帯びて見える——そんな有機的で催眠的な3Dアニメーション表現を切り拓いたのが、まさにシムズだったのです。
Scott Dravesは、1999年に発表した「Electric Sheep」でまったく異なるアプローチを取りました。スクリーンセーバーです。そう、覚えていますよね? ただし、これは“学習する”スクリーンセーバー。世界中の数千台のコンピュータに分散して動作し、「sheep」と呼ばれる進化するフラクタルアニメーションを生成します。鑑賞者が気に入ったパターンに投票すると、システムはそれらをもとに新しいパターンを“繁殖”させていきます。実は今も稼働中です。electricsheep.org にアクセスすれば、実際に見ることができます。
この時代、「生成アート(Generative Art)」という言葉が広く使われるようになりました。アーティストはコードでルールやパラメータを定義し、その枠組みの中でアルゴリズムに作品を生み出させていました。2001年には、アーティストのために設計されたプログラミング言語「Processing」が登場し、こうした制作手法がより身近なものになります。
ただ、多くの人にとって、これらはまだ「AI」とは感じられませんでした。確かに先進的でクールなデジタルアートではありましたが、知性を持っているようには見えなかったのです。自分が何を生み出しているのかを理解しているわけではなく、どれだけ複雑でも、あくまでルールに従って動いているだけでした。
しかし、それはまもなく変わろうとしていた。
ディープラーニングがすべてを変えた(2012–2015)
2010年代初頭、AIアートを取り巻く状況は大きく転換しました。決定的だったのは、次の3つの要素が同時に重なったことです。
まず、GPU(グラフィックス処理ユニット)が飛躍的に高性能化し、巨大なニューラルネットワークの学習が可能になりました。皮肉なことに、もともとゲーム向けに設計されたチップが、AIの大きなブレイクスルーを支えたのです。
次に、大規模データセットが使えるようになりました。2009年に公開されたImageNetには、数百万枚ものラベル付き画像が収録されています。これにより、ニューラルネットワークは初めて、パターンを本格的に学習できるだけの十分な実例を手にしたのです。
第三に、ディープラーニングアルゴリズムが飛躍的に進化しました。2012年、ディープラーニングモデルがImageNetで知られる画像認識ベンチマークを大幅に更新し、従来のコンピュータビジョン手法を圧倒。ニューラルネットワークが大規模に視覚パターンを学習できることを示しました。研究者たちは気づきます。ネットワークを十分に深く(多層化)し、十分なデータと計算資源を与えれば、驚くほど「知的」に見える振る舞いを始めるのだ、と。
アートの世界に与えた影響は、計り知れないものでした。
DeepDreamが注目を集めた瞬間(2015年)
2015年6月、GoogleのエンジニアであるAlexander Mordvintsevは、少し風変わりな成果を公開しました。彼はニューラルネットワークがどのように物体を認識しているのかを可視化する研究に取り組んでいました。発想はこうです。犬を認識するよう学習したネットワークに対し、そのプロセスを逆転させ、画像の中に見つけた「犬っぽい」パターンをあえて強調させたら、いったい何が起こるのか?
生まれたビジュアルは、まさにトリップ体験。サイケデリックで、幻覚的ですらありました。雲の写真を入力すると、ネットワークはそこかしこに犬の顔や目、建築的な形状を見出し、それらを誇張してシュールな風景へと変えていったのです。アートコミュニティは一気に熱狂しました。
Googleはこの技術をDeepDream(正式名称は「Inceptionism」)と名付けました。発表からわずか数週間で、アーティストたちはDeepDream作品のギャラリーを次々と公開。無数の目や渦巻く有機的な模様に覆われた独特のビジュアルは、ひとつの美学として確立されました。今でも、DeepDreamの画像は一目見ただけでそれと分かります。
文化的に重要だったのは、ビジュアルそのものだけではありませんでした。そこにあったのは、「ニューラルネットワークが世界を見ているとしたら、こう見えている」という気づきです。人間と同じものを見ているわけではない。見ているのは、パターンや相関、統計的な関係性。そしてそれらを可視化すると、まるで熱にうなされた夢のような光景になるのです。
とにかく奇妙。でも、そこが人々の心を掴んだ。
スタイル転写:ニューラルネットワークがアーティストになる(2015–2016)
同じ頃、研究者たちはニューラルネットワークを使った「スタイル転送」を実現しました。1枚の画像の画風を別の画像に適用する技術です。自分の写真をゴッホの『星月夜』風にしてみたい? それも数秒で完成します。
技術論文自体は難解でした(Gatys et al., 2015)が、それを実装したアプリは次々と登場しました。2016年にはPrismaがバイラルヒットに。スマートフォンさえあれば、誰もが名画のような「アート」を作れる時代が一気に広がったのです。
批評家からは「新しい芸術を生み出しているというより、アルゴリズムによる模倣に過ぎない」という指摘もありました。しかし、ニューラルネットワークが芸術的なスタイルを理解し、再現できるレベルに達していることを示した点は画期的でした。
GANs:ブレイクスルーを起こした技術(2014–2020)
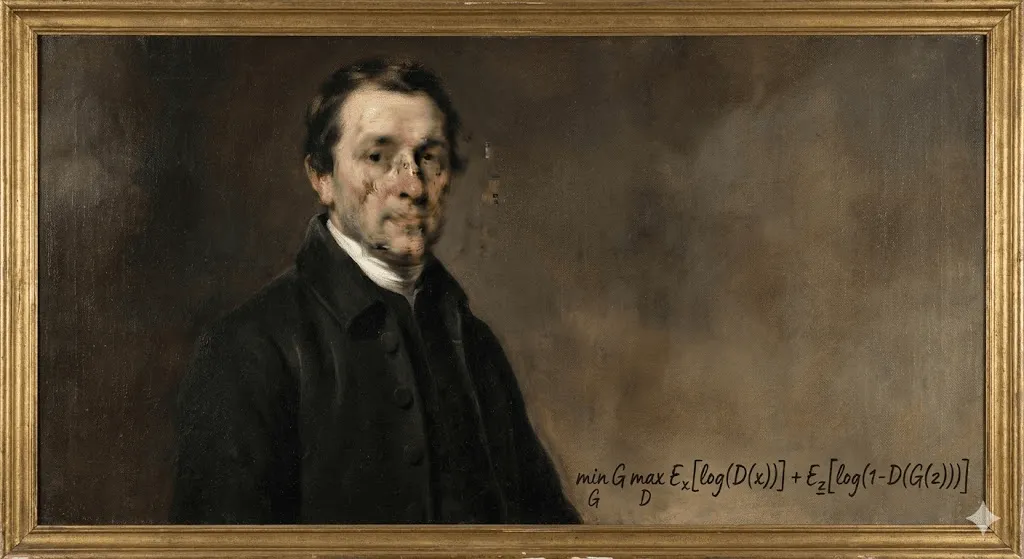
アーティストにとってGANが重要だったのは、「スタイル」をデータから学習できるようになり、すべてのルールを手作業でコード化しなくても、ひとつの視覚的な宇宙を探索できるようになった点にあります。
数式なしでわかるGANの仕組み
2014年、モントリオール大学の博士課程に在籍していた Ian Goodfellow が、後に機械学習分野で最も引用される論文のひとつとなる「Generative Adversarial Networks(GAN)」を発表しました。ディープラーニングの創始者の一人である Yann LeCun は、GANを「過去10年間で最も興味深い機械学習のアイデア」と評しています。
基本的な考え方はこうです。2つのニューラルネットワークが、互いに競い合うゲームをしている様子を想像してみてください。
Network 1(Generator): 本物に見える偽の画像を生成しようとします。
Network 2(Discriminator/識別器): 偽の画像と本物の画像を見分けようとします。
最初、Generatorはランダムなノイズしか生み出せず、出来は散々です。Discriminatorは偽物を簡単に見抜きます。ですが、ここが肝心なポイント。Generatorは失敗から学び、Discriminatorをだますように調整していきます。一方でDiscriminatorも見抜く精度を高める。Generatorはまた適応する——このやり取りが、何千回と繰り返されるのです。
やがて生成器(Generator)の精度が飛躍的に高まり、識別器(Discriminator)ですら本物と偽物を安定して見分けられなくなります。この段階に到達すると、ニューラルネットワークはゼロからでもリアルで説得力のある画像を生み出せるようになります。
大きなブレイクスルーは、GANがすべての出力に人手でラベル付けされた学習データを必要としない点です。顔や風景など、学習した対象の背後にある統計的分布そのものを捉え、そこから無限のバリエーションを生み出せるようになりました。
奇妙な顔から、説得力のあるアートへ(2015–2018)
初期のGANの成果は……控えめに言っても「実験的」でした。2015年前後に話題になった、歪んでいて不気味、いわゆる“悪夢級”のAI生成顔画像を覚えている方もいるでしょう。あれこそが初期GANの姿です。研究者たちはコンセプト実証として公開しましたが、瞬く間にミームとして拡散されていきました。
しかし、技術の進化は急速でした。2017年には、NVIDIAのProgressive GANが、写真と見分けがつかない1024×1024の顔画像を生成できるようになります。続く2018年にはStyleGANが登場し、解像度をさらに向上させるとともに、画像のさまざまな要素を自在にコントロールできるようになりました。
アーティストたちも実験を始めました。ドイツ人アーティストのMario Klingemannは、2つのスクリーンに無限に生成される肖像が映し出されるインスタレーション作品「Memories of Passersby I」(2018)を制作。記憶の断片のように流れ続け、同じものは二度と現れません。本作はサザビーズで4万ポンドで落札されました。
Helena Sarinは、写真ではなく自身のドローイングを学習データにGANを訓練するという、異なるアプローチを取りました。これにより、AIの生成力を活かしながら、作家としてのコントロールをしっかり保つことができたのです。彼女の「AI Candy Store」シリーズは、ひと目でAIとわかる独自の美学を持ちながら、彼女自身のスタイルが自然に溶け込んでいます。
Robbie Barratは当時まだ高校生でしたが、古典絵画を学習させたGANをトレーニングし、そのコードをGitHubで公開しました。(このコードは後にアート集団Obviousがクリスティーズでの落札作品に使用し、作者の帰属や芸術的クレジットをめぐる議論を引き起こすことになります。)
The Next Rembrandt(2016年)
Obviousのオークションで話題になる以前に、「The Next Rembrandt」(2016)というプロジェクトがありました。これはING銀行とオランダの複数の研究機関によるマーケティング企画で、レンブラントの絵画346点を解析し、その画風をアルゴリズムに学習させることで、「新たなレンブラント」の肖像画を生成したものです。
技術的にはGANではありませんでしたが、発想は近いものでした――AIは特定のアーティストの作風を再現できるのか、という問いです。このプロジェクトは大きなメディア注目を集め、批評家からは技術的な成果として評価される一方で、果たしてそれはアートなのか、それとも高度に洗練されたパスティーシュ(模倣)にすぎないのか、という議論も巻き起こりました。
この動きは、今なお答えの出ない問いを私たちに突きつけました。特定のアーティストの作品を学習させることは、敬意あるオマージュなのか、それとも計算による流用なのか。インスピレーションは、どこから「盗用」へと変わるのでしょうか。
大爆発:AIアートがメインストリームになった瞬間(2022–現在)
CLIP:テキストと画像の関係をAIに理解させる(2021年)
次の大きなブレイクスルーは、2021年1月にOpenAIが発表したCLIP(Contrastive Language Image Pre-training)でした。技術的な仕組みは非常に高度ですが、そのインパクトは明快です。CLIPは「テキストと画像の意味的な関係」を理解できるようになったのです。
従来のシステムは、「これは猫」「これは犬」といったラベル付きデータが必要でした。一方CLIPは、インターネット上から収集された4億組の画像とテキストのペアで学習。言葉と視覚的特徴がどのように結びつくかを理解し、テキストと画像を同じ「空間」で比較できるようになりました。
なぜ重要だったのか:CLIPを生成モデルと組み合わせることで、「テキストから画像を生成する」ことが一気に現実になりました。「馬に乗った宇宙飛行士」と入力すれば、システムはそのイメージを理解し、絵として描き出せるようになったのです。
アーティストたちはCLIPをいち早く自分たちのワークフローに取り入れた。GANなどの生成器と組み合わせることで、言語によって画像生成を導けるようになった。扱いはぎこちなかったが、確かに機能していた。
2022年の革命:DALL E 2、Midjourney、Stable Diffusion

そして2022年、すべてが一変した。
DALL E 2(OpenAI、2022年4月)は、CLIPと拡散モデル(詳しくは後述)を組み合わせ、テキストから高品質で一貫性のある画像を生成しました。初期アクセスは一部のアーティストや研究者に限定され、ウェイトリストは100万人を超える規模に膨張。OpenAIが公開した作例は、驚くほど創造的で、整合性があり、多くが美しいものでした。
Midjourney(Midjourney Inc., 2022年7月)は、コミュニティ主導・Discordベースという独自路線を選び、美しさや表現力にフォーカスしました。絵画的でドラマチック、どこか幻想的——そんな強い個性を短期間で確立。多くのアーティストが集い、Discordサーバーはオンライン屈指の活発なクリエイティブコミュニティへと成長しました。
Stable Diffusion(Stability AI、2022年8月)は、アクセシビリティの面で大きな転換点となりました。Web限定・招待制だったDALL·E 2や、サブスクリプション型のMidjourneyとは異なり、Stable Diffusionはオープンソース。誰でもダウンロードしてローカル環境で動かし、自由にカスタマイズできるようになったのです。
わずか数か月のうちに、エコシステム全体が一気に立ち上がった。Webインターフェース、モバイルアプリ、Photoshop用プラグイン、特定の画風に特化して学習された数百ものカスタムモデル――その広がりは、前例のないスピードと規模だった。
2022年後半になると、SNSはAIアートであふれ返りました。「プロンプトエンジニアリング」という言葉がスキルとして語られ、より良い結果を出すためのコツが盛んに共有されるようになります。一方で、これはアートを民主化するのか、それとも破壊するのか――そんな議論が絶え間なく巻き起こりました。
拡散モデル:魔法の裏側を支える技術
では、拡散モデル(Diffusion Model)とは何でしょうか?実は物理学の考え方に着想を得たもので、粒子が媒体の中を拡散していく仕組みをモデル化したものです。
学習プロセス:
- 実際の画像を用意する
- 完全にランダムなノイズになるまで、段階的にノイズを加える(フォワード拡散)
- この過程を逆にたどり、ノイズを取り除くようニューラルネットワークを学習させる(逆拡散)
生成プロセス:まずはランダムノイズから始め、逆拡散プロセスを段階的に適用することで、最終的に意味のある一枚の画像が生成されます。CLIPによるテキスト条件付けが、どのようなイメージが立ち上がるかを導きます。
この用途で拡散モデルがGANを上回った理由は、学習が安定していて扱いやすく、テキストプロンプトへの追従性が高いからです。GANも一部の用途では使われ続けていますが、2022年の爆発的な広がりを牽引したのは拡散モデルでした。
技術的な補足:中核となる論文は Ho ら(2020)の「Denoising Diffusion Probabilistic Models」です。もっとさかのぼると、Sohl-Dickstein ら(2015)の研究が基礎を築いています。仕組みを本気で理解したいなら、これらの論文が出発点になりますが、数式が多い点は覚悟しておいてください。
数字で見る
- 2023年初頭には、これらのツールは数百万人規模にまで普及し、AI生成画像がSNSを席巻するようになりました。
- DALL·E:300万人以上のユーザー(ウェイトリスト解消)
- Stable Diffusion:正確な数は不明(オープンソースかつ分散型)だが、GitHubの統計からは数百万人規模と推定
人々は数億枚規模のAI画像を生み出し、AIアートを提供するビジネスが次々と誕生しました。ストックフォトサイトは対応方針の策定に追われ、従来のアーティストたちは「AIアーティスト」という職業名が現実のものになる様子を、戸惑いとともに見つめることになりました。
もうひとつのAIアート:学術分野での応用
世間がテキストから画像生成に注目する一方で、研究者たちはAIを活用し、美術史研究を静かに革新してきました。このAIアート史の側面はあまり語られませんが、学術的な意義はむしろ大きいと言えるでしょう。
作者推定と分析のためのコンピュータビジョン
美術史において、作品の作者を特定する「アトリビューション」は常に難題でした。いま、その課題にニューラルネットワークが新たな光を当てています。
Rutgers Art & AI Lab(Ahmed Elgammal 主導)は、筆致や構図、スタイルの指標を解析し、作家の特定や贋作の検出を行うシステムを開発しました。2017年には、管理されたテスト環境において、作者不明の作品の作家を90%超の精度で正しく特定しています。
失われた作品の再構築:アーティストの既存作品を学習したニューラルネットワークにより、失われたり損傷した作品を「あり得た姿」として再構築する試みが行われています。最も有名な例が、1715年に損傷を受けたレンブラントの《夜警(The Night Watch)》をAIで外挿し、切り取られた部分がどのような構図だった可能性があるかを可視化したプロジェクトです。(美術史家の間では正確性をめぐる議論がありますが、これは復元ではなく、根拠に基づく推定です。)
ヘルクラネウムの巻物:2023年、コンピュータ科学者たちは機械学習を用いて、西暦79年のヴェスヴィオ火山噴火で炭化した古代の巻物から文字を読み取ることに成功しました。巻物は非常にもろく、物理的に広げることはできませんが、CTスキャンと訓練されたニューラルネットワークを組み合わせることで、インクの痕跡を検出できたのです。AIによって、約2000年ぶりに古代のテキストを読む道が開かれました。(出典:Nature, 2023)
美術館とAI
主要な美術館や文化機関も、AIを用いた実験的で興味深い取り組みを行ってきました。
メトロポリタン美術館は、AIを活用したコレクション可視化に取り組み、巨大な美術館アーカイブを「潜在空間(latent space)」へとマッピングすることで、作品同士の思いがけない関係性を浮かび上がらせました。:メトロポリタン美術館、MIT、そしてアーティストのRefik Anadolによるコラボレーションです。メトロポリタン美術館が所蔵する全コレクション(37万5,000点以上の作品)をニューラルネットワークに学習させ、異なる作品カテゴリのあいだに広がる概念的な領域=「潜在空間」を視覚化しました。その結果、古代ペルシャの水差しと19世紀の花瓶が、人間のキュレーターでは気づきにくい形で概念的に近接しているなど、予想外のつながりが明らかになりました。
MoMAにおけるAI実験:Refik Anadolによる「Unsupervised」(2022–2023)は、MoMAのコレクションを学習した機械学習モデルを用い、ロビー空間に流動的で夢のような映像投影を生み出しました。美術界の反応は分かれ、単なる仕掛けだと見る声がある一方で、ミュージアムアーカイブを体験する新しい方法だと評価する意見もありました。
LMUミュンヘンの「Transparent AI」プロジェクト:フーベルトゥス・コーレ教授が率いるこの研究は、美術史のためのAIツールを開発し、その判断プロセスを人間にわかる形で説明できるようにすることを目的としています。一般的なニューラルネットワークは「ブラックボックス」と呼ばれ、結論は得られても、その理由は見えません。本プロジェクトでは、AIの意思決定を可視化することで、学術的な信頼性と受容性を高めています。作品同士の視覚的な類似性を見つけ出すだけでなく、どの要素が判断の根拠になったのかを説明できるモデルの学習が進められています。
これらのツールは新しい作品を生み出すわけではありません。しかし、私たちが美術史を研究し、理解する方法そのものを変えています。その影響は、どんな生成画像よりも長く残るかもしれません。
論争の核心:著作権、倫理、そして創造性の未来

ここから議論が一気に白熱します。技術的な成果は目を見張るものがありますが、倫理的な問題は……そう単純ではありません。
著作権をめぐる攻防
核心的な問題は、AIアートモデルがインターネットから収集された数十億枚もの画像で学習していることです。その多くは著作権で保護されています。アーティストに許可は求められず、報酬も支払われていません。そして今や、彼らの作品で訓練されたシステムが、わずか数秒で「その人の作風」の画像を生成できてしまいます。
主要な訴訟の提起:
Getty Images vs. Stability AI(2023年1月):Getty Imagesは、Stable Diffusionの学習において自社の画像が数百万点規模で無断スクレイピングされたと主張。生成された一部の画像には、出所を示すGettyのウォーターマークの一部が残っていることが確認されたとしています。
アーティストによる集団訴訟(Midjourney/Stable Diffusion/DeviantArt)(2023年1月):サラ・アンダーセン、ケリー・マッカーナン、カーラ・オルティスらのアーティストが主導し、大規模な著作権侵害を訴えたもの。2024年末時点でも係争中で、法的な行方については専門家の間でも見解が分かれている。
法的な論点はここにあります。著作権で保護された画像を学習に使うことは、既存の作品を研究して学ぶ学生と同じ「フェアユース」なのか。それとも、許可なく商業的に利用する「著作権侵害」なのか。
司法判断はまだ出ていません。その結論が、業界全体の行方を左右します。
アーティストの反応:対抗の動き
アーティストは裁判の行方を待つのではなく、技術的な対抗策を打ち出し始めています。
Glaze(シカゴ大学、2023年):人には見分けられないレベルでデジタルアートを微細に変化させ、AIの学習データを“汚染”するソフトウェア。Glaze処理された画像でモデルを学習させると、生成結果が歪む。識別するのではなく、破壊するタイプのアクティブ・ウォーターマークと言える。
Nightshade(シカゴ大学、2023年):Glazeよりもさらに攻撃的な手法。Nightshadeを施した画像を守るだけでなく、モデル全体の性能そのものを低下させます。たとえば、実際は猫の画像なのに「dog」とラベル付けされたNightshade画像を十分な数アップロードすると、モデルは次第に「犬とは何か」を正しく認識できなくなっていきます。
これらのツールをめぐっては賛否が分かれています。AI研究者は「有害な妨害行為」だと批判し、アーティストは「自己防衛」だと捉える。どちらにも一理があります。
「Do Not Train(学習禁止)」提案:アーティストや支援者は、作品をAI学習の対象外と示すメタデータタグの導入を提案してきました。実際にDeviantArtやShutterstockなど一部のプラットフォームではオプトアウトの仕組みが実装されています。しかし、実効性は限定的です。AI企業はそのタグを無視することもでき、実際にそうしているケースも少なくありません。
創造性をめぐる議論
著作権の議論を超えて、より根源的な問いがあります。AIが生み出した作品は、本当に「アート」なのでしょうか?
当てはまらない主張:
- 人間ならではの意図や感情の深みが欠けている
- 既存作品の組み合わせに過ぎず、本当の意味で新しいものを生み出していない
- 特別なスキルが不要で、誰でもプロンプトを入力できてしまう
- 人間の創造性や試行錯誤といった、芸術の価値そのものを揺るがす
該当するとする主張:
- ツールが芸術の価値を下げることはない(カメラが絵画を終わらせなかったのと同じ)
- プロンプト設計や作品のキュレーション自体が創造的なスキル
- 人間がAIを導き、創造の意思決定を行う
- これまで不可能だった新しい表現を可能にする
私の考え: 論点がずれています。これは、1850年に「写真は芸術か?」と議論しているようなもの。AIがアートを生み出せることは、もう私たちは目にしてきました。本当に問うべきなのはそこではありません。人間の創造性と機械の創造性を、どんな関係性にしたいのか。誰が恩恵を受けるのか。何が失われ、そして何が新しく得られるのか。
雇用が置き換わる現実
これは机上の空論ではありません。実際に仕事を失っている人がいます。
Concept Art Associationが2023年に実施した調査では、次の点が明らかになりました:
- コンセプトアーティストの73%が、仕事の機会が減ったと回答
- 62%が、AIによってフリーランス案件を失った
- エントリーレベルの職種が最も速いペースで消失
企業は、コンセプトのたたき台やストーリーボード、背景デザインといった、これまでキャリア初期のアーティストが担ってきた工程にAIを活用し始めています。擁護派は「デジタルツールが従来技法を置き換えてきたのと同じだ」と主張しますが、その進行スピードは前例がなく、影響を受けるアーティストが怒りを覚えるのも無理はありません。
一方で、新しい役割も生まれています。AIアートディレクター、プロンプトエンジニア、AIと人が協働するハイブリッド制作のスペシャリストなどです。これらが失われた職を1対1で補うのかどうかは、まだ見極めが必要でしょう。
バイアスの課題
AIアートモデルは、学習データに含まれる偏りをそのまま受け継ぎます。「CEO」と指示すると白人男性が出やすく、「看護師」では女性が多い。「美しい人」を求めると、若く、白人で、いわゆる“標準的な美”の顔立ちに強く偏ります。
GoogleのGeminiは2024年、歴史画像の多様性を高める調整を行いましたが、結果的に過剰補正となり、歴史的正確性・表現の公平性・安全性をどう両立させるかをめぐって大きな議論を呼びました。とりわけ、18世紀ヨーロッパ貴族の描写をめぐる違和感が問題視され、AIモデルを責任ある形でチューニングする難しさが浮き彫りになりました。Googleはこれを受けて謝罪し、該当機能を一時的に停止しました。この出来事は、歴史の正確さと多様な表現のバランスを取ることがいかに困難かを示しています。
バイアスは、人口統計だけの問題ではありません。AIアートは、洗練されていて商業的、いわゆる「きれい」な美意識に寄りがちです。実験的だったり、アヴァンギャルドだったり、あえて「醜さ」を追求する表現は、学習データ自体が少なく評価もされにくいため、アウトプットにも現れにくいのが現状です。その意味で、AIは技術的には革新的であっても、芸術的には保守的になりうるのです。
現在(2024–2025)
現在の状況
2024年末から2025年初頭にかけて、AIアートの分野は成熟期に入りつつある一方で、依然として変化と議論の渦中にあります。
DALL E 3(ChatGPT Plusに統合)により、プロンプト理解が飛躍的に進化。やり取りしながら要望を伝えられ、ニュアンスまでくみ取った生成が可能になりました。
Midjourney V6は、美的クオリティをさらに引き上げ、テキスト表現(依然として完璧ではないものの)の改善や、スタイルのコントロール性向上を実現しました。
Stable Diffusion XL 以降の世界も進化は止まらず、オープンソースコミュニティによって、アニメ調からフォトリアル、特定のアートスタイルまで、多様な表現に特化したモデルが次々と生まれています。
Adobe Fireflyは、Adobe Stockの画像とパブリックドメイン素材のみを学習データに使用した「責任あるAI」を掲げる生成AIです。商用利用を前提としたライセンス設計が特徴で、Stable Diffusionに比べると表現の自由度は控えめですが、ビジネス用途では安心して使える点が強みです。
動画生成:次なるフロンティア
テキストから画像を生成するだけでは、まだ序章にすぎません。2024年には、AIによる動画生成が本格的な進化を遂げました。
Runway Gen 2 と Pika は、テキストや画像から短い動画クリップを生成できます。品質はまだばらつきがあり、物体が不自然に変形したり物理挙動が奇妙になることもありますが、毎月着実に改善しています。
OpenAI's Sora(2024年2月発表、限定公開)は、最長1分に及ぶフォトリアルで一貫性のある動画生成を実現した。公開されたデモ映像は衝撃的で、多くの人を驚かせた一方、テキストからここまで説得力のある動画を生成できる時代が来たことで、ディープフェイクはすでに深刻な問題になりつつある、という不安も広く意識されるようになった。
3D、そしてその先へ
AIアートは、2D画像の枠を超えて進化しています:
Point E と Shap E(OpenAI)は、テキストプロンプトから3Dモデルを生成する技術です。現時点ではクオリティに制約はあるものの、今後の進化の方向性は明確に見えています。
NeRF(Neural Radiance Fields)は、2D画像から3Dシーンを生成できる技術で、映画制作、ゲーム開発、建築ビジュアライゼーションまで幅広い分野での活用が期待されています。
音楽・テキスト・マルチモーダル
AIによる音楽生成(Suno、Udio)は、2024年に「実用レベル」に到達しました。ミュージシャンを置き換えたわけではありませんが、機能的なBGMをより手軽に、低コストで制作できるようになっています。
マルチモーダルモデル(視覚対応のGPT‑4やGemini)は、画像を理解・分析し、その内容をテキスト化し、さらにそのテキストから新たな画像を生成できます。テキストAIと画像AIの境界は、いま急速に溶け合いつつあります。
これから何が起こる?──予測と可能性
短期(2025–2027)
可能性が高い:
- 動画生成が実用レベルに到達し、一般利用が一気に進む
- 同一キャラクター(同一人物)を複数画像で一貫して生成できるようになる
- 進行中の訴訟を背景に、著作権に関する法的整理が進展
- 小規模プレイヤーの買収・撤退が進み、業界再編が加速
- 反発も強まり、一部のプラットフォームやクライアントではAIアートが禁止される動きが広がる
可能なこと:
- ビデオ通話や配信中に、リアルタイムで動画を生成
- AIアートが、プロのクリエイティブワークフローにおける標準ツールへ
- 「人間制作認証(Certified Human Made)」アートが、プレミアムカテゴリーとして台頭
- 単発のインスタレーションを超えた、AIアート史を扱う大規模美術館展の開催
中期(2027–2030)
仮説的だが、十分にあり得る:
- テキスト・画像・動画・3D・音声生成が、単一のモデルに統合される
- 個々の作家のスタイルで学習した、パーソナライズドAIモデルが一般化する
- AR/VRとの統合により、ヘッドセットを通して物理空間にAIアートを展開できるようになる
- 学習データを巡る法的枠組みが(紆余曲折を経ながら)整備される
- AI以前の様式の延長ではない、AIネイティブな新しい芸術運動が生まれる
長期的視点:本質的な問い
AIは人間の創造性を超えるのか?——その問い自体がズレています。AIと人間の創造性は、そもそも別物なのです。
人間のアーティストは時代遅れになるのか?その可能性は低いでしょう。AIが手軽なコンテンツで市場を埋め尽くすほど、むしろ「人間ならでは」の表現への需要は高まっていくはずです。
AI生成アートの著作権は誰のものか?——いまも各国の法廷で争われているテーマです。現行の米国著作権法では「人間の著作」がないため権利は認められていませんが、今後見直される可能性があります。
AIの学習に使われた作品のクリエイターに、どう報酬を還元すべきか。これは文字どおり、数十億ドル規模の大きな問いです。考えられている案としては、ライセンス料の支払い、利用ごとのマイクロペイメント、音楽業界のような強制ライセンス制度などがありますが、現時点で大規模に実装されている仕組みはまだありません。
AIフリーゾーンは必要か。児童書や記念碑、法的証拠など、特定の用途は人間の創作者に限定すべきだという意見がある。一方で、それはルダイト主義だと批判する声も。議論は続いている。
歴史が教えてくれること
50年以上にわたるAIアートの歴史を振り返ると、いくつかの共通した流れが見えてきます。
- ツールは世代ごとに民主化されてきました。AARONには高度なプログラミング知識が必要で、GANには機械学習の理解が欠かせません。いまのツールに必要なのは、Discordアカウントくらい。時代が進むほど、誰でも使えるようになっています。
- 初期の熱狂は、いつも現実を上回ります。新しい技術が登場するたびに「芸術は終わった」という声が上がる。でも、芸術は終わりません。形を変えて適応してきました。
- 法制度や倫理は、常に技術の後追いです。私たちは今も、3年前に実用化された技術の著作権を議論しています。テクノロジーは速く進み、法律はゆっくり動く。
- 仕事が奪われるという懸念は、多くの場合正しいですが、それだけでは不十分です。確かに消える仕事はあります。しかし同時に、新しい仕事も生まれる。その移行期は、とくに当事者にとって痛みを伴います。
- 芸術は生き残ります。写真は絵画を殺さなかった。デジタルツールも伝統的な表現を消し去らなかった。AIも人間の創造性を殺しません。ただし、「どう作るか」「なぜ作るか」「何を作るか」は、大きく変わっていくでしょう。
結論:次の章を描く
1973年にハロルド・コーエンが粘り強くプログラミングしていた時代から、いまや何百万人もの人が数秒で画像を生成する時代へ。AIアートの歴史とは、人間の創造性と計算能力の関係がどのように変化してきたのかを描く物語にほかなりません。
いま私たちが向き合っている問いは、主に技術的なものではありません。技術はすでに機能しており、しかも急速に進化しています。問われているのは、人間の側の問題です。
- AIが人間の創造性を置き換えるのではなく、拡張する存在であるために、私たちは何ができるのか?
- AIを可能にしてきたアーティストの作品に、どのように正当な対価を支払うべきなのか?
- この新しい創作のフィールドに、誰が参加できるのか?
- 創造性の中で、あえて「人間ならでは」として残したいものは何か?
- 技術の移行期において、アーティストのキャリアや生計をどう守っていくのか?
これらの問いに、簡単な答えはありません。アーティスト、技術者、企業、政策立案者、そして社会全体が対話と調整を重ねていく必要があります。AIアートの歴史は、まだ終わっていません。私たちは今まさに、その最も重要な章の渦中にいるのです。
確かなのは、AIを無視しても消えてはくれないということ。そして、現実的な課題が存在しないふりをしても何も解決しないということです。これから必要なのは、向き合う姿勢。課題には正直に、可能性には開かれた心で、そして公平性を粘り強く求めていくことです。
AIは本当に「創造的」なのか──もしかすると、その問い自体が少しずれているのかもしれません。創造性は、あるかないかの二択で測れるものではありません。連続したスペクトラムの中にあり、協働の中で生まれ、予期せぬ組み合わせから立ち上がるものです。AIアートの最初の50年が示してきたのは、創造性が私たちの想像以上に広く、そして不思議なものだということ。そして人間は、良くも悪くも、その創造性をAIと分かち合おうとし続けているようです。
次の章は、まさにいま書き進められています。思慮をもって関わってください。