AI艺术完整发展史:从 AARON 到 Midjourney(1973–2025)
最后更新: 2026-01-22 18:07:34

人工智能如何从学术探索走向艺术革命,以及这为何重要
本指南带你回顾 AI 艺术从早期基于规则的系统,到如今扩散模型的发展历程,清晰呈现每一次技术突破如何不断拓展艺术创作的边界与可能性。
当一件由机器人创作的艺术品拍出近50万美元
2018 年 10 月,纽约佳士得拍卖行发生了一件前所未有的事。一幅略显模糊、带着 18 世纪欧洲绘画气息的肖像作品,以 43.25 万美元成交。买家是谁?匿名收藏家。卖家是谁?法国艺术团体 Obvious。那艺术家呢?不是人类,而是一段算法。
《埃德蒙·德·贝拉米肖像》并非出自人类之手,而是由生成对抗网络(GAN)创作完成。这个模型在 15,000 幅历史肖像画的数据上进行训练。画作角落的“签名”也不是艺术家的名字,而是一段数学公式:“min max Ex[log(D(x))] + Ez[log(1 D(G(z)))].”
艺术界一时间分成了两派。有人认为这是划时代的转折点;也有人斥之为噱头,甚至是丑闻——尤其是在曝出该团队使用了开源代码,却未对原始开发者 Robbie Barrat 进行恰当署名之后。但无论争议如何,有一点已经不可逆转:AI 生成艺术正式登上舞台,这一次,瓶中的精灵再也回不去了。
但大多数人并不知道:2018 年那场拍卖并不是 AI 艺术的起点,甚至相去甚远。真正的故事要追溯到 45 年前——在一间大学计算机实验室里,一位英国画家觉得,画笔已经不够有挑战性了。
快速时间线:
1960s:早期计算机艺术与算法艺术实验为后续发展奠定基础
1973:Harold Cohen 启动 AARON
2015: DeepDream 与早期风格迁移技术在网络上爆火
2014–2018:GANs 推动图像真实感飞跃,AI艺术开始走进画廊与拍卖市场
2021:CLIP 打通文字与图像的理解能力
2022:扩散模型兴起,Midjourney / DALL·E / Stable Diffusion 将 AI 绘画推向大众
2023–2025:版权归属、数据集授权、作品溯源工具与监管议题持续升温
意外的先驱:一位画家如何创造了第一个 AI 艺术家
哈罗德·科恩与 AARON(1973–2016)

1968 年,Harold Cohen 正值创作巅峰。他曾代表英国参加威尼斯双年展,抽象画作在多家知名画廊展出。但他内心始终有一丝不安。正如他后来回忆的那样:“也许,工作室之外,正在发生着更有意思的事情。”
科恩在加州大学圣地亚哥分校任教期间接触到了计算机。但他并未把计算机当作数字化既有作品的工具,而是提出了一个更根本的问题:计算机本身,是否能够创造艺术?不是复刻,不是模仿,而是真正地创造?
最终诞生的是 AARON,这个名字部分取自《出埃及记》中摩西的兄弟亚伦。1974 年,科恩在加州大学伯克利分校首次展示它时,AARON 只能生成抽象图案。但真正革命性的地方在于:它并不是简单地执行预设指令。科恩将自己作为画家所理解的构图、封闭性和形式等规则编写进系统,而在这些规则框架内,AARON 能够自行做出创作决策。
可以这样理解:Cohen 教会了 AARON 视觉语言的“语法”,而真正写出句子的,是 AARON 自己。
到了 20 世纪 80 年代,AARON 已经能够创作出清晰可辨的图像——人物、植物、室内场景一应俱全。Cohen 会让它通过一只机器人绘图臂“自由发挥”(这只机械臂是在大学研究环境中与合作者共同打造的,用于探索代码如何在现实世界中“作画”),由此生成极其精细的绘画作品。每一幅都是独一无二的;风格一眼就能认出是 AARON,却又彼此不同。
令人着迷的是,科恩始终无法完全预判 AARON 会创作出什么。他发现,一些编程指令竟然生成了他从未设想过的形态。机器向他展示了他自己的艺术体系中那些此前未被看见的可能性。
AARON 持续演化了 40 多年。2001 年版本已经能够生成色彩丰富的人物与植物场景;2007 年的版本(“Gijon”)则创作出类似丛林的风景画。2016 年科恩去世时,他留下的不只是数千件作品,还有一个影响深远的问题:当 AARON 能够以全新的构图“惊艳”其创造者时,它是否已经具备了创造力?
包括惠特尼美术馆在内的多家重要艺术机构都曾展出科恩(Cohen)与 AARON 相关的作品和文献,凸显了其在数字艺术史中的重要地位。时至今日,你仍然可以看到 AARON 持续生成图像的作品,不过在科恩去世之后生成的内容,至今仍被认为在艺术真实性上存在争议。
AARON 之前:生成艺术与早期计算机实验(1960 年代)
在当今这些模型出现之前,艺术家早已开始用算法来生成视觉形式。20 世纪 60 年代的计算机绘图仪作品和基于规则的「生成艺术」,首次提出了一个至今仍定义着 AI 艺术的核心理念:艺术家不再直接重复绘制,而是设计一套系统,由系统自行生成超越人工重复的多样化结果。
喧嚣之前的静默年代:炒作浪潮前的 AI 艺术(20世纪80年代–2000年代)
在科恩开发 AARON 的同时,其他艺术家也在探索计算创意,但学术圈之外几乎无人察觉。
Karl Sims 或许是这一时期在数字艺术圈里最接近“家喻户晓”的名字。20 世纪 80 年代,他在 MIT 媒体实验室工作,后来加入了超算公司 Thinking Machines。Sims 利用“人工进化”的理念创作 3D 动画:先生成随机的三维形态,让它们发生变异,从中挑选有趣的结果,再不断重复这一过程。本质上,这就是为数字生命体打造的一套自然选择机制。
他在1991年的作品《Panspermia》和1992年的《Liquid Selves》在享有盛誉的数字艺术节 Ars Electronica 上斩获最高奖项。那些催眠般、充满有机感的 3D 动画——看起来并不完全像自然界中的任何事物,却又仿佛拥有生命——正是 Sims 所开创并奠定的美学风格。
Scott Draves 则通过《Electric Sheep》(1999)走了一条完全不同的路。它是一个屏幕保护程序——还记得这玩意儿吗?——但关键在于,它会“学习”。这个系统分布在成千上万台电脑上,生成不断演化的分形动画,被称为“sheep”。观众可以为自己喜欢的图案投票,系统就会“繁殖”出更多类似的模式。直到今天它仍在运行。访问 electricsheep.org,你现在就能看到它的演化过程。
在这一时期,“生成艺术”这一概念逐渐普及。艺术家通过编写代码来设定规则和参数,再由算法在这些约束中自由生成作品。2001 年,专为艺术家打造的编程语言 Processing 问世,大大降低了创作门槛,让更多人能够参与其中。
但问题在于:在大多数人看来,这些作品并不算“AI”。它们确实是很酷的数字艺术项目,却谈不上智能——它们并不知道自己在创作什么,只是在按照既定规则运行,不管这些规则有多复杂。
这一切即将改变。
深度学习彻底改变了一切(2012–2015)
2010年代初,发生了一次根本性的转变。三股力量在此交汇:
首先,GPU(图形处理器)的算力提升到了足以训练超大规模神经网络的水平。颇具讽刺意味的是,最初为游戏而设计的芯片,反而推动了 AI 的重大突破。
其次,大规模数据集开始出现。2009 年推出的 ImageNet 收录了数百万张带标注的图像。神经网络终于拥有了足够的训练样本,能够真正学会并捕捉图像中的规律。
第三,深度学习算法迎来了质的飞跃。2012 年,深度学习模型在图像识别基准测试(以 ImageNet 为代表)上取得突破性成绩,彻底碾压了传统计算机视觉方法。这一里程碑清楚地表明:神经网络已经能够在大规模数据上学习视觉模式。研究者逐渐意识到,只要把神经网络做得足够“深”(层数更多),提供足够的数据和算力,它们就会展现出令人惊讶的“智能”行为。
在艺术领域,其影响极其深远。
Deep Dream 的关键时刻(2015)
2015 年 6 月,谷歌工程师 Alexander Mordvintsev 发布了一项看起来有点“怪”的成果。当时他在研究如何把神经网络识别物体的过程可视化。他提出了一个有趣的想法:如果一个网络被训练来识别“狗”,那反过来会发生什么?如果让它不断强化图像中所有看起来像“狗”的模式,会得到怎样的结果?
效果令人目眩。迷幻,甚至带着致幻感。把一张云朵照片喂给网络,它会在云层中到处“看见”狗脸、眼睛和建筑元素,并将它们不断放大,生成超现实的景观。艺术圈瞬间沸腾。
Google 将其命名为 DeepDream(官方称为“Inceptionism”)。短短几周内,艺术家们就开始创作并展示大量 DeepDream 作品。它迅速发展成一种独立的美学风格——画面中充满眼睛、旋转的有机纹理,极具辨识度。直到今天,你依然可以一眼认出一张 DeepDream 风格的图像。
它在文化层面的重要性,不只是画面本身,而是一种认知上的冲击:原来这就是神经网络“看”世界的方式。它看到的并不是我们眼中的现实,而是模式、关联和统计关系。当这些被可视化出来时,就像一场发烧般的梦境。
它怪得离谱,但人们却爱上了它。
风格迁移:神经网络成为艺术家(2015–2016)
差不多在同一时期,研究人员发现了如何用神经网络实现“风格迁移”:把一张图片的艺术风格,应用到另一张图片上。想把你的照片变成梵高《星夜》的画风?几秒钟就能完成。
尽管 Gatys 等人在 2015 年发表的技术论文晦涩难懂,但基于该方法的应用很快遍地开花。2016 年,Prisma 一夜爆红——从那一刻起,只要有一部智能手机,任何人都能生成看起来“像大师画作一样”的艺术作品。
批评者认为这并不是真正的创作新艺术,而只是算法层面的模仿。但它清楚地证明了一点:神经网络已经能够理解艺术风格,并将其成功复现。这在当时是全新的突破。
GAN 生成对抗网络:实现突破的关键技术(2014–2020)
[背景:1973–2025 年 AI 艺术史:从 AARON 到 GAN、Midjourney 与扩散模型的发展时间线] [参考术语:AI 绘画、AI 作画、AI 艺术、AI 艺术史、AI 绘画发展史、AI 艺术时间线、1973–2025 AI 艺术、AARON 计算机艺术、生成艺术、算法艺术、图像生成 AI、文生图、文字生成图片、扩散模型、Diffusion 扩散模型、GAN 生成对抗网络、Midjourney、AI 绘画教程、用 AI 生成艺术作品、佳士得 AI 画作拍卖、《埃德蒙·德·贝拉米肖像》]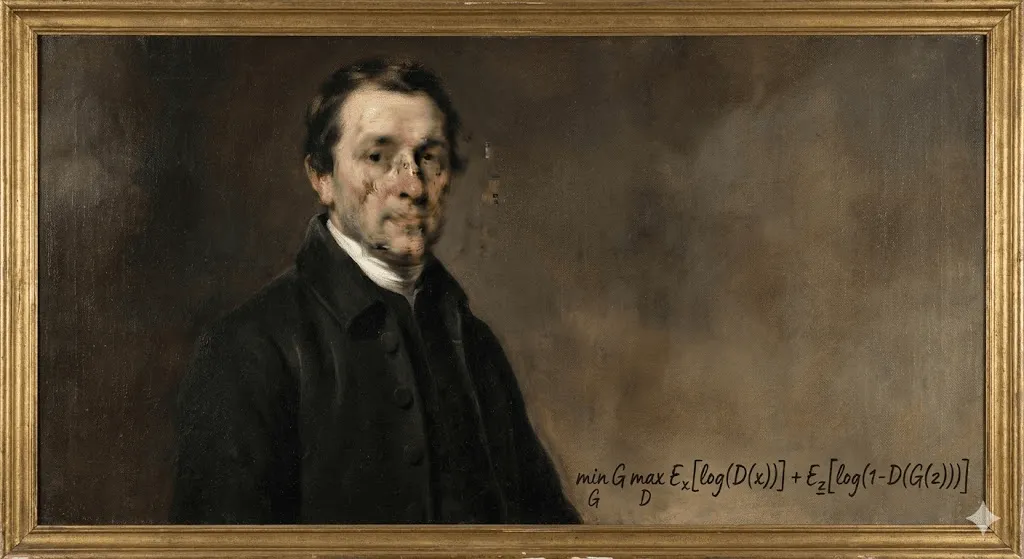
对艺术家来说,GAN 的意义在于:它让“风格”可以从数据中被学习,你无需为每一条规则手工编码,也能探索一个完整的视觉宇宙。
GAN 的工作原理(不涉及数学)
2014 年,时任蒙特利尔大学博士生的 Ian Goodfellow 在一篇论文中首次提出了生成对抗网络(GAN),这篇论文随后成为机器学习领域被引用次数最高的研究之一。深度学习奠基人之一 Yann LeCun 更是评价 GAN 为“过去十年里机器学习领域最有意思的想法”。
核心概念是:想象两个神经网络相互博弈。
网络 1(生成器): 负责生成看起来“以假乱真”的图像。
网络 2(判别器): 负责区分真实图像与伪造图像。
一开始,生成器只会输出杂乱的随机噪声,效果惨不忍睹,判别器一眼就能识破。但巧妙之处在于:生成器会从失败中学习,不断调整策略去“欺骗”判别器;而判别器也会随之变得更精明。就这样,双方你来我往、反复博弈,经历成千上万次迭代,生成效果逐步逼近真实。
最终,生成器会变得足够强大,连判别器也无法稳定地区分真假。到那时,这个神经网络就能从零开始生成以假乱真的图像。
突破性进展:GANs 不再需要为每一种可能的输出都依赖人工标注的训练数据。它们学习训练内容背后的统计分布——无论是人脸、风景还是任何题材——并能生成几乎无限的变化。
从怪异人脸到以假乱真的艺术(2015–2018)
早期的 GAN 作品嘛……只能说相当“实验性”。如果你还记得 2015 年前后那些扭曲诡异、让人直犯恐怖谷的 AI 生成人脸——没错,那就是早期的 GAN。研究人员最初只是把它们当作概念验证分享出来,结果很快就在网上变成了表情包级的存在。
但技术进步的速度远超想象。到 2017 年,NVIDIA 推出的 Progressive GAN 已能生成 1024×1024 分辨率的人脸图像,逼真到几乎无法与真实照片区分。2018 年,StyleGAN 再次突破,不仅将清晰度推向新高度,还首次让创作者能够精细控制图像的不同特征。
艺术家们开始大胆实验。德国艺术家 Mario Klingemann 创作了装置作品《Memories of Passersby I》(2018),由两块屏幕组成,持续生成源源不断的人物肖像。画面像记忆一样缓缓流过,永不重复。这件作品最终在苏富比以 4 万英镑成交。
Helena Sarin 选择了一条不同的路径:她用自己的手绘作品而非照片来训练 GANs。这样既能充分利用 AI 的生成能力,又能保持对艺术创作的掌控。她的 “AI Candy Store” 系列拥有一眼可辨的 AI 气质,同时又深深融入了她的个人风格。
Robbie Barrat 当时还是一名高中生,他用古典艺术作品训练 GAN,并将代码开源发布在 GitHub 上。(后来,Obvious 正是使用了这套代码在佳士得进行拍卖,由此引发了关于署名权与艺术创作归属的广泛争议。)
The Next Rembrandt(下一个伦勃朗,2016)
在 Obvious 引发拍卖热潮之前,2016 年就出现了 “The Next Rembrandt” 项目——这是由 ING 银行联合多家荷兰机构发起的一次营销实验。他们对伦勃朗的 346 幅画作进行扫描,用算法学习其艺术风格,最终生成了一幅“全新的”伦勃朗肖像。
它在技术上并非真正的 GAN,但理念非常接近:AI 是否能够以特定艺术家的风格进行创作?这一项目引发了大量媒体关注。评论界一方面肯定了其技术突破,另一方面也质疑这究竟是艺术创作,还是仅仅高度精巧的模仿拼贴。
它也抛出了至今仍在争论的问题:用某位艺术家的作品来训练模型,是一种致敬,还是算法层面的挪用?灵感的边界,究竟在哪里演变成了剽窃?
爆发期:AI 艺术走向主流(2022–至今)
CLIP:让 AI 同时理解文字与图像(2021)
下一次重大突破来自 OpenAI,于 2021 年 1 月发布:CLIP(Contrastive Language–Image Pre-training,对比语言-图像预训练)。技术原理相当复杂,但带来的影响却非常直观:CLIP 让 AI 真正学会了理解文字与图像之间的对应关系。
早期系统依赖人工标注的数据,比如“这是猫”“这是狗”。而 CLIP 从互联网上抓取的 4 亿组图像-文本配对中学习,理解哪些词语通常对应哪些视觉特征。由此,它构建了一个文本与图像可以相互对照、比较的共享“空间”。
为什么这一步如此重要:当 CLIP 与生成模型结合在一起,图像就可以直接从文字描述中生成。只需输入“一个骑着马的宇航员”,系统就能理解并生成相应的画面。
艺术家很快把 CLIP 接入到自己的创作流程中。通过与 GAN 或其他生成模型结合,他们可以用语言来引导图像生成。过程并不算顺滑,但确实可行。
2022 年的革命:DALL E 2、Midjourney、Stable Diffusion

随后,2022 年到来,一切在这一刻骤然改写。
DALL E 2(OpenAI,2022 年 4 月)将 CLIP 与扩散模型相结合(稍后会进一步介绍),实现了从文本生成高质量、连贯一致的图像。早期访问仅向部分艺术家和研究人员开放,等候名单迅速膨胀至超过一百万人。OpenAI 分享的图像创意惊艳、画面统一,且常常美不胜收。
Midjourney(Midjourney Inc., 2022 年 7 月)走的是另一条路线:以社区为核心,基于 Discord 运作,专注于审美与视觉表现。它很快形成了极具辨识度的风格——绘画感强烈、戏剧化、充满奇幻色彩,迅速吸引了大量艺术创作者涌入。Midjourney 的 Discord 服务器也随之成为当时互联网上最活跃的创意社区之一。
Stable Diffusion(Stability AI,2022 年 8 月)真正改变了 AI 绘画的可及性。相比之下,DALL·E 2 仅限网页端且采用受控访问,Midjourney 则需要订阅;而 Stable Diffusion 是开源的,任何人都可以下载、本地运行,甚至进行二次修改。
短短数月内,一个完整的生态迅速成形:网页版工具、移动端应用、Photoshop 插件,以及数百个针对特定风格训练的定制模型接连涌现。这种爆发式增长,前所未有。
到 2022 年末,社交媒体几乎被 AI 艺术刷屏。“提示词工程”成了一项新技能,人们不断分享如何写出更好提示词的经验。同时,争论也从未停歇——有人认为这是艺术的民主化,有人则担心它正在摧毁艺术本身。
扩散模型:魔法背后的核心技术
那什么是扩散模型?它其实源自物理学,灵感来自粒子在介质中扩散的过程。
训练过程:
- 从一张真实图像开始
- 逐步向图像中加入噪声,直到变成完全随机的静态噪点(正向扩散)
- 训练神经网络反向还原这一过程,逐步去除噪声,重建图像(反向扩散)
生成过程:从一张纯噪声图像开始,通过反向扩散逐步去噪,最终生成一幅完整、连贯的图像。文本条件(通过 CLIP 实现)负责引导图像的内容与风格,决定最终“生成什么样的画面”。
为什么在这个应用场景中,扩散模型胜过 GAN:训练更稳定、上手更简单,而且对文本提示的理解和还原能力更强。GAN 依然在部分领域发挥作用,但在 2022 年那波爆发式增长中,真正占据主导地位的是扩散模型。
技术补充:关键论文是 Ho 等人在 2020 年提出的《Denoising Diffusion Probabilistic Models》,更早的 Sohl-Dickstein 等人(2015)已经为此奠定了基础。如果你想真正搞懂扩散模型,这些论文是很好的起点——但要有心理准备,数学推导相当硬核。
数据一览
- 到 2023 年初,这些工具的用户规模已达数百万,AI 生成的图像开始在各大社交平台迅速铺开。
- DALL E:300 万以上用户(等待名单已清空)
- Stable Diffusion:难以准确统计(开源、分布式),但 GitHub 数据显示用户规模达数百万
人们生成了数以亿计的 AI 图像。提供 AI 艺术服务的公司迅速涌现,形成了一整条新兴产业。素材图库平台也忙着摸索并制定相关政策。与此同时,传统艺术家不安地看着“AI 艺术家”成为一种正式的职业称谓。
AI艺术的另一面:学术应用
当大众的目光都聚焦在文生图工具上时,研究者们早已悄然将 AI 引入艺术史研究,掀起了一场深层次的变革。这一支线在 AI 艺术史中常被忽视,却可能在学术层面更具分量与影响力。
用于作品归属鉴定与分析的计算机视觉
艺术史学家一直为作品的归属与作者认定而困扰。如今,神经网络正开始提供新的解决方案。
罗格斯大学艺术与 AI 实验室(Rutgers Art & AI Lab)(由 Ahmed Elgammal 领导)开发了一系列系统,可分析笔触、构图元素和风格特征,用于识别艺术家身份或检测艺术赝品。2017 年,在受控测试环境中,这些系统对未署名作品的作者识别准确率超过 90%。
失传作品的重建:通过对艺术家已知作品进行训练,神经网络可以生成对失传或受损作品的合理推演版本。最著名的案例是:利用 AI 对伦勃朗的《夜巡》进行外推重建——这幅作品在 1715 年被裁切受损,AI 推测并呈现了被裁掉部分可能的原貌。(当然,艺术史学界对其准确性仍有争议,这是一种基于数据的推断,而非真正意义上的“复原”。)
赫库兰尼姆卷轴:2023 年,计算机科学家利用机器学习技术,成功从公元 79 年维苏威火山喷发中被炭化的古代卷轴中读取文字。这些卷轴极其脆弱,无法展开,但通过 CT 扫描结合训练好的神经网络,研究人员得以识别其中的墨迹模式。这意味着,借助 AI,人类在时隔 2000 年后首次能够重新阅读这些古老文本。(来源:Nature,2023)
博物馆与 AI
各大机构也以令人惊叹的方式尝试探索和运用 AI:
大都会艺术博物馆(The Met)曾尝试用 AI 驱动的藏品可视化,将大规模博物馆档案映射到一个“潜在空间(latent space)”,从而发现藏品之间意想不到的关联。:这是大都会艺术博物馆、MIT 与艺术家 Refik Anadol 的合作项目。他们使用神经网络对 The Met 全部藏品(超过 37.5 万件艺术品)进行训练,并将不同类型藏品之间的“潜在空间”——也就是概念层面的中间地带——进行可视化呈现。结果揭示了许多出乎意料的联系:例如,一件古代波斯水壶与一件 19 世纪花瓶,可能在概念上非常接近,而这种关联是人类策展人此前从未察觉到的。
MoMA 的 AI 艺术实验:Refik Anadol 的《Unsupervised》(2022–2023)基于对 MoMA 馆藏数据的机器学习训练,在博物馆大厅生成流动、梦境般的影像投射。艺术界对此评价两极:有人认为只是噱头,也有人将其视为重新体验博物馆档案的一种全新方式。
慕尼黑大学(LMU)的透明 AI 项目: 由 Hubertus Kohle 教授领导,该研究致力于开发可解释的艺术史 AI 工具,能够清楚说明其推理过程。传统神经网络常被视为“黑箱”——你得到结论,却不知道原因。该项目让 AI 的决策过程变得透明,这对学术界的认可至关重要。研究团队正在训练模型,识别艺术作品之间的视觉相似性,并解释其结论所依据的具体特征。
这些应用并不直接生成新的艺术作品,却正在改变我们研究艺术史的方式。这种影响或许比任何一张生成的图像都更为长久。
争议焦点:版权、伦理与创造力的未来

争议在这里迅速升温。技术成就令人惊叹,但伦理层面的影响却……相当复杂。
版权之争
核心争议在于:AI 艺术模型的训练数据来自互联网上抓取的数十亿张图片,其中大量受版权保护。创作者并未被征求授权,也没有获得任何报酬。而如今,基于他们作品训练的系统,却能在几秒钟内生成“某某艺术家风格”的图像。
已提起的主要诉讼:
Getty Images vs. Stability AI(2023年1月):Getty 指控 Stability 在训练 Stable Diffusion 时抓取并使用了数百万张其图库图片。他们提供的证据显示,一些生成的图像中仍残留着部分 Getty 水印,来源清晰可见。
艺术家集体诉讼 Midjourney、Stable Diffusion、DeviantArt(2023 年 1 月):由艺术家 Sarah Andersen、Kelly McKernan 和 Karla Ortiz 发起,指控相关平台存在大规模版权侵权行为。截至 2024 年底,该案件仍在审理中,法律界对最终判决走向看法不一。
法律上的核心争议在于:用受版权保护的图像来训练模型,究竟属于合理使用(就像学生通过学习现有艺术来提升创作能力),还是构成侵权(未经许可将他人作品用于商业目的)?
法院尚未作出裁决。这一结果将决定整个行业的走向。
艺术家的回应:反击
艺术家并没有坐等法院裁决,而是主动开发技术层面的反制手段。
Glaze(芝加哥大学,2023):一种软件,通过人眼几乎察觉不到的方式微调数字艺术作品,却能对 AI 训练产生“投毒”效果。模型一旦使用经过 Glaze 处理的图像进行训练,生成结果就会出现明显失真。它更像是一种主动式水印——不是用来标识作品,而是用来干扰和破坏训练。
Nightshade(亦来自芝加哥大学,2023):相比 Glaze 更为激进。它不仅仅是保护被 Nightshade 处理过的图像,而是会主动削弱模型的整体性能。只要上传足够多标注为“dog”但实际展示的是猫的 Nightshade 图像,模型最终就会对“狗到底长什么样”产生混淆。
这些工具一直备受争议。AI 研究者认为它们是有害的破坏行为,而艺术家则将其视为自我防卫。双方都有各自的道理。
“Do Not Train(禁止训练)”提案: 艺术家与相关倡议者提出,通过在作品中加入元数据标签,明确标注“禁止用于 AI 训练”。部分平台(如 DeviantArt、Shutterstock)已上线了退出(opt-out)机制。然而在实际执行层面,这类措施约束力有限。AI 公司完全可以选择忽略这些标签,而现实中,确实有不少这样做。
创造力之争
比版权争议更深层的,是一个哲学问题:AI 生成的作品,究竟算不算艺术?
反对意见:
- 缺乏人类的主观意图与情感深度
- 主要通过重组既有作品生成,而非真正意义上的原创
- 不需要专业技能——任何人都能输入提示词
- 削弱了艺术的核心价值:人类的创造力与创作过程中的挣扎
支持这一说法的论点:
- 工具并不会让艺术失去价值(就像相机的出现并没有终结绘画)
- 提示词工程与作品筛选本身就是一种技能
- 人类主导并引导 AI,在过程中做出关键的创作决策
- 开启了此前无法实现的全新表达形式
我的观点:这其实是个跑偏的讨论。就像在 1850 年争论“摄影算不算艺术”一样。AI 能不能创作艺术,事实已经给出了答案——我们已经看到了。真正值得思考的是:人类创造力与机器创造力之间,我们希望建立怎样的关系?谁会从中受益?哪些东西会消失?又会带来什么新的可能?
岗位替代的现实
这不是理论探讨,现实中已经有人因此失去了工作。
概念艺术协会在 2023 年的一项调查发现:
- 73% 的概念艺术家表示工作机会正在减少
- 62% 的人曾因 AI 而失去自由职业项目
- 入门级岗位消失速度最快
越来越多的公司开始用 AI 来做前期概念设计、分镜稿和背景设定——而这些,正是过去通常交给初级艺术家完成的工作。有人辩称,这和当年数字工具取代传统技法并无本质区别。但不同的是,变化的速度前所未有,受到冲击的艺术家感到愤怒,也完全可以理解。
与此同时,一些全新的角色正在出现:AI艺术总监、提示词工程师,以及擅长人机协作流程的AI混合型创作者。这些新岗位是否能以一比一的比例填补被取代的工作岗位,还有待时间检验。
偏见问题
AI 艺术模型会从训练数据中继承偏见。比如输入“CEO”,生成的往往是白人男性;输入“护士”,多半是女性;而“漂亮的人”,则明显偏向年轻、白人、符合主流审美的面孔。
Google 的 Gemini 曾在 2024 年尝试通过提升历史图像中的多样性来“纠偏”,却因过度修正而引发争议——模型在历史准确性、群体呈现与安全性之间如何取舍,成为焦点。比如生成 18 世纪欧洲贵族时出现明显失真,暴露了负责任地调校这些系统的难度。随后 Google 道歉并下线了该功能,这一事件再次说明,在历史真实与多元呈现之间取得平衡并不容易。
偏见并不只体现在人口维度上。AI 艺术也会偏向某些审美——精致、商业化、符合主流审美的“好看”。相比之下,实验性、前卫、甚至刻意“不好看”的作品在输出中更少见,因为它们在训练数据中本就更稀缺,也更少被“奖励”。从这个意义上说,AI 在技术上可能激进,但在艺术上却往往相对保守。
现状(2024–2025)
当前格局
截至 2024 年底 / 2025 年初,AI 艺术领域已逐渐走向成熟,但整体格局依然充满变动与不确定性:
DALL E 3(集成于 ChatGPT Plus)在提示词理解能力上实现了质的飞跃。你可以直接用对话方式描述想要的画面,AI 对细节和语境的理解明显更精准。
Midjourney V6 在审美质量上再次拉高了天花板,文字渲染能力明显提升(虽然仍未做到完全准确),风格控制也更加灵活可控。
Stable Diffusion XL 及其后续版本仍在不断进化,开源社区持续打造各类专用模型,覆盖从动漫、写实到特定艺术风格的创作需求。
Adobe Firefly 代表了“负责任 AI”的路线,仅使用 Adobe Stock 图片和公有领域内容进行训练,并内置商业授权机制。相比 Stable Diffusion,能力略逊一筹,但在商业使用上更具法律安全性。
视频生成:下一片前沿
文生图只是起点。2024 年,AI 视频生成迎来了重大突破:
Runway Gen 2 和 Pika 已能根据文字或图片生成短视频片段。整体质量仍不稳定:物体有时会不自然地变形,物理效果也会“出戏”,但几乎每个月都在明显进步。
OpenAI 的 Sora(2024 年 2 月发布,限量开放)展示了最长可达一分钟、具备高度写实与连贯性的生成视频能力。演示视频令人震撼,也让不少人感到担忧:在 AI 还能直接从文本生成逼真视频之前,深度伪造就已经成为现实问题。
3D 及未来
AI 艺术正不断突破二维图像的边界:
Point E and Shap E(OpenAI)可根据文本提示生成 3D 模型。当前效果仍有局限,但发展趋势已经十分清晰。
NeRF(Neural Radiance Fields,神经辐射场)技术可以从二维图像中重建三维场景,对影视制作、游戏开发以及建筑可视化等领域都产生了深远影响。
音乐、文本与多模态
到 2024 年,AI 音乐生成(Suno、Udio)已经达到了“相当不错”的水平。AI 并没有取代音乐人,但正在让功能性背景音乐的制作变得更简单、更高效,也更低成本。
多模态模型(GPT 4 with vision、Gemini)能够理解和分析图像,生成相关文字,并再基于这些文字创作新的图像。文本 AI 与图像 AI 之间的边界正在逐渐模糊。
未来走向:趋势预测与无限可能
近期(2025–2027)
可能:
- 视频生成能力走向成熟,真正进入主流可用阶段
- 角色一致性大幅提升,同一人物可在多张图片中稳定复现
- 在持续的诉讼推动下,版权与法律边界逐渐明朗
- 行业加速洗牌,小型平台被收购或退出市场
- 反对声音加剧,部分平台与客户开始明确禁止使用 AI 艺术
可能性:
- 视频通话或直播中实现实时视频生成
- AI艺术成为专业创意工作流程中的标准工具
- “认证人类创作”艺术作为高端品类兴起
- AI艺术史在重要博物馆举办大型专题展览(不再局限于单件装置)
中期 (2027–2030)
推测但合理:
- 文本、图像、视频、3D 与音频生成在单一模型中实现统一
- 基于个人艺术风格训练的定制化 AI 模型逐渐普及
- 通过头显设备实现 AR/VR 融合,让 AI 艺术进入真实物理空间
- 法律框架逐步建立,对训练数据达成(可能相当复杂的)折中方案
- 诞生全新的、原生于 AI 的艺术流派,而非对前 AI 时代风格的改编
长期视角:关键问题
AI 会超越人类的创造力吗?这个问题本身就问错了——两者本就不是同一回事。
人类艺术家会被淘汰吗?可能性不大。随着 AI 轻松生成的内容大量涌现,市场对“真正具有人类气息”的作品需求,反而可能会增加。
AI生成的艺术作品究竟归谁所有?目前仍在法院中争议不断。按照现行的美国版权法,由于缺乏人类作者,这类作品不享有版权、无人拥有——但这一规则很可能会发生变化。
如何补偿那些其作品被用于训练 AI 的艺术家?这是一个名副其实的“百亿美元难题”。可能的解决方案包括:授权许可费、按使用次数的微支付、以及类似音乐行业的强制许可制度——但目前都尚未实现规模化落地。
是否应该设立“无 AI 区域”?有人认为,某些应用场景(如儿童读物、纪念性作品、法律证据)应当保留给人类创作者;也有人将这种主张斥为卢德主义。相关争论仍在持续。
历史的启示
回顾 50 多年的 AI 艺术发展史,可以看到一些清晰的规律逐渐浮现:
- 工具不断走向大众化。AARON 需要编程能力,GAN 需要机器学习知识,而今天的工具只需要一个 Discord 账号。每一代技术,门槛都在降低。
- 最初的热潮往往高于现实。每一次突破都会伴随“艺术已死”的宣言。但艺术从未消失,只是在不断进化。
- 法律与伦理框架总是落后于技术。我们至今仍在讨论三年前落地的技术所引发的版权问题。法律推进缓慢,而技术不会停下脚步。
- 对职业被取代的担忧并非空穴来风,但也并不完整。确实,有些岗位会消失,但新的岗位也会出现。转型期充满阵痛,尤其是身处其中的人。
- 艺术会继续存在。摄影没有杀死绘画,数字工具没有消灭传统媒介,AI 也不会终结人类创造力。但它将改变我们如何创作、为何创作,以及创作什么。
结语:书写下一个篇章
从1973年哈罗德·科恩(Harold Cohen)耐心地进行程序创作,到今天数以百万计的人在几秒钟内生成图像,AI艺术的发展史,本质上是一段关于人类创造力与计算能力关系不断演变的故事。
当下我们面临的问题已不再主要是技术层面的——技术本身已经可用,而且进步飞快。真正的问题在于人本身:
- 如何确保 AI 是在放大人类创造力,而不是取而代之?
- 对于让 AI 得以成立的艺术家作品,我们该如何进行公平回馈与补偿?
- 在这个全新的创作生态中,谁能够参与其中,又是否人人都有机会?
- 创作中有哪些部分,是我们希望始终只属于人类的?
- 在技术快速演进的过程中,如何守护艺术家的职业发展与生计?
这些问题没有简单的答案。它们需要艺术家、技术人员、企业、政策制定者与公众之间的持续对话与协商。AI艺术史尚未写完——我们正身处其中最具决定性的一章。
可以确定的是,忽视 AI 并不会让它消失,假装它没有带来真实挑战也无济于事。真正可行的前进路径,只有主动参与:正视问题、拥抱可能性,并坚持公平与责任。
也许我们一直在问错问题:AI到底算不算“真正的创作”?创造力从来不是非黑即白的能力,它存在于连续的光谱之中,诞生于协作之中,也常常来自意想不到的组合。如果说 AI 艺术走过的前 50 年给了我们什么启示,那就是——创造力比我们想象得更广阔、更奇异。而人类,无论结果好坏,似乎都执意要与之共享。
下一章正在书写之中。欢迎你以更有深度的方式参与其中。